CompSpoof
收藏arXiv2025-09-19 更新2025-09-23 收录
下载链接:
https://xuepingzhang.github.io/CompSpoof-dataset/
下载链接
链接失效反馈官方服务:
资源简介:
CompSpoof数据集是一个用于研究组件级音频反欺骗的公开数据集,由美国洛杉矶的OfSpectrum公司和中国昆山杜克大学数字创新研究中心的研究人员创建。该数据集包含约2500个音频样本,涵盖真实语音、欺骗语音、真实环境声和欺骗环境声的多种组合,用于训练和测试组件级音频欺骗检测模型。数据集分为训练集、开发集和评估集,用于支持音频欺骗检测研究,特别是针对组件级欺骗场景。
The CompSpoof dataset is a public dataset for research on component-level audio anti-spoofing, created by researchers from OfSpectrum Corporation based in Los Angeles, the United States, and the Digital Innovation Research Center of Duke Kunshan University in China. It contains approximately 2,500 audio samples, covering various combinations of genuine speech, spoofed speech, genuine ambient sounds and spoofed ambient sounds, which are used for training and testing component-level audio spoofing detection models. The dataset is divided into training set, development set and evaluation set to support audio spoofing detection research, especially for component-level spoofing scenarios.
提供机构:
美国洛杉矶的OfSpectrum公司和中国昆山杜克大学数字创新研究中心
创建时间:
2025-09-19
原始信息汇总
CompSpoof Dataset 概述
数据集简介
CompSpoof数据集专为研究组件级反欺骗而设计,其中语音或环境声音组件(或两者)可能被欺骗。
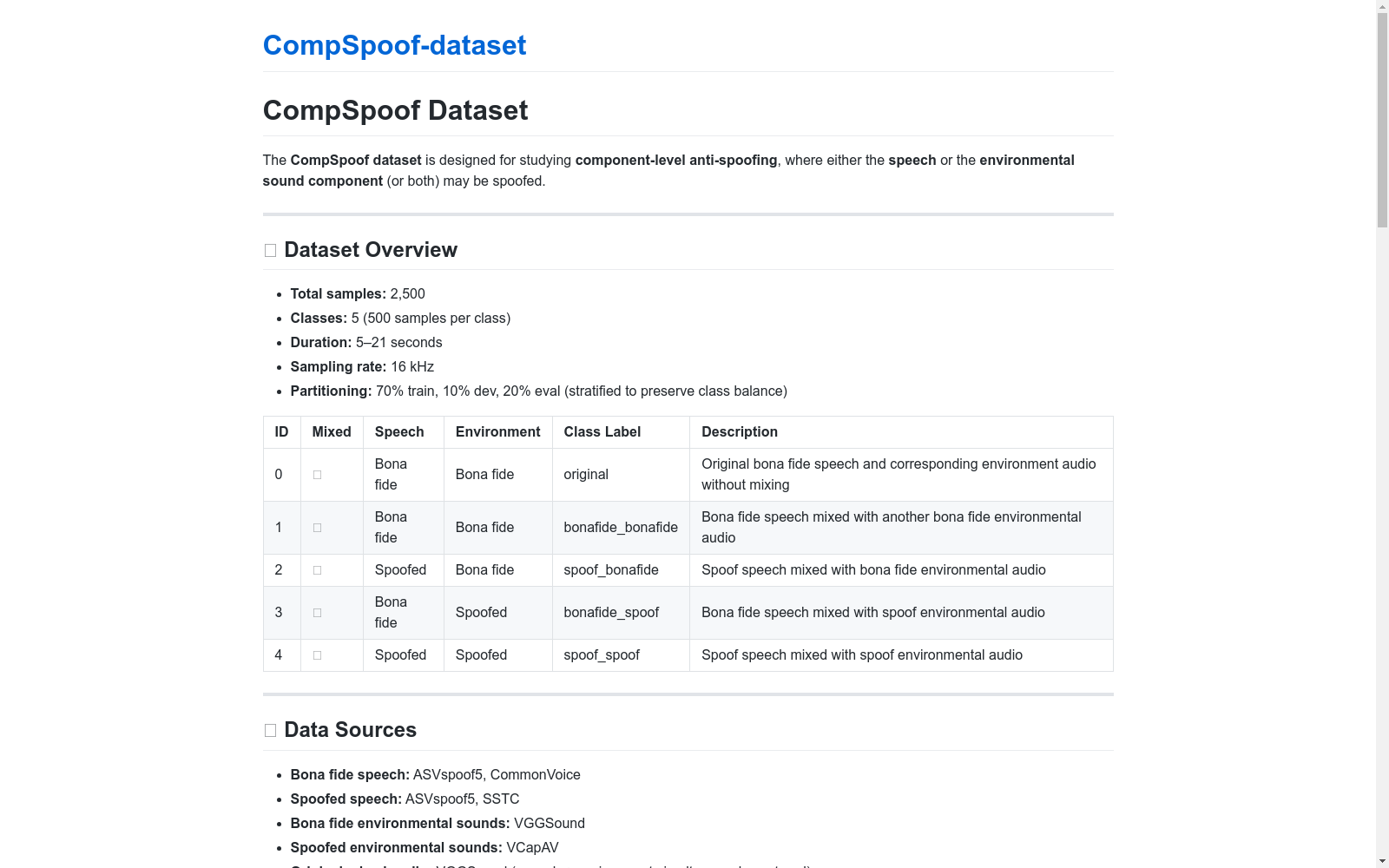
数据集概览
- 总样本数: 2,500
- 类别数: 5(每类500个样本)
- 时长: 5–21秒
- 采样率: 16 kHz
- 数据划分: 70%训练集、10%开发集、20%评估集(分层划分以保持类别平衡)
类别详情
| ID | 是否混合 | 语音状态 | 环境状态 | 类别标签 | 描述 |
|---|---|---|---|---|---|
| 0 | ❌ | 真实 | 真实 | original | 未经混合的原始真实语音及对应环境音频 |
| 1 | ✅ | 真实 | 真实 | bonafide_bonafide | 真实语音与另一真实环境音频混合 |
| 2 | ✅ | 欺骗 | 真实 | spoof_bonafide | 欺骗语音与真实环境音频混合 |
| 3 | ✅ | 真实 | 欺骗 | bonafide_spoof | 真实语音与欺骗环境音频混合 |
| 4 | ✅ | 欺骗 | 欺骗 | spoof_spoof | 欺骗语音与欺骗环境音频混合 |
数据来源
- 真实语音: ASVspoof5、CommonVoice
- 欺骗语音: ASVspoof5、SSTC
- 真实环境声音: VGGSound
- 欺骗环境声音: VCapAV
- 原始混合音频: VGGSound(同时捕获语音和环境)
环境声音涵盖室内、街道和自然环境,确保声学多样性。
数据处理
- 所有文件重采样至16 kHz。
- 最终时长由较短信号决定,较长信号被截断。
- 环境声音相对于语音按预定义信噪比进行缩放。
下载信息
数据集下载链接:https://xuepingzhang.github.io/CompSpoof-dataset/
搜集汇总
数据集介绍
构建方式
在音频反欺骗研究领域,CompSpoof数据集的构建采用了多源数据融合策略,涵盖真实与伪造语音及环境声音的多种组合。该数据集包含2500个音频样本,均匀分布于五个类别,每个类别500个样本。真实语音源自ASVspoof5和CommonVoice,伪造语音来自ASVspoof5和SSTC,真实环境声音取自VGG Sound,伪造环境声音则来源于VCapAV。音频处理过程中,所有文件被重采样至16kHz,并通过调整信噪比控制语音与环境声音的相对强度,确保数据在训练、开发和评估集间按70%、10%和20%的比例分层分布,以维持类别平衡。
使用方法
CompSpoof数据集的使用依托于分离增强的联合学习框架,该方法首先通过混合检测模型识别可能包含合成内容的音频片段。随后,UNet基分离网络在STFT域中将语音与环境声音分离,并利用自适应软掩码抑制语音残留。分离后的组件分别输入专用的反欺骗模型进行检测,其输出通过联合损失函数整合,包括分离损失、分类损失和一致性损失。推理阶段,模型对音频分块进行段级预测,并通过多数投票聚合为文件级结果,从而实现对组件级欺骗的有效定位和分类。
背景与挑战
背景概述
音频反欺骗研究在深度伪造技术快速演进的背景下,面临着日益复杂的攻击形式。2025年,由杜克昆山大学智能系统实验室与OfSpectrum公司联合发布的CompSpoof数据集,首次针对组件级音频欺骗这一新型攻击模式展开系统性研究。该数据集聚焦于语音与环境声音的局部篡改场景,通过构建2500条包含真实与伪造组件混合的音频样本,突破了传统反欺骗方法将整段音频简单二分类的局限。其创新性在于定义了五类组件组合状态,为多模态音频安全领域提供了细粒度评估基准。
当前挑战
组件级音频反欺骗面临双重挑战:在技术层面,传统基于整段音频分类的模型难以捕捉局部篡改特征,当仅语音或环境音单一组件被伪造时,模型易因未篡改组件的干扰而产生误判;在数据集构建过程中,需解决多源数据融合的异构性问题,包括不同采样率音频的时序对齐、信噪比控制下的能量平衡,以及分离网络训练中语音与环境声的频谱纠缠。此外,联合学习框架需协调分离网络与反欺骗模型的优化目标,避免特征丢失导致的检测性能退化。
常用场景
经典使用场景
在音频防伪研究领域,CompSpoof数据集被广泛应用于评估组件级音频伪造检测方法的性能。该数据集通过构建包含真实与伪造语音、环境声音混合的样本,为研究社区提供了模拟现实场景中组件级篡改行为的基准测试平台。其经典使用场景包括训练和验证分离增强的联合学习框架,该框架能够有效区分音频中独立成分的真实性,从而推动细粒度反欺骗技术的发展。
解决学术问题
CompSpoof数据集解决了传统音频反欺骗方法无法检测组件级篡改的学术难题。传统方法通常将整个音频片段视为完全真实或完全伪造,而该数据集首次引入了语音与环境声音独立伪造的概念,使研究者能够探索多模态混合场景下的细粒度检测机制。这一创新填补了部分伪造检测与组件级伪造检测之间的理论空白,为构建更鲁棒的音频认证系统提供了数据基础。
实际应用
在实际应用层面,CompSpoof数据集支撑的检测技术可应用于金融声纹认证、司法音频证据鉴定等高风险场景。当攻击者仅替换对话中的关键词语或篡改背景环境音时,基于该数据集的组件级检测模型能精准定位篡改成分,避免整体音频被误判。这种能力对保障智能客服系统、远程会议平台等语音交互场景的安全性具有重要价值。
数据集最近研究
最新研究方向
在音频反欺骗领域,CompSpoof数据集的推出标志着研究方向正从传统的整体音频伪造检测转向更细粒度的组件级分析。该数据集聚焦于语音与环境声音的独立伪造场景,推动了分离增强联合学习框架的发展,通过显式分离音频组件并应用专用反欺骗模型,有效提升了混合内容场景下的检测精度。这一创新不仅呼应了深度伪造技术日益精细化的趋势,也为多模态安全防御提供了新的理论支撑,在金融身份认证、智能家居安防等热点应用中展现出深远潜力。
相关研究论文
- 1CompSpoof: A Dataset and Joint Learning Framework for Component-Level Audio Anti-spoofing Countermeasures美国洛杉矶的OfSpectrum公司和中国昆山杜克大学数字创新研究中心 · 2025年
以上内容由遇见数据集搜集并总结生成


