AudioCaps
收藏arXiv2025-09-30 收录
下载链接:
https://audiocaps.github.io/
下载链接
链接失效反馈官方服务:
资源简介:
该数据集名为AudioCaps,包含了大约47,000个长度为十秒的音频数据,这些数据涵盖了更加多样化的声音事件。此外,该数据集被包含在AudioLDM的预训练中,其规模属于大型,任务类型为文本到声音的生成。
This dataset is named AudioCaps. It comprises approximately 47,000 ten-second audio clips that cover a more diverse range of sound events. Additionally, this large-scale dataset is included in the pre-training process of AudioLDM, and its target task is text-to-audio generation.
搜集汇总
数据集介绍
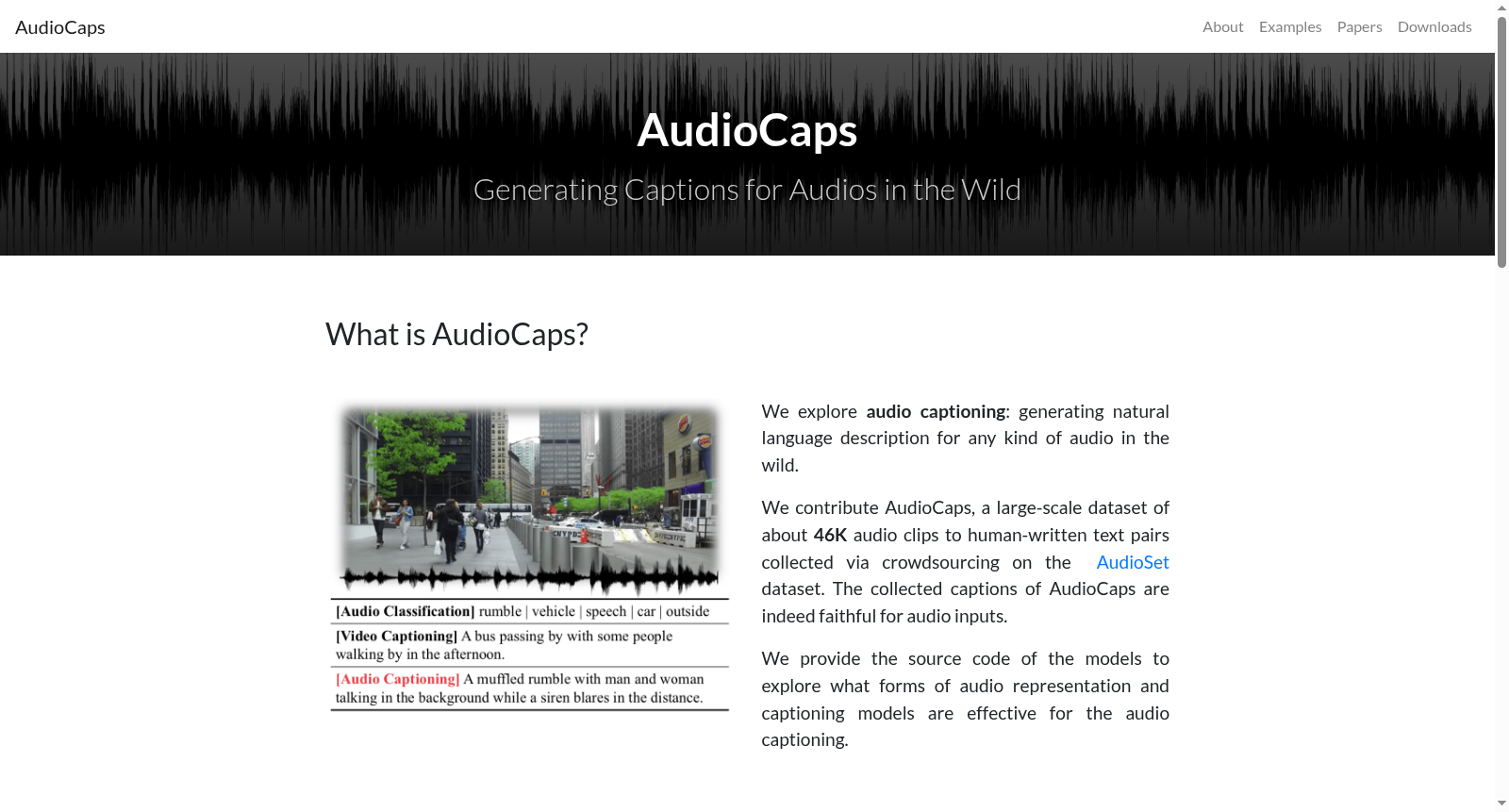
背景与挑战
背景概述
AudioCaps是一个大规模音频字幕生成数据集,包含约46,000个音频片段与人工撰写的文本配对,用于探索音频表示和字幕生成模型的有效性。
以上内容由遇见数据集搜集并总结生成


