zirui3/zhihu_qa
收藏Hugging Face2023-05-25 更新2024-03-04 收录
下载链接:
https://hf-mirror.com/datasets/zirui3/zhihu_qa
下载链接
链接失效反馈官方服务:
资源简介:
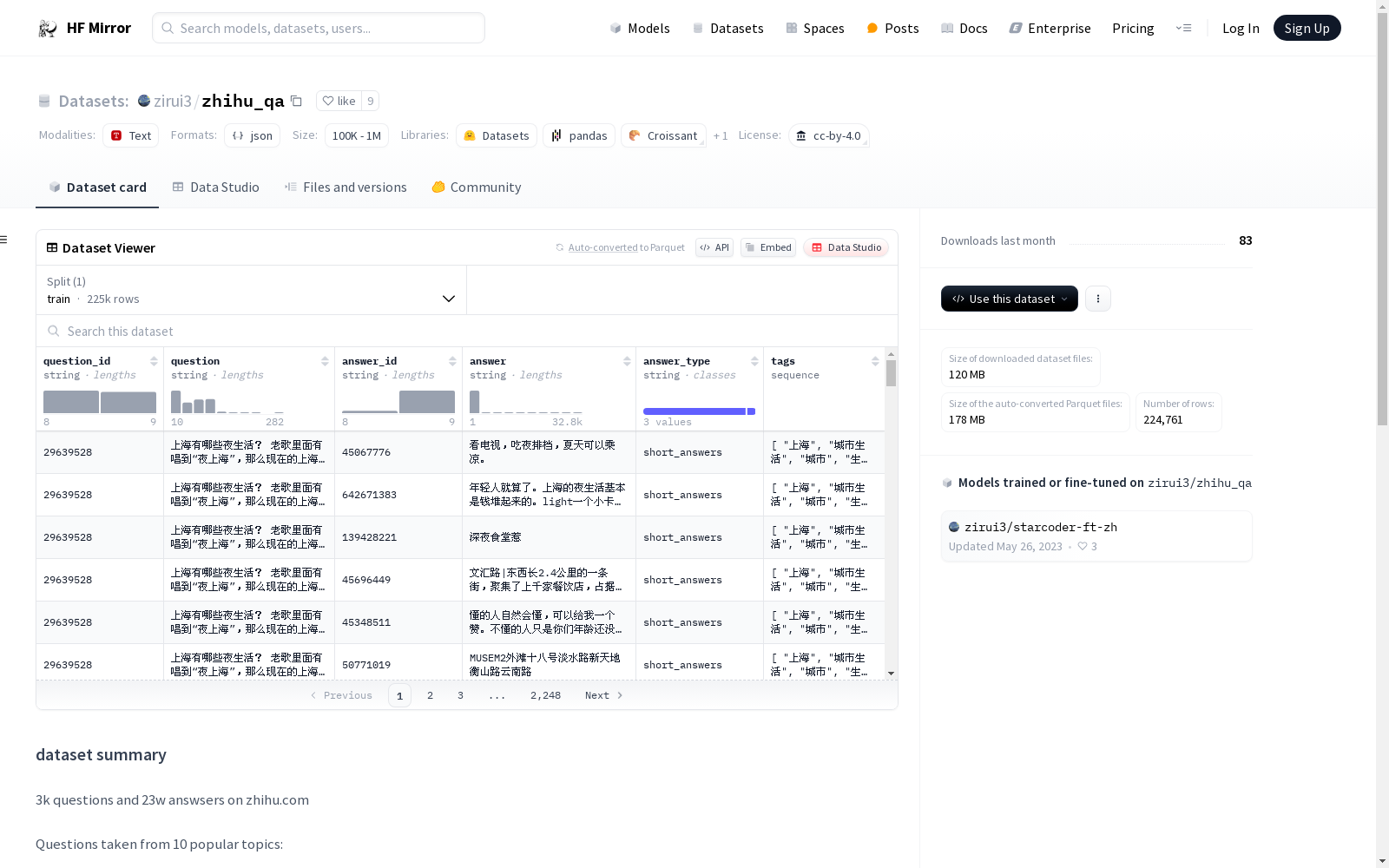
该数据集包含来自知乎的3000个问题和23万个答案,问题涵盖了10个热门话题,包括文化、教育、艺术、大学、互联网、心理、科技、健康、职业发展和生活方式。每个问题都有对应的答案,答案类型为简短回答,并且每个问题都附有相关标签。
This dataset contains 3,000 questions and 230,000 answers sourced from Zhihu. The questions cover 10 popular topics, including culture, education, art, universities, the Internet, psychology, technology, health, career development, and lifestyle. Each question is paired with corresponding concise answers, and each question is accompanied by relevant tags.
提供机构:
zirui3
原始信息汇总
数据集概述
数据集内容
- 包含3000个问题和230000个答案,来源于知乎网站。
- 问题覆盖10个热门话题:
- 文化
- 教育
- 艺术
- 大学
- 互联网
- 心理
- 科技
- 健康
- 职业发展
- 生活方式
数据集示例
json { "question_id": "29639528", "question": "上海有哪些夜生活? 老歌里面有唱到“夜上海”,那么现在的上海到底有哪些丰富的夜生活呢?", "answer_id": "62379612", "answer": "地点:闵行区男子技术学院(也叫MIT)去年夏季学期的一天晚上,心情不好,和同学在校园逛到凌晨一点多。去各个地方买饮料喝,在冰火吃烧烤。郊区自然不像市区这么热闹,但是这么晚了居然还有人。", "answer_type": "short_answers", "tags": [ "上海", "城市生活", "城市", "生活方式", "夜生活" ] }
许可证
- 数据集遵循CC-BY-4.0许可证。
搜集汇总
数据集介绍
构建方式
该数据集的构建采取了对知乎网十大热门话题下的提问与回答进行抓取的方式,涉及文化、教育、艺术等多元化领域,共包含3000个问题和230000个回答。构建过程中,数据集制作者对内容进行了筛选与整理,确保了数据的质量与相关性。
特点
此数据集显著的特点在于其内容的多样性及来源的可靠性。覆盖了知乎网上十个广受欢迎的话题,不仅提供了问题与回答的文本,还包含了问题ID、回答ID、回答类型以及相关标签等元信息,为研究用户行为、内容质量以及话题分布提供了丰富的信息。
使用方法
用户可通过HuggingFace提供的平台接口来访问和下载数据集。使用时,可依据问题ID或回答ID进行数据检索,亦可根据标签进行内容筛选。此外,数据集的开放协议(cc-by-4.0)允许用户在遵守协议的前提下自由使用数据,为学术研究、产品开发等提供了便利。
背景与挑战
背景概述
在信息检索与自然语言处理领域,高质量的问答数据集对于算法模型的训练与评估至关重要。'zirui3/zhihu_qa'数据集,收集自中国知名问答社区知乎,涵盖了文化、教育、艺术等十个热门领域,总计3000个问题和23000个答案,为研究者和工程师提供了丰富的文本资源。该数据集创建于知识共享的背景下,旨在促进学术交流与技术研发,由zirui3维护,其诞生不仅丰富了中文问答数据集的多样性,也为相关领域的研究提供了有力支撑,具有重要的影响力。
当前挑战
尽管该数据集为中文问答系统的研究提供了宝贵的资源,但其面临的挑战也不容忽视。首先,数据集中问题的领域集中性可能导致模型在特定领域之外的表现受限。其次,构建过程中如何确保答案的准确性与相关性是一个难点。此外,由于知乎平台上的内容更新迅速,数据集的时效性维护也是一项持续的挑战。这些挑战对数据集的可用性和研究结果的普遍性提出了更高的要求。
常用场景
经典使用场景
在自然语言处理领域,zirui3/zhihu_qa数据集被广泛运用于构建和评估问答系统。其涵盖了文化、教育、艺术等十个热门领域,提供了真实世界中的问题与答案对,为研究者提供了丰富的文本资源,以训练模型理解和生成自然语言。
解决学术问题
该数据集解决了传统问答系统中缺乏真实语境和多样化主题的问题。它的应用有助于推动自动问答技术向更加智能、精准的方向发展,为学术研究提供了新的视角和可能。此外,该数据集亦有助于提升跨领域语言模型的适应性,增强机器理解人类语言的能力。
衍生相关工作
基于zirui3/zhihu_qa数据集,研究者们已经衍生出一系列相关工作,包括但不限于构建多轮对话系统、情感分析模型以及跨领域信息抽取等。这些工作不仅推动了自然语言处理技术的进步,也为人工智能在各个领域的应用提供了坚实基础。
以上内容由遇见数据集搜集并总结生成


