folktexts
收藏Dataset Card for folktexts
Dataset Details
Dataset Description
- Language(s): English
- License: Code is licensed under the MIT license; Data license is governed by the U.S. Census Bureau terms of service.
Dataset Sources
- Repository: https://github.com/socialfoundations/folktexts
- Paper: https://arxiv.org/pdf/2407.14614
- Data source: 2018 American Community Survey Public Use Microdata Sample
Uses
The datasets were originally used to evaluate LLMs ability to produce calibrated and accurate risk scores in the Cruz et al. (2024) paper.
Dataset Structure
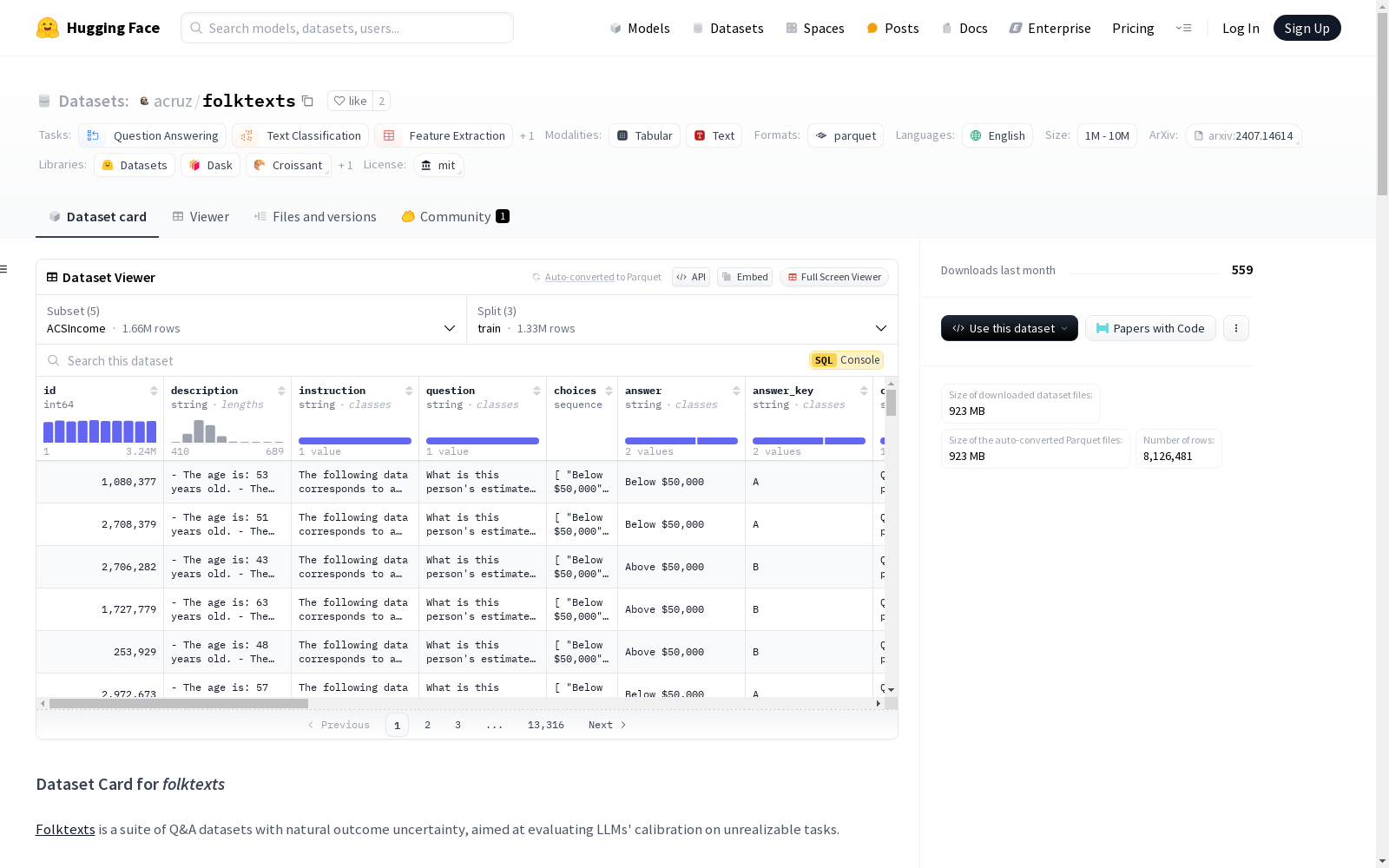
Description of Dataset Columns
id: A unique row identifier.description: A textual description of an individuals features, following a bulleted-list format.instruction: The instruction used for zero-shot LLM prompting (should be pre-appended to the row description).question: A question relating to the tasks target column.choices: A list of two answer options relating to the above question.answer: The correct answer from the above list of answer options.answer_key: The correct answer key; i.e.,Afor the first choice, orBfor the second choice.choice_question_prompt: The full multiple-choice Q&A text string used for LLM prompting.numeric_question: A version of the question that prompts for a numeric output instead of a discrete choice output.label: The tasks label. This is the correct output to the above numeric question.numeric_question_prompt: The full numeric Q&A text string used for LLM prompting.<tabular-columns>: All other columns correspond to the tabular features in this task. Each of these features will also appear in text form on the above description column.
Splits
The dataset was randomly split in training, test, and validation data, following an 80%/10%/10% split.
Dataset Creation
Source Data
The datasets are based on publicly available data from the American Community Survey (ACS) Public Use Microdata Sample (PUMS), namely the 2018 ACS 1-year PUMS files.
Data Collection and Processing
The categorical values were mapped to meaningful natural language representations using the folktexts package, which in turn uses the official ACS PUMS codebook.
Source Data Producers
U.S. Census Bureau.
Citation
If you find this useful in your research, please consider citing the following paper:
bib @inproceedings{ cruz2024evaluating, title={Evaluating language models as risk scores}, author={Andr{e} F Cruz and Moritz Hardt and Celestine Mendler-D{"u}nner}, booktitle={The Thirty-eight Conference on Neural Information Processing Systems Datasets and Benchmarks Track}, year={2024}, url={https://openreview.net/forum?id=qrZxL3Bto9} }
More Information
More information is available in the folktexts package repository and the accompanying paper.
Dataset Card Authors