TTS_merge-linear-replay_ls960-test
收藏Hugging Face2025-05-18 更新2025-05-19 收录
下载链接:
https://huggingface.co/datasets/chiyuanhsiao/TTS_merge-linear-replay_ls960-test
下载链接
链接失效反馈官方服务:
资源简介:
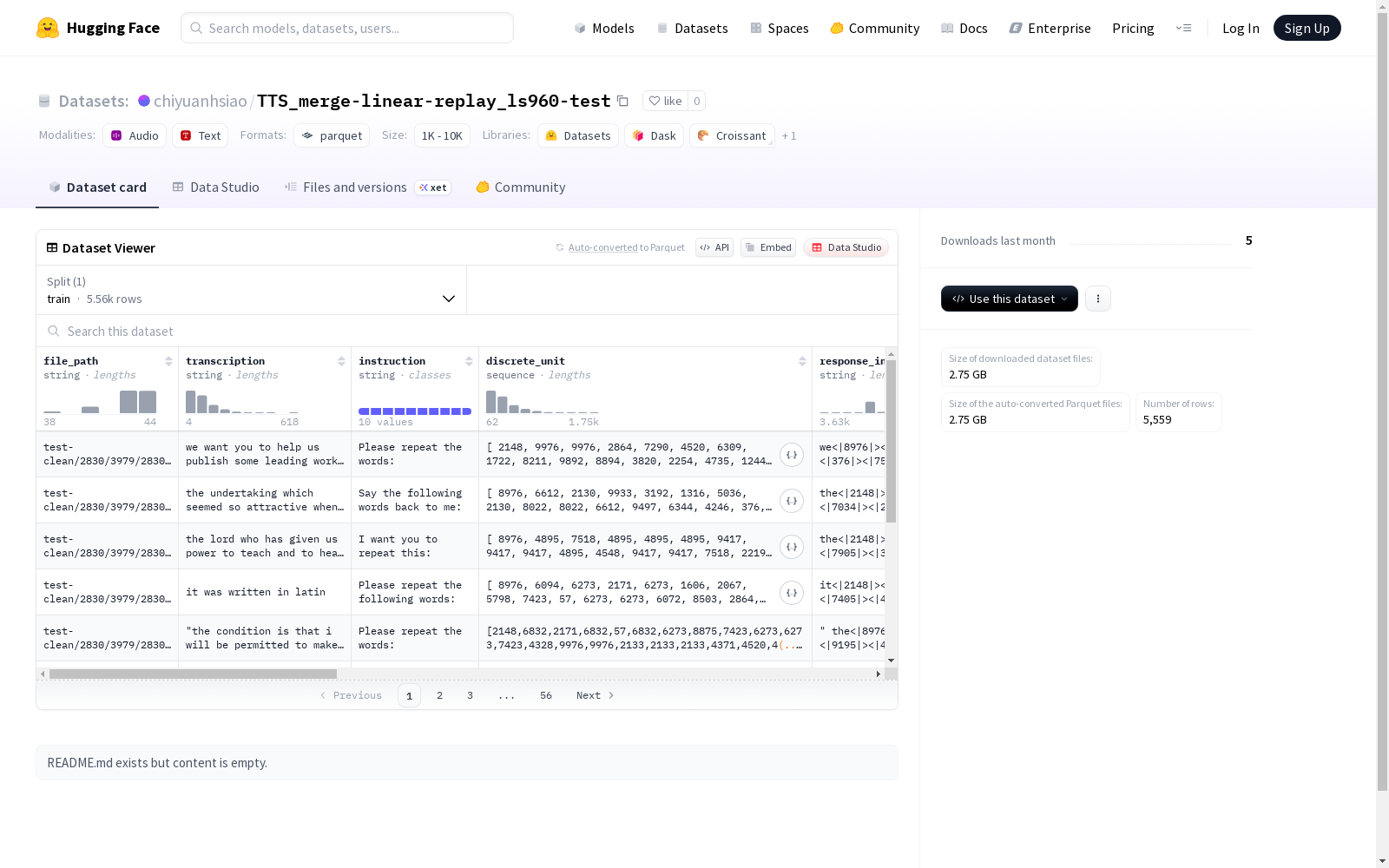
该数据集包含多个字段,其中包括文件路径、转录文本、指令、离散单元的序列、响应交错的文本、响应文本、响应令牌、TTS语音(音频格式)、TTS语音的转录文本、单词错误率(WER)结果、字符错误率(CER)结果、单词错误率(WER)和字符错误率(CER)。数据集分为训练集,共有5559个示例,总大小为2,976,400,118.125字节。数据集还提供了一个默认配置,指定了训练数据文件的路径。
创建时间:
2025-05-16
搜集汇总
数据集介绍
构建方式
在语音合成研究领域,TTS_merge-linear-replay_ls960-test数据集通过多阶段流程精心构建。该数据集以LibriSpeech 960小时测试集为基础语料,采用线性融合与重放技术整合离散单元序列与文本转录。构建过程中同步生成合成语音并标注音素级对齐信息,通过词错误率和字符错误率指标量化语音识别性能,辅以平均主观意见分评估语音质量,形成多模态对齐的语音文本配对数据。
特点
该数据集展现出多维度融合的显著特征,同时包含原始音频路径、文本转录和离散单元序列等传统语音要素,创新性地引入指令引导字段与交错响应文本。其独特之处在于整合了TTS合成语音及其对应转录,配合词错误率、字符错误率及语音质量评分构成完整的评估体系。数据集包含5559个训练样本,每个样本均具备语音生成与识别任务的双重属性,为端到端语音处理研究提供丰富素材。
使用方法
研究人员可基于该数据集开展语音合成与识别联合训练,通过指令字段引导模型生成特定风格的语音输出。离散单元序列可直接用于声学模型预训练,而TTS合成语音与原始转录的对比可用于评估模型鲁棒性。多维度评估指标支持语音质量自动评测系统的开发,交错响应文本则为对话式语音生成任务提供训练基础。数据集采用标准HuggingFace格式加载,便于集成至现代深度学习框架进行多任务学习。
背景与挑战
背景概述
语音合成技术作为人机交互的核心环节,其发展历程始终与数据驱动方法紧密相连。TTS_merge-linear-replay_ls960-test数据集由研究机构在深度学习浪潮中构建,聚焦于探索文本到语音转换中的多模态对齐问题。该数据集通过整合音频波形、离散单元与文本转录等异构特征,旨在解决合成语音自然度与鲁棒性之间的平衡难题,对推动端到端语音合成系统的演进具有重要参考价值。
当前挑战
在语音合成领域,该数据集需应对合成语音与原始语音在韵律特征上的对齐偏差,以及跨语言音素映射的泛化难题。构建过程中面临多源数据时序标注不一致的整合挑战,同时离散单元序列与连续音频信号之间的表征转换易引发信息损失,而高保真音频的存储与计算资源约束进一步增加了数据处理的复杂度。
常用场景
经典使用场景
在语音合成技术领域,该数据集通过整合线性重放机制与多模态特征,为构建端到端语音生成模型提供了标准化实验平台。其核心应用体现在训练文本到语音转换系统,研究人员利用离散单元序列与音频波形数据的对齐关系,优化声学建模的连贯性与自然度。该数据集支持对合成语音的韵律、音质进行量化评估,已成为语音生成任务中模型性能验证的重要基准。
解决学术问题
该数据集有效解决了语音合成研究中训练数据异构性导致的模型泛化能力不足问题。通过提供统一的音素-音频对齐样本与多维度质量评估指标,显著降低了声学模型在跨说话人场景下的适配难度。其包含的字错误率与平均主观评分数据,为量化合成语音的清晰度与自然度建立了可复现的评估体系,推动了语音生成技术从实验室走向实用化阶段。
衍生相关工作
该数据集催生了多项语音合成领域的创新研究,包括基于离散单元的流式语音生成架构与端到端韵律建模方法。知名学术机构在此基础上提出了融合对抗训练的多说话人声学模型,显著提升了跨语言合成质量。后续研究进一步拓展了其在低资源语言适配、情感语音生成等方向的应用边界,形成了完整的技术演进脉络。
以上内容由遇见数据集搜集并总结生成


