xlam-function-calling-60k
收藏魔搭社区2026-05-23 更新2024-06-22 收录
下载链接:
https://modelscope.cn/datasets/LLM-Research/xlam-function-calling-60k
下载链接
链接失效反馈官方服务:
资源简介:
# APIGen Function-Calling Datasets
[Paper](https://arxiv.org/abs/2406.18518) | [Website](https://apigen-pipeline.github.io/) | [Models](https://huggingface.co/collections/Salesforce/xlam-models-65f00e2a0a63bbcd1c2dade4)
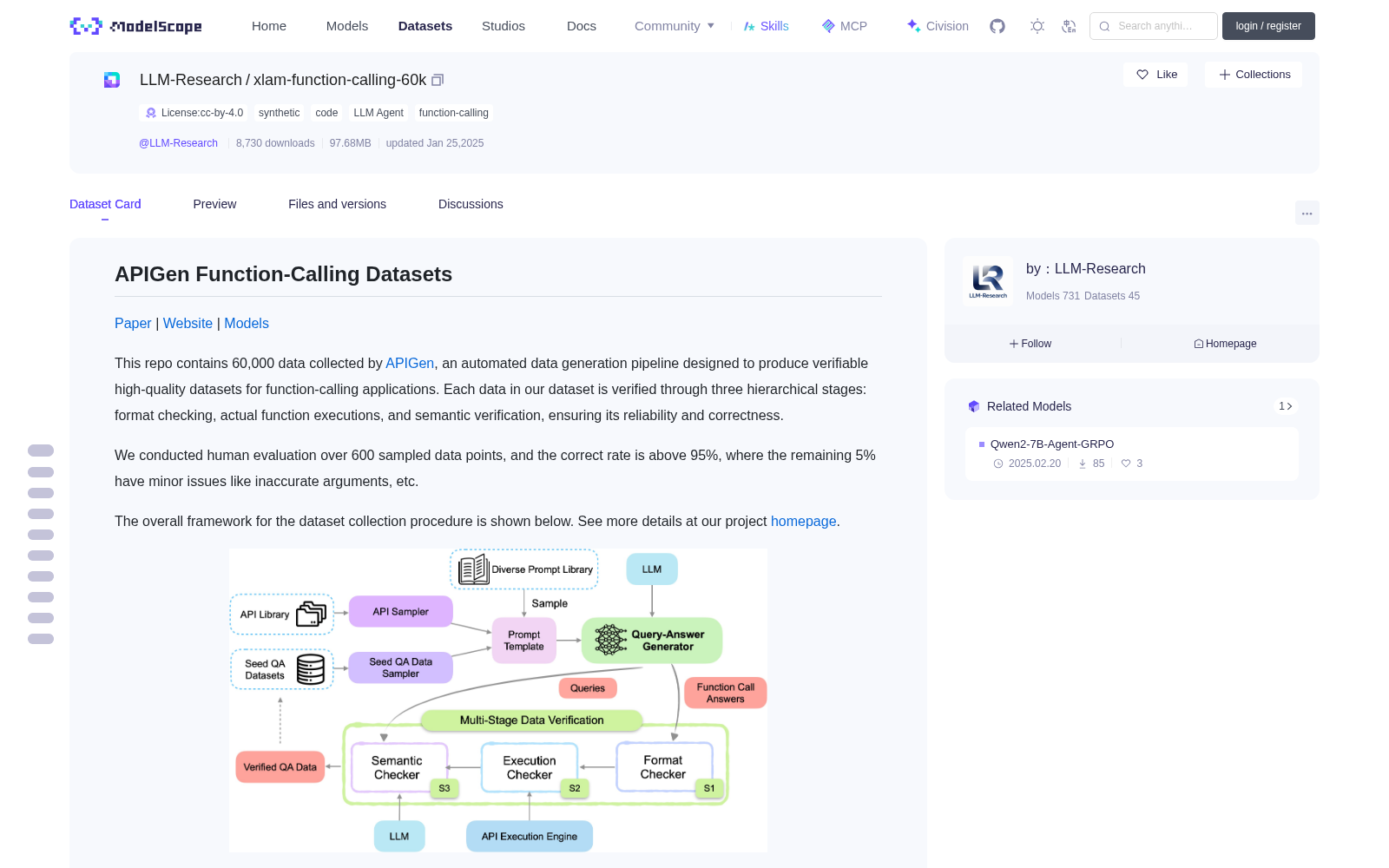
This repo contains 60,000 data collected by [APIGen](https://apigen-pipeline.github.io/), an automated data generation pipeline designed to produce verifiable high-quality datasets for function-calling applications. Each data in our dataset is verified through three hierarchical stages: format checking, actual function executions, and semantic verification, ensuring its reliability and correctness.
We conducted human evaluation over 600 sampled data points, and the correct rate is above 95%, where the remaining 5% have minor issues like inaccurate arguments, etc.
The overall framework for the dataset collection procedure is shown below. See more details at our project [homepage](https://apigen-pipeline.github.io/).
<div style="text-align: center;">
<img src="figures/overview.jpg" alt="overview" width="620" style="margin: auto;">
</div>
## 🎉 News
- **[July 2024]**: We are thrilled to announce the release of our two function-calling models: [xLAM-1b-fc-r](https://huggingface.co/Salesforce/xLAM-1b-fc-r) and [xLAM-7b-fc-r](https://huggingface.co/Salesforce/xLAM-7b-fc-r). These models have achieved impressive rankings, placing #3 and #25 on the [Berkeley Function-Calling Leaderboard](https://gorilla.cs.berkeley.edu/leaderboard.html#leaderboard), outperforming many significantly larger models. We also provide their GGUF files, which can be readily deployed on personal devices. Stay tuned for more powerful models coming soon.
- **[July 2024]**: We've addressed issues mentioned in discussion [#8](https://huggingface.co/datasets/Salesforce/xlam-function-calling-60k/discussions/8) by regenerating 1,896 affected data points. Thank you to the community for identifying these issues and helping us further improve the quality of our dataset!
- **[June 2024]**: We are pleased to see our work featured by [VentureBeat](https://venturebeat.com/ai/salesforce-proves-less-is-more-xlam-1b-tiny-giant-beats-bigger-ai-models/) and [新智元](https://mp.weixin.qq.com/s/B3gyaGwzlQaUXyI8n7Rguw).
## What is a Function-Calling Agent?
Function-calling agents are capable of executing functional API calls from plain language instructions. Imagine asking for today’s weather in Palo Alto. In response, a function-calling agent swiftly interprets this request, taps into the appropriate API—for example, `get_weather("Palo Alto", "today")`—and fetches real-time weather data. This advanced capability significantly broadens the practical applications of LLMs, allowing them to seamlessly interact with various digital platforms, from social media to financial services, enhancing our digital experiences in unprecedented ways.
<div style="text-align: center;">
<img src="figures/function-call-overview.png" alt="function-call" width="620" style="margin: auto;">
</div>
## Datasets
The datasets were generated by [DeepSeek-V2-Chat](https://github.com/deepseek-ai/DeepSeek-V2) and [Mixtral-8x22B-Inst](https://huggingface.co/mistral-community/Mixtral-8x22B-v0.1). We leverage APIGen and collect 3,673 executable APIs across 21 different categories to generate diverse function-calling datasets in a scalable and structured manner.
The first `33,659` data entries were generated by DeepSeek, i.e., from id `0` to id `33658`. The remaining ones were generated by Mixtral.
<div style="text-align: center;">
<img src="figures/dataset_pie_chart.png" alt="Pie chart showing dataset distribution" width="380" style="margin: auto;">
</div>
The dataset is at `xlam_function_calling_60k.json`. After accepting the use terms and login in your Huggingface account, you can simply access the dataset by:
```python
from datasets import load_dataset
datasets = load_dataset("Salesforce/xlam-function-calling-60k")
```
## JSON Data Format for Query and Answers
This JSON data format is used to represent a query along with the available tools and the corresponding answers. Here's a description of the format:
## Structure
The JSON data consists of the following key-value pairs:
- `query` (string): The query or problem statement.
- `tools` (array): An array of available tools that can be used to solve the query.
- Each tool is represented as an object with the following properties:
- `name` (string): The name of the tool.
- `description` (string): A brief description of what the tool does.
- `parameters` (object): An object representing the parameters required by the tool.
- Each parameter is represented as a key-value pair, where the key is the parameter name and the value is an object with the following properties:
- `type` (string): The data type of the parameter (e.g., "int", "float", "list").
- `description` (string): A brief description of the parameter.
- `required` (boolean): Indicates whether the parameter is required or optional.
- `answers` (array): An array of answers corresponding to the query.
- Each answer is represented as an object with the following properties:
- `name` (string): The name of the tool used to generate the answer.
- `arguments` (object): An object representing the arguments passed to the tool to generate the answer.
- Each argument is represented as a key-value pair, where the key is the parameter name and the value is the corresponding value.
Note that we format the `query`, `tools`, and `answers` to a string, but you can easily recover each entry to the JSON object via `json.loads(...)`.
## Example
Here's an example JSON data:
```json
{
"query": "Find the sum of all the multiples of 3 and 5 between 1 and 1000. Also find the product of the first five prime numbers.",
"tools": [
{
"name": "math_toolkit.sum_of_multiples",
"description": "Find the sum of all multiples of specified numbers within a specified range.",
"parameters": {
"lower_limit": {
"type": "int",
"description": "The start of the range (inclusive).",
"required": true
},
"upper_limit": {
"type": "int",
"description": "The end of the range (inclusive).",
"required": true
},
"multiples": {
"type": "list",
"description": "The numbers to find multiples of.",
"required": true
}
}
},
{
"name": "math_toolkit.product_of_primes",
"description": "Find the product of the first n prime numbers.",
"parameters": {
"count": {
"type": "int",
"description": "The number of prime numbers to multiply together.",
"required": true
}
}
}
],
"answers": [
{
"name": "math_toolkit.sum_of_multiples",
"arguments": {
"lower_limit": 1,
"upper_limit": 1000,
"multiples": [3, 5]
}
},
{
"name": "math_toolkit.product_of_primes",
"arguments": {
"count": 5
}
}
]
}
```
In this example, the query asks to find the sum of multiples of 3 and 5 between 1 and 1000, and also find the product of the first five prime numbers. The available tools are `math_toolkit.sum_of_multiples` and `math_toolkit.product_of_primes`, along with their parameter descriptions. The `answers` array provides the specific tool and arguments used to generate each answer.
## Benchmark Results
Along with the dataset, we also release two small-but-capable function-calling models as mentioned in the paper: [xLAM-1b-fc-r](https://huggingface.co/Salesforce/xLAM-1b-fc-r) and [xLAM-7b-fc-r](https://huggingface.co/Salesforce/xLAM-7b-fc-r).
We mainly test them on the [Berkeley Function-Calling Leaderboard (BFCL)](https://gorilla.cs.berkeley.edu/leaderboard.html), which offers a comprehensive evaluation framework for assessing LLMs' function-calling capabilities across various programming languages and application domains like Java, JavaScript, and Python.
<div align="center">
<img src="https://github.com/apigen-pipeline/apigen-pipeline.github.io/blob/main/img/table-result-0718.png?raw=true" width="620" alt="Performance comparison on Berkeley Function-Calling Leaderboard">
<p>Performance comparison on the BFCL benchmark as of date 07/18/2024. Evaluated with <code>temperature=0.001</code> and <code>top_p=1</code></p>
</div>
<p>Our <code>xLAM-7b-fc-r</code> secures the 3rd place with an overall accuracy of 88.24% on the leaderboard, outperforming many strong models. Notably, our <code>xLAM-1b-fc-r</code> model is the only tiny model with less than 2B parameters on the leaderboard, but still achieves a competitive overall accuracy of 78.94% and outperforming GPT3-Turbo and many larger models.
Both models exhibit balanced performance across various categories, showing their strong function-calling capabilities despite their small sizes.</p>
## Ethical Considerations
This release is for research purposes only in support of an academic paper. Our models, datasets, and code are not specifically designed or evaluated for all downstream purposes. We strongly recommend users evaluate and address potential concerns related to accuracy, safety, and fairness before deploying this model. We encourage users to consider the common limitations of AI, comply with applicable laws, and leverage best practices when selecting use cases, particularly for high-risk scenarios where errors or misuse could significantly impact people’s lives, rights, or safety. For further guidance on use cases, refer to our AUP and AI AUP.
## Citation
If you found the dataset useful, please cite:
```bibtex
@article{liu2024apigen,
title={APIGen: Automated Pipeline for Generating Verifiable and Diverse Function-Calling Datasets},
author={Liu, Zuxin and Hoang, Thai and Zhang, Jianguo and Zhu, Ming and Lan, Tian and Kokane, Shirley and Tan, Juntao and Yao, Weiran and Liu, Zhiwei and Feng, Yihao and others},
journal={arXiv preprint arXiv:2406.18518},
year={2024}
}
```
# APIGen 函数调用数据集
[论文](https://arxiv.org/abs/2406.18518) | [项目官网](https://apigen-pipeline.github.io/) | [模型](https://huggingface.co/collections/Salesforce/xlam-models-65f00e2a0a63bbcd1c2dade4)
本仓库包含由[APIGen](https://apigen-pipeline.github.io/)采集的60,000条数据。APIGen是一款自动化数据生成流水线,专为函数调用应用场景打造可验证的高质量数据集。本数据集的每条数据均经过三级分层校验:格式检查、实际函数执行验证与语义验证,确保数据的可靠性与正确性。
我们对600条采样数据进行了人工评估,数据正确率超过95%,剩余5%仅存在参数不准确等轻微问题。
数据集采集流程的整体框架如下所示,更多细节可参阅我们的项目[官网](https://apigen-pipeline.github.io/)。
<div style="text-align: center;">
<img src="figures/overview.jpg" alt="数据集概览" width="620" style="margin: auto;">
</div>
## 🎉 最新动态
- **[2024年7月]**:我们荣幸地宣布发布两款函数调用模型:[xLAM-1b-fc-r](https://huggingface.co/Salesforce/xLAM-1b-fc-r)与[xLAM-7b-fc-r](https://huggingface.co/Salesforce/xLAM-7b-fc-r)。这两款模型在[伯克利函数调用排行榜(Berkeley Function-Calling Leaderboard)](https://gorilla.cs.berkeley.edu/leaderboard.html)上取得了亮眼的排名,分别位列第3与第25名,性能超越诸多规模更大的模型。我们还提供了它们的GGUF文件,可直接在个人设备上部署。敬请期待后续更多高性能模型的发布。
- **[2024年7月]**:我们已针对讨论区#8(https://huggingface.co/datasets/Salesforce/xlam-function-calling-60k/discussions/8)中提及的问题,重新生成了1,896条受影响的数据。感谢社区用户发现这些问题,助力我们进一步提升数据集质量!
- **[2024年6月]**:我们的研究成果被[VentureBeat](https://venturebeat.com/ai/salesforce-proves-less-is-more-xlam-1b-tiny-giant-beats-bigger-ai-models/)与[新智元](https://mp.weixin.qq.com/s/B3gyaGwzlQaUXyI8n7Rguw)专题报道。
## 什么是函数调用智能体?
函数调用智能体能够根据自然语言指令执行功能性应用程序编程接口(API)调用。试想你查询帕洛阿尔托今日的天气,函数调用智能体可快速解析该请求,调用合适的API——例如`get_weather("Palo Alto", "today")`——并获取实时天气数据。这一先进能力极大拓展了大语言模型(Large Language Model,LLM)的实际应用场景,使其能够与社交媒体、金融服务等各类数字平台无缝交互,以前所未有的方式优化我们的数字体验。
<div style="text-align: center;">
<img src="figures/function-call-overview.png" alt="函数调用概览" width="620" style="margin: auto;">
</div>
## 数据集详情
本数据集由[DeepSeek-V2-Chat](https://github.com/deepseek-ai/DeepSeek-V2)与[Mixtral-8x22B-Inst](https://huggingface.co/mistral-community/Mixtral-8x22B-v0.1)生成。我们依托APIGen流水线,采集了覆盖21个类别的3,673个可执行API,以可扩展且结构化的方式生成多样化的函数调用数据集。
其中前33,659条数据由DeepSeek生成,对应ID范围为0至33658,剩余数据由Mixtral生成。
<div style="text-align: center;">
<img src="figures/dataset_pie_chart.png" alt="数据集分布饼图" width="380" style="margin: auto;">
</div>
数据集文件为`xlam_function_calling_60k.json`。在同意使用条款并登录您的Hugging Face账号后,您可通过以下代码轻松加载数据集:
python
from datasets import load_dataset
datasets = load_dataset("Salesforce/xlam-function-calling-60k")
## 查询与回答的JSON数据格式
本JSON数据格式用于表示查询、可用工具集与对应回答,以下是该格式的详细说明:
## 结构
JSON数据包含以下键值对:
- `query`(字符串类型):查询内容或问题描述。
- `tools`(数组类型):可用于解决该查询的可用工具集合。
每个工具均以对象形式表示,包含以下属性:
- `name`(字符串类型):工具名称。
- `description`(字符串类型):工具功能的简要说明。
- `parameters`(对象类型):工具所需的参数集合。
每个参数以键值对形式表示,键为参数名称,值为包含以下属性的对象:
- `type`(字符串类型):参数的数据类型(例如"int"、"float"、"list")。
- `description`(字符串类型):参数的简要说明。
- `required`(布尔类型):标识该参数是否为必填项。
- `answers`(数组类型):对应该查询的回答集合。
每个回答均以对象形式表示,包含以下属性:
- `name`(字符串类型):用于生成该回答的工具名称。
- `arguments`(对象类型):调用工具时传入的参数集合。
每个参数以键值对形式表示,键为参数名称,值为对应的参数取值。
请注意,本数据集中的`query`、`tools`与`answers`均以字符串形式存储,您可通过`json.loads(...)`方法轻松将其还原为JSON对象。
## 示例
以下是一段示例JSON数据:
json
{
"query": "Find the sum of all the multiples of 3 and 5 between 1 and 1000. Also find the product of the first five prime numbers.",
"tools": [
{
"name": "math_toolkit.sum_of_multiples",
"description": "Find the sum of all multiples of specified numbers within a specified range.",
"parameters": {
"lower_limit": {
"type": "int",
"description": "The start of the range (inclusive).",
"required": true
},
"upper_limit": {
"type": "int",
"description": "The end of the range (inclusive).",
"required": true
},
"multiples": {
"type": "list",
"description": "The numbers to find multiples of.",
"required": true
}
}
},
{
"name": "math_toolkit.product_of_primes",
"description": "Find the product of the first n prime numbers.",
"parameters": {
"count": {
"type": "int",
"description": "The number of prime numbers to multiply together.",
"required": true
}
}
}
],
"answers": [
{
"name": "math_toolkit.sum_of_multiples",
"arguments": {
"lower_limit": 1,
"upper_limit": 1000,
"multiples": [3, 5]
}
},
{
"name": "math_toolkit.product_of_primes",
"arguments": {
"count": 5
}
}
]
}
在本示例中,查询要求计算1至1000范围内所有3和5的倍数之和,并求出前5个质数的乘积。可用工具为`math_toolkit.sum_of_multiples`与`math_toolkit.product_of_primes`,并附带参数说明。`answers`数组给出了用于生成各回答的具体工具与参数配置。
## 基准测试结果
随数据集一同发布的还有本文中提及的两款轻量高性能函数调用模型:[xLAM-1b-fc-r](https://huggingface.co/Salesforce/xLAM-1b-fc-r)与[xLAM-7b-fc-r](https://huggingface.co/Salesforce/xLAM-7b-fc-r)。我们主要在[伯克利函数调用排行榜(Berkeley Function-Calling Leaderboard,BFCL)](https://gorilla.cs.berkeley.edu/leaderboard.html)上对这两款模型进行了测试,该排行榜提供了全面的评估框架,可用于评估大语言模型在Java、JavaScript、Python等多种编程语言与应用领域中的函数调用能力。
<div align="center">
<img src="https://github.com/apigen-pipeline/apigen-pipeline.github.io/blob/main/img/table-result-0718.png?raw=true" width="620" alt="伯克利函数调用排行榜性能对比">
<p>2024年7月18日的BFCL基准测试性能对比结果。评估参数为`temperature=0.001`与`top_p=1`</p>
</div>
我们的`xLAM-7b-fc-r`模型以88.24%的整体准确率位列排行榜第3名,性能超越诸多顶尖模型。值得一提的是,`xLAM-1b-fc-r`是排行榜上唯一一款参数规模不足20亿的微型模型,但仍取得了78.94%的颇具竞争力的整体准确率,性能超越GPT3-Turbo与诸多更大规模的模型。两款模型在各分类任务中均展现出均衡的性能,即便参数规模较小,仍具备出色的函数调用能力。
## 伦理考量
本次发布仅用于支撑学术论文的研究用途。我们的模型、数据集与代码并未针对所有下游应用场景进行专门设计与评估。我们强烈建议用户在部署该模型前,对其准确性、安全性与公平性等潜在问题进行评估与处理。我们鼓励用户充分考虑人工智能的普遍局限性,遵守适用法律法规,并在选择应用场景时遵循最佳实践,尤其在错误或滥用可能严重影响民众生活、权利或安全的高风险场景中。如需了解更多应用场景的相关指南,请参阅我们的AUP与AI AUP协议。
## 引用格式
若您认为本数据集对您的研究有所帮助,请引用以下文献:
bibtex
@article{liu2024apigen,
title={APIGen: Automated Pipeline for Generating Verifiable and Diverse Function-Calling Datasets},
author={Liu, Zuxin and Hoang, Thai and Zhang, Jianguo and Zhu, Ming and Lan, Tian and Kokane, Shirley and Tan, Juntao and Yao, Weiran and Liu, Zhiwei and Feng, Yihao and others},
journal={arXiv preprint arXiv:2406.18518},
year={2024}
}
提供机构:
maas创建时间:
2024-06-20
搜集汇总
数据集介绍
背景与挑战
背景概述
该数据集名为xlam-function-calling-60k,包含60,000个由APIGen自动化管道生成的函数调用数据,经过三层验证确保高可靠性,人类评估正确率超过95%。数据以JSON格式存储,涵盖查询、工具和答案,可用于支持函数调用代理的研究与应用。
以上内容由遇见数据集搜集并总结生成


