TAT-QA
收藏arXiv2021-06-01 更新2024-06-21 收录
下载链接:
https://nextplusplus.github.io/TAT-QA/
下载链接
链接失效反馈官方服务:
资源简介:
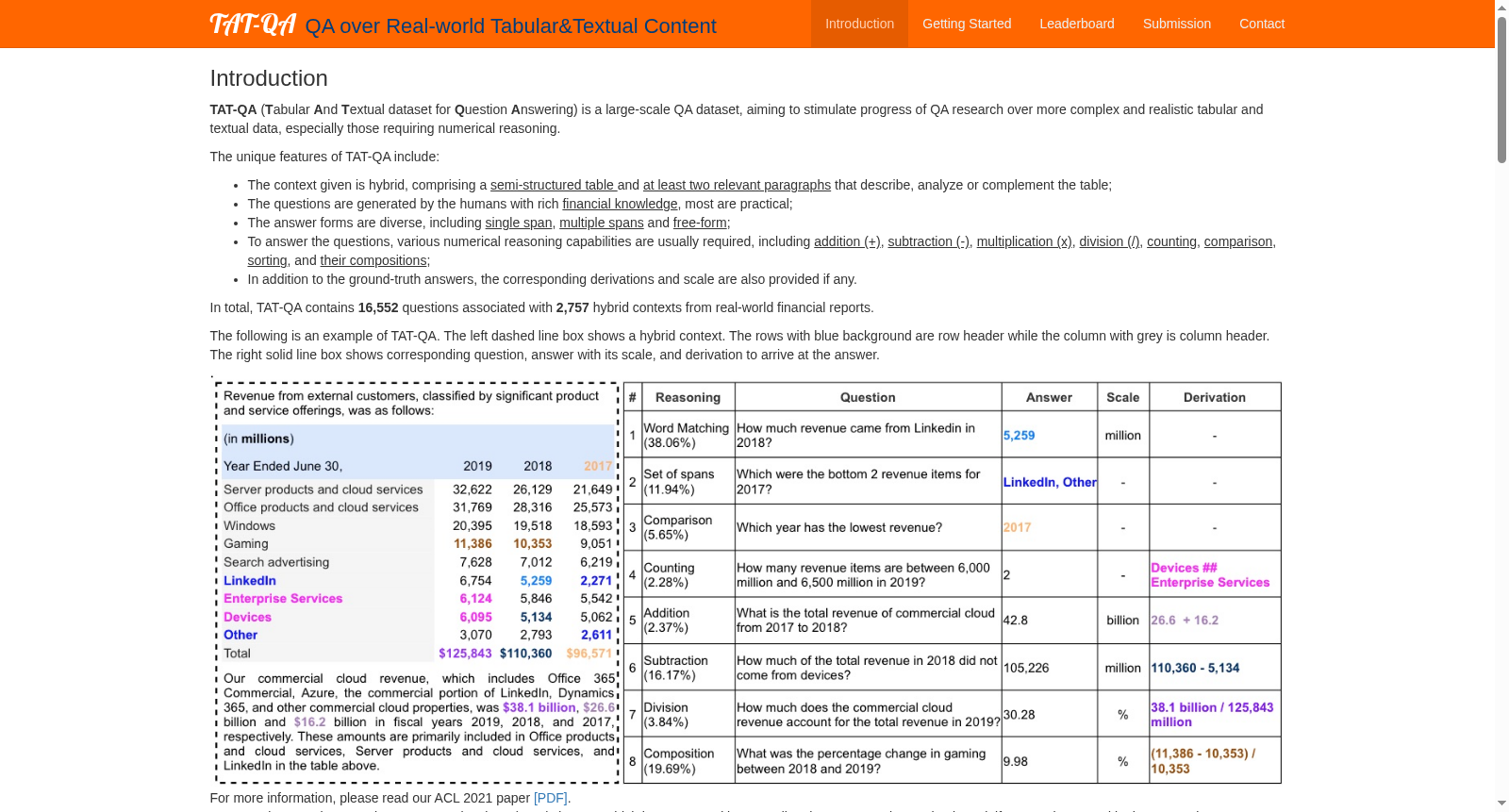
TAT-QA是一个大规模的问答数据集,由新加坡国立大学等机构创建,专注于金融领域中结合表格和文本内容的混合数据。该数据集包含16,552个问题,涉及2,757个混合上下文,来源于182份真实的金融报告。数据集的创建过程涉及从报告中提取表格和相关文本,由具有金融知识的专业标注者生成问题和答案。TAT-QA特别强调数值推理,如加减乘除等,旨在推动混合数据问答技术的发展,特别是在需要复杂数值推理的场景中。
TAT-QA is a large-scale question answering dataset developed by institutions including the National University of Singapore, focusing on hybrid data combining tabular and textual content in the financial domain. This dataset contains 16,552 questions covering 2,757 hybrid contexts sourced from 182 real-world financial reports. The construction of TAT-QA involves extracting tables and associated texts from the reports, with professional annotators possessing financial domain knowledge generating the corresponding questions and answers. TAT-QA particularly emphasizes numerical reasoning tasks such as basic arithmetic operations including addition, subtraction, multiplication and division, aiming to advance the development of hybrid data question answering technologies, especially in scenarios requiring complex numerical reasoning.
提供机构:
新加坡国立大学
创建时间:
2021-05-17
搜集汇总
数据集介绍
构建方式
在金融领域,财务报告通常融合表格与文本信息,构成了复杂的数据呈现形式。TAT-QA数据集的构建正是基于这一现实背景,从真实的财务报告中提取样本。研究团队首先从在线平台下载了约500份财务报告,利用表格检测模型识别其中的表格结构,并通过PDF解析工具提取内容,筛选出约2万个候选表格。随后,标注人员需为每个表格关联至少两段相关文本段落,形成混合上下文。在此基础上,具备金融背景知识的标注者根据混合上下文生成具有实际分析价值的问题,并标注答案及其推导过程。整个标注流程经过严格的质量控制,包括标注者筛选与两轮验证,最终形成了包含2,757个混合上下文和16,552个问答对的高质量数据集。
特点
TAT-QA数据集的核心特点在于其混合性,即同时包含表格与文本数据,模拟了金融报告中常见的信息结构。这种设计使得问答任务不仅需要理解表格中的结构化数字信息,还需结合文本描述进行语义关联。数据集中的问题广泛涉及数值推理,包括加减乘除、计数、比较及复合运算等,体现了金融分析中对复杂计算的需求。此外,答案标注不仅包含最终结果,还提供了详细的推导过程,有助于开发可解释的问答模型。数据集的挑战性体现在其与人类专家性能的显著差距上,当前最佳模型仅达到58.0%的F1分数,远低于人类的90.8%,突显了其在推动混合数据问答研究方面的重要价值。
使用方法
TAT-QA数据集的使用旨在训练和评估能够处理混合数据的问答模型。研究人员可将数据集划分为训练集、开发集和测试集,分别用于模型训练、调优和性能测试。使用该数据集时,模型需要同时处理表格与文本输入,识别相关信息并进行数值推理。例如,针对涉及计算的问答,模型需从表格中提取数字,结合文本中的语义描述,执行相应的算术运算。数据集中标注的答案来源(表格、文本或两者结合)和推导过程可辅助模型学习信息聚合与推理策略。此外,数据集的公开可用性为非商业研究提供了便利,支持学术界在混合数据问答领域开展深入探索。
背景与挑战
背景概述
在金融分析领域,表格与文本混合数据(如财务报告)广泛存在,但针对此类混合内容的问答研究长期处于空白。2021年,新加坡国立大学、6Estates Pte Ltd、四川大学及Bloomberg的研究团队联合构建了TAT-QA数据集,旨在推动对表格与文本混合数据的深度理解与推理。该数据集从真实财务报告中提取了2,757个混合上下文,包含16,552个问题-答案对,核心研究问题聚焦于需要数值推理(如加减乘除、比较、复合运算)的混合数据问答。TAT-QA的创立填补了混合数据问答基准的缺失,为金融自然语言处理领域提供了重要的评估资源,促进了如TAGOP等先进模型的发展,推动了复杂推理任务的技术进步。
当前挑战
TAT-QA所解决的领域问题在于混合数据问答,其挑战主要体现在模型需同时理解表格的结构化数字信息与文本的描述性语义,并执行精确的数值推理。例如,回答涉及百分比变化或复合计算的问题时,模型必须跨模态整合信息,并处理金融数据中常见的单位转换(如百万、十亿)。在数据集构建过程中,挑战包括从非标准化的财务报告中准确提取表格与关联段落,确保数据质量;标注需依赖具备金融知识的专业人员,以生成符合实际分析需求的问题;同时,需处理表格与文本间的深层语义关联,避免松散连接,从而保证混合上下文的真实性与复杂性。
常用场景
经典使用场景
在金融信息处理领域,TAT-QA数据集作为首个融合表格与文本内容的问答基准,其经典应用场景聚焦于训练和评估模型在复杂混合数据上的理解与推理能力。该数据集从真实财务报告中提取样本,构建了包含表格与描述性文本的混合上下文,要求模型不仅解析结构化数字信息,还需结合非结构化文本语义进行综合判断。这一场景模拟了金融分析师在实际工作中处理年报、财报时面临的典型挑战,即从相互关联的表格与段落中提取关键信息并执行数值计算,如收入占比分析、年度变化比较等,从而为自动化金融分析系统提供了可靠的测试平台。
衍生相关工作
围绕TAT-QA数据集,研究者们衍生出一系列经典工作,进一步拓展了混合数据问答的技术边界。其提出的基线模型TAGOP开创了基于序列标注与符号推理的混合数据处理框架,启发了后续多模态推理模型的设计思路。相关研究在此基础上探索了更复杂的数值推理机制,如引入外部金融知识增强模型语义理解,或结合图神经网络建模表格与文本的深层关联。同时,该数据集也促进了跨领域混合问答基准的构建,如在医疗、科学文献等场景中推广类似数据范式,推动了通用混合数据理解模型的发展。这些工作共同深化了对表格-文本协同推理问题的认识,为构建更强大、可解释的问答系统奠定了理论基础。
数据集最近研究
最新研究方向
在金融领域,表格与文本混合数据的问答研究正成为自然语言处理的前沿热点。TAT-QA数据集的提出,填补了现有研究在混合数据问答任务上的空白,其核心挑战在于要求模型具备跨模态信息融合与复杂数值推理能力。当前研究聚焦于提升模型对表格结构与文本语义的联合理解,例如通过序列标注技术提取关键证据,并设计符号化聚合算子进行算术运算。该数据集不仅推动了如TAGOP等基线模型的发展,还激发了对于可解释性推理、领域知识集成以及多跳推理机制的深入探索。这些进展对于智能金融分析、自动化报告解读等实际应用具有深远意义,标志着问答系统向处理现实世界复杂数据迈出了关键一步。
相关研究论文
- 1TAT-QA: A Question Answering Benchmark on a Hybrid of Tabular and Textual Content in Finance新加坡国立大学 · 2021年
以上内容由遇见数据集搜集并总结生成


