CHAOS
收藏Hugging Face2025-05-07 更新2025-05-08 收录
下载链接:
https://huggingface.co/datasets/omoured/CHAOS
下载链接
链接失效反馈官方服务:
资源简介:
CHAOS(图表分析与异常样本)是一个专门设计用于在现实噪声条件下对多模态语言模型(MLLMs)进行压力测试的第一个基准数据集。它包含了10种视觉扰动和5种文本扰动,每种扰动分为三个严重级别(简单、中等、困难)。数据集总共包含了112,500个经过扰动的图表(每种扰动×3级别×15类型)。CHAOS旨在衡量和了解MLLMs在现实环境变得嘈杂时如何以及为何失败——理想情况下,它们仍能成功。
CHAOS (Chart Analysis and Outlier Samples) is the first benchmark dataset specifically designed for stress-testing multimodal large language models (MLLMs) under realistic noisy conditions. It contains 10 visual perturbations and 5 text perturbations, each categorized into three severity levels: easy, medium, and hard. The dataset totals 112,500 perturbed charts (each perturbation × 3 severity levels × 15 chart types). CHAOS aims to measure and understand how and why MLLMs fail when real-world environments become noisy, ideally enabling such models to still achieve successful performance.
创建时间:
2025-04-28
原始信息汇总
CHAOS Benchmark 数据集概述
基本信息
- 许可证: AGPL-3.0
- 语言: 英语 (en)
- 数据集大小: 6,103,383 字节
- 下载大小: 5,293,393 字节
- 类别大小: 10K < n < 100K
- 标签: chart-analysis, chart-understanding, MLLM, robustness
- 任务类别: visual-question-answering, image-to-text
数据集结构
特征
index: int64image: stringquestion: stringanswer: stringsplit: stringimgname: string
数据拆分
| 拆分名称 | 字节数 | 样本数 |
|---|---|---|
| chaos_vision | 4,559,793 | 60 |
| chaos_text | 1,543,590 | 30 |
数据集内容
- CHAOS-Vision: 75,000 样本
- CHAOS-Text: 37,500 样本
- CHAOS-All: 112,500 样本
下载链接
评估指标
- Relaxed Accuracy (±5% tolerance)
- CHAOS Robustness Score (ℛ)
数据集格式
- 格式: TSV (Tab-Separated Values)
- 列: index, image (Base64编码), question, answer, split, imgname
引用
bibtex @inproceedings{chaos2025, ... } @inproceedings{masry-etal-2022-chartqa, title = "{C}hart{QA}: A Benchmark for Question Answering about Charts with Visual and Logical Reasoning", author = "Masry, Ahmed and Long, Do and Tan, Jia Qing and Joty, Shafiq and Hoque, Enamul", booktitle = "Findings of the Association for Computational Linguistics: ACL 2022", month = may, year = "2022", address = "Dublin, Ireland", publisher = "Association for Computational Linguistics", url = "https://aclanthology.org/2022.findings-acl.177", doi = "10.18653/v1/2022.findings-acl.177", pages = "2263--2279", }
更新记录
| 日期 (YYYY-MM-DD) | 更新内容 |
|---|---|
| 2025-04-29 | 🚀 初始数据集发布 (所有扰动和TSV元数据上传) |
搜集汇总
数据集介绍
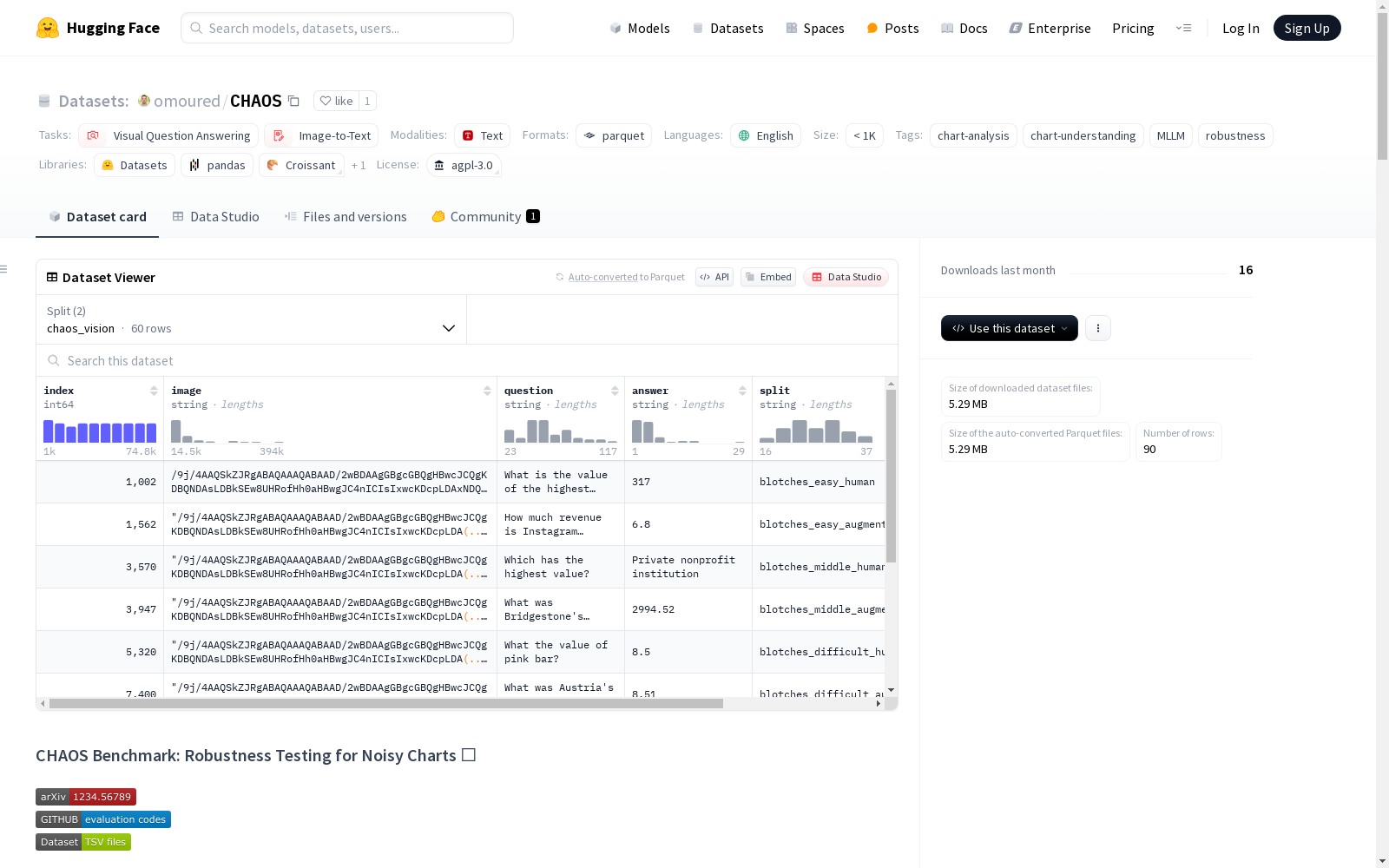
构建方式
CHAOS数据集作为首个专为测试多模态大语言模型(MLLM)在噪声环境下的鲁棒性而设计的基准,其构建过程体现了严谨的科学方法论。研究团队通过系统性地引入10种视觉扰动和5种文本扰动,每种扰动设置三个递增的严重等级(简单、中等、困难),最终构建了包含112,500个扰动图表的庞大数据集。数据来源基于ChartQA数据集,采用人工标注与算法增强相结合的方式,确保每个样本都包含图像、问题、答案三元组,并通过TSV格式标准化存储,其中图像采用Base64编码以保持数据完整性。
特点
该数据集的核心价值在于其独特的噪声模拟能力与评估体系。通过精心设计的15类扰动类型,全面覆盖了现实场景中可能出现的图像模糊、标签错位、文本拼写错误等噪声情况。数据集创新性地提出了鲁棒性评分(ℛ),将视觉和文本模态的退化程度统一量化,支持跨模型性能的标准化比较。每个样本均标注原始图像名称和扰动分级信息,便于研究者进行细粒度分析。特别值得注意的是,数据集在评估指标中引入了5%容忍度的宽松准确率,更符合实际应用场景的需求。
使用方法
使用CHAOS数据集进行模型评估时,研究者可通过提供的TSV文件快速载入数据。数据集已集成VLMEvalKit评估工具包,支持开箱即用的性能测试。典型使用流程包括:解析TSV文件获取Base64编码图像及相关元数据,通过解码还原图像内容;根据split字段识别具体的扰动类型和等级;调用内置的鲁棒性评分函数计算模型性能。为方便研究者快速上手,官方提供了完整的Python示例代码,涵盖数据加载、随机采样、图像可视化等基础操作。对于深入分析,建议参考附带的GitHub仓库获取详细的评估协议和基准结果复现方法。
背景与挑战
背景概述
CHAOS数据集由Omar Moured、Yufan Chen等研究人员于2025年推出,旨在为多模态大语言模型(MLLM)在噪声环境下的鲁棒性评估提供首个标准化基准。该数据集聚焦于图表理解领域,通过引入视觉和文本层面的15种扰动类型(涵盖模糊标签、拼写错误、遮挡等现实噪声),构建了包含112,500个扰动样本的评估体系。其创新性体现在提出的统一鲁棒性评分机制(ℛ),实现了跨模态性能的量化比较,弥补了传统评估方法在噪声场景下的局限性。作为ChartQA基准的延伸,CHAOS推动了图表分析任务从理想环境向真实复杂场景的范式转变。
当前挑战
CHAOS数据集针对图表理解任务的核心挑战在于模型对噪声的容忍度不足。具体表现为:1) 视觉扰动导致的关键信息丢失(如坐标轴模糊、颜色失真)会显著降低模型的特征提取能力;2) 文本扰动(如标签拼写错误、单位缺失)会干扰模型的语义解析逻辑;3) 多模态噪声的协同效应可能引发错误级联。在构建过程中,研究团队需平衡扰动强度的可量化性与现实代表性,通过设计三级渐进式噪声(easy/mid/hard)确保评估的细粒度。此外,建立跨模态统一评分标准需解决视觉准确率与文本准确率的量纲差异问题。
常用场景
经典使用场景
在视觉问答和图像到文本转换领域,CHAOS数据集通过引入多种视觉和文本扰动,为多模态大语言模型(MLLM)的鲁棒性测试提供了标准化的评估平台。其经典使用场景包括在受控环境下模拟现实世界中的噪声干扰,如模糊标签、拼写错误、遮挡和颜色偏移等,以全面评估模型在复杂条件下的表现。
衍生相关工作
CHAOS数据集衍生了一系列关于多模态模型鲁棒性研究的经典工作。其构建基于ChartQA数据集,但扩展了噪声测试维度。相关研究包括扰动类型对模型性能的影响分析、跨模态噪声传递研究,以及基于ℛ评分的模型架构优化工作,这些成果显著推动了噪声鲁棒性评估方法的发展。
数据集最近研究
最新研究方向
在图表理解领域,CHAOS数据集的推出为多模态大语言模型(MLLM)的鲁棒性评估提供了重要基准。该数据集通过引入视觉和文本层面的15种扰动类型,构建了包含112,500个噪声图表的测试环境,有效模拟了现实场景中的复杂干扰。当前研究聚焦于探索模型在模糊标签、拼写错误、遮挡等异常条件下的表现,并利用统一的鲁棒性评分体系(ℛ)进行跨模态性能比较。这一工作不仅填补了图表分析领域系统性噪声测试的空白,更为提升模型在实际应用中的可靠性提供了量化标准,推动了视觉-语言联合理解技术的实用化进程。
以上内容由遇见数据集搜集并总结生成


