NingLab/EcomMMMU
收藏Hugging Face2025-11-13 更新2025-11-15 收录
下载链接:
https://hf-mirror.com/datasets/NingLab/EcomMMMU
下载链接
链接失效反馈官方服务:
资源简介:
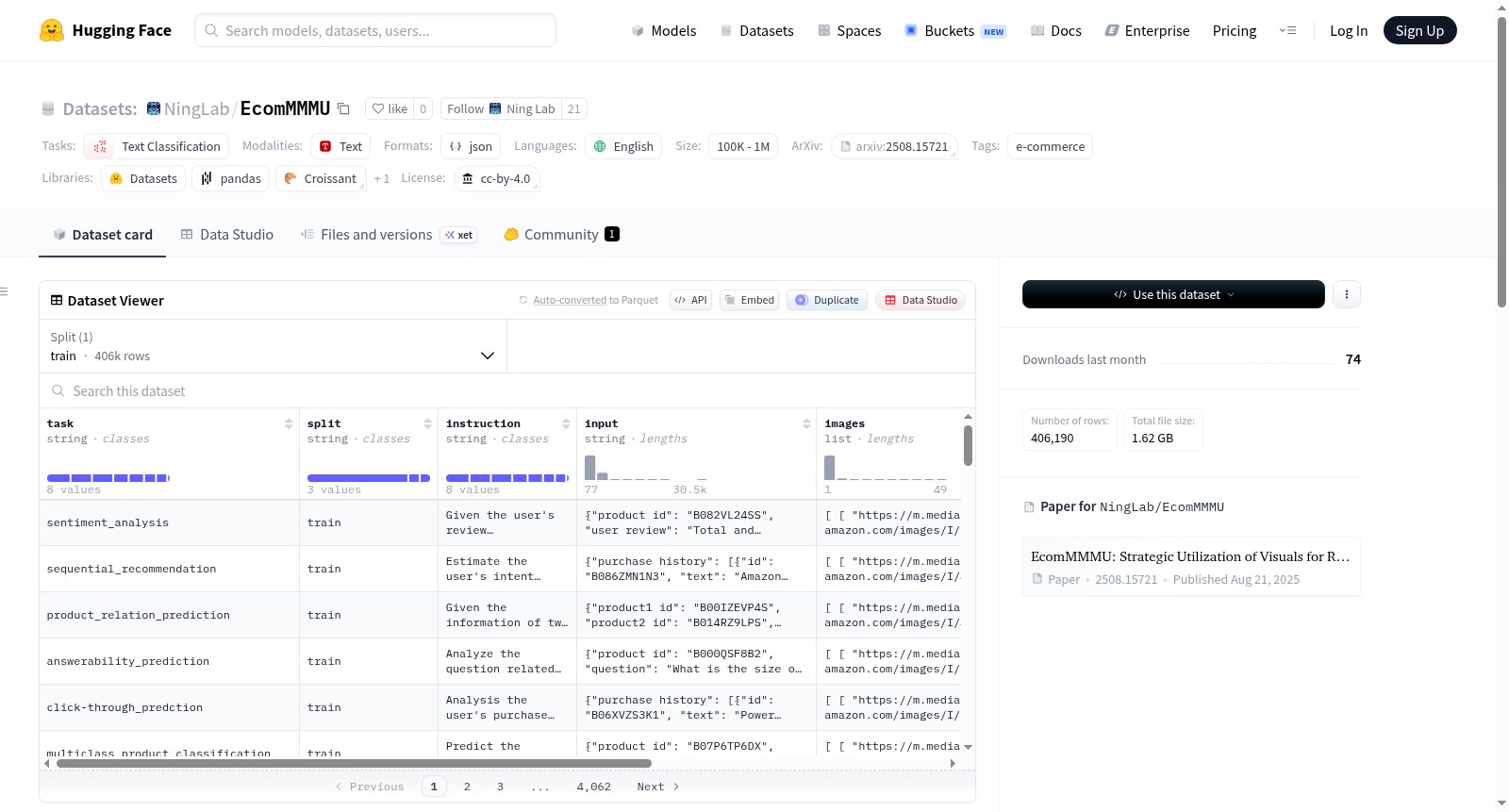
EcomMMMU是一个面向电子商务应用的大规模多模态多任务理解数据集,包含406,190个样本和8,989,510个产品图像,跨越34个产品类别。该数据集旨在评估多模态大型语言模型在真实购物场景中如何有效利用视觉信息,并包含一个专门设计的视觉显著子集,用于测试文本信息不足时视觉信息的重要性。
EcomMMMU is a large-scale multimodal multitask understanding dataset for e-commerce applications, containing 406,190 samples and 8,989,510 product images across 34 product categories. It is designed to evaluate how multimodal large language models effectively utilize visual information in real-world shopping scenarios, and includes a specifically designed vision-salient subset to test the importance of visual information when textual information is insufficient.
提供机构:
NingLab
搜集汇总
数据集介绍
构建方式
在电子商务领域,多模态大语言模型的应用日益广泛,但现有数据集往往未能充分挖掘多张产品图像对模型理解的差异化贡献。为此,研究者构建了EcomMMMU数据集,这是一个大规模多模态多任务理解基准,囊括406,190个样本与8,989,510张产品图像,覆盖34个产品类别。数据集特别设计了视觉显著子集(VSS),聚焦于文本信息不足而视觉信息至关重要的场景,从而系统评估模型对视觉线索的依赖与利用模式。
特点
EcomMMMU的核心特点在于其精细化的视觉信息探究机制。不同于传统数据集将图像同等对待,该数据集明确区分了不同产品图像在理解任务中的贡献度,通过视觉显著子集(VSS)专门测试模型在文本信息匮乏时对视觉信息的依赖程度。这种设计使得研究者能够深入剖析多模态模型在真实购物场景中的视觉推理能力,为提升模型鲁棒性提供了独特视角。
使用方法
使用EcomMMMU数据集极为便捷,研究者可通过HuggingFace的datasets库直接加载。只需运行`from datasets import load_dataset`并执行`load_dataset("NingLab/EcomMMMU")`命令,即可获取完整数据。该数据集以文本分类为主要任务,语言为英文,适用于评估多模态大语言模型在电子商务场景下的表现,尤其适合测试模型在视觉信息主导时的决策能力。
背景与挑战
背景概述
在电子商务领域,多模态大语言模型(MLLMs)的迅猛发展催生了对复杂视觉-文本理解能力的迫切需求。然而,现有数据集往往将产品图像视为同质化信息源,忽视了不同图像在购物决策中的差异化贡献。为此,由NingLab团队于2025年发布的EcomMMMU数据集应运而生,旨在系统评估MLLMs在真实电商场景中如何策略性地利用多幅产品图像。该数据集包含406,190个样本与近900万张图像,横跨34个商品类别,并创新性地引入了视觉显著性子集(VSS),专门针对文本信息不足、必须依赖视觉线索的挑战性场景。这一设计不仅填补了电商多模态评估的空白,更推动了模型在细粒度视觉推理方向的研究进程,对学术界与工业界均具有深远影响。
当前挑战
EcomMMMU所面临的挑战首先源于电商领域固有的复杂性:商品描述常缺失关键视觉细节(如材质、颜色),而多幅图像间的信息冗余与互补关系难以被现有模型有效建模。此外,视觉显著性子集(VSS)的设计进一步考验模型在文本与视觉信息冲突时的决策能力,要求其精准识别何时图像贡献超越文字。在数据集构建过程中,团队需应对海量产品图像的质量参差与标注一致性难题,例如不同来源的图像分辨率、光照条件差异巨大,且需确保34个类别间样本均衡。同时,如何界定“视觉显著”场景以避免主观偏差,也是一大技术挑战,这直接影响了评估的客观性与泛化能力。
常用场景
经典使用场景
在电子商务与多模态学习交叉领域,EcomMMMU数据集被设计为评估多模态大语言模型(MLLMs)在真实购物场景中理解视觉信息能力的基准。其经典使用场景聚焦于商品多模态理解任务,涵盖来自34个产品类别的逾40万样本及近900万张商品图像,系统考察模型在文本与图像协同作用下的推理表现。特别地,该数据集引入了视觉显著性子集(VSS),专门测试当文本描述不足以支撑决策时,模型依赖视觉线索进行精准判断的能力,从而揭示不同图像在商品理解中的差异化贡献。
实际应用
在实际电商应用中,EcomMMMU支撑了智能商品检索、个性化推荐与自动问答等关键环节的模型优化。例如,当消费者上传模糊描述或仅提供图片时,基于该数据集训练的模型能够更准确地识别产品属性与类别,减少对冗长文本的依赖。此外,在商品详情页自动生成、跨模态搜索排序以及虚假信息检测等任务中,该数据集帮助模型学会区分主图、细节图与场景图的不同作用,从而提升购物体验的流畅性与决策效率。
衍生相关工作
EcomMMMU的发布催生了多项围绕多模态电商模型的衍生研究。基于其视觉显著性子集,后续工作探索了图像注意力机制与文本-图像对齐策略的改进,例如提出动态图像选择模块以自适应调整不同图片的权重。部分研究还借鉴其分类体系,构建了涵盖更细粒度商品属性的多模态指令微调数据集,或将其作为评测基准验证新型视觉-语言预训练框架在电商领域的迁移效果。这些工作共同推动了多模态学习从通用场景向垂直电商领域的深化。
以上内容由遇见数据集搜集并总结生成


