fancyzhx/amazon_polarity
收藏Hugging Face2024-01-09 更新2024-05-25 收录
下载链接:
https://hf-mirror.com/datasets/fancyzhx/amazon_polarity
下载链接
链接失效反馈官方服务:
资源简介:
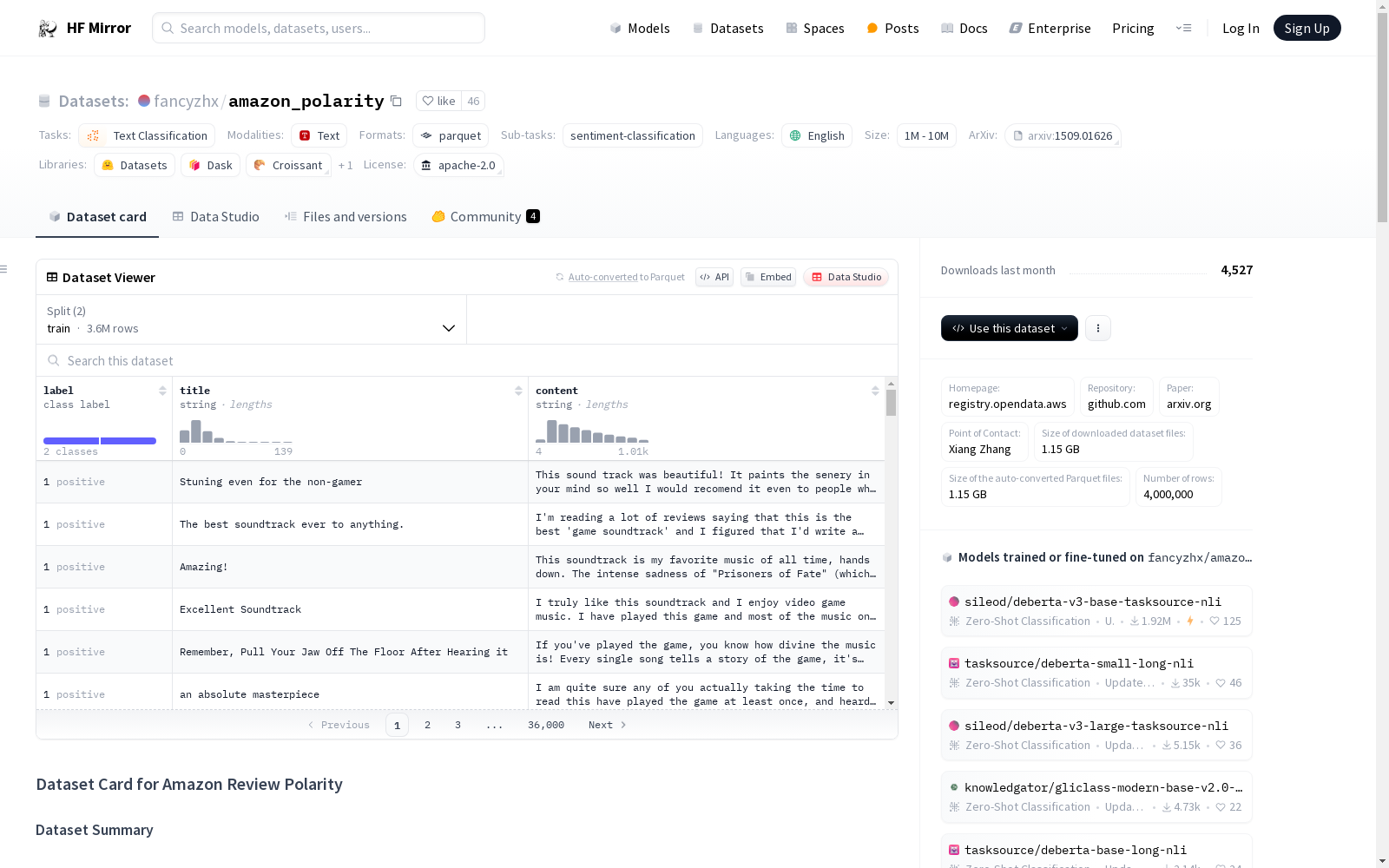
Amazon Review Polarity数据集包含亚马逊上的商品评论,主要用于文本分类任务,特别是情感分类。数据集将评分为1和2的评论标记为负面,评分为4和5的评论标记为正面,评分为3的评论被忽略。数据集包含360万条训练数据和40万条测试数据,每条数据包括评论的标题、内容和标签(正面或负面)。数据集由Xiang Zhang创建,并用于文本分类的基准测试。
Amazon Review Polarity数据集包含亚马逊上的商品评论,主要用于文本分类任务,特别是情感分类。数据集将评分为1和2的评论标记为负面,评分为4和5的评论标记为正面,评分为3的评论被忽略。数据集包含360万条训练数据和40万条测试数据,每条数据包括评论的标题、内容和标签(正面或负面)。数据集由Xiang Zhang创建,并用于文本分类的基准测试。
提供机构:
fancyzhx
原始信息汇总
数据集概述
数据集名称
- 名称: Amazon Review Polarity
- 别名: AmazonPolarity
数据集基本信息
- 语言: 英语 (en)
- 许可证: Apache-2.0
- 多语言性: 单语种
- 大小: 1M<n<10M
- 源数据: 原始数据
- 任务类别: 文本分类
- 任务ID: 情感分类
数据集结构
- 特征:
- label: 分类标签,0表示负面,1表示正面
- title: 字符串类型,包含评论标题
- content: 字符串类型,包含评论内容
- 数据分割:
- 训练集: 3600000个样本,总大小1604364432字节
- 测试集: 400000个样本,总大小178176193字节
数据集使用
- 训练与评估指标:
- 准确率 (Accuracy)
- F1分数 (F1 macro, F1 micro, F1 weighted)
- 精确度 (Precision macro, Precision micro, Precision weighted)
- 召回率 (Recall macro, Recall micro, Recall weighted)
数据集创建
- 创建者: Xiang Zhang (xiang.zhang@nyu.edu)
- 用途: 作为文本分类基准,用于论文《Character-level Convolutional Networks for Text Classification》
许可证信息
- 许可证: Apache License 2.0
引用信息
- McAuley, Julian, and Jure Leskovec. "Hidden factors and hidden topics: understanding rating dimensions with review text." In Proceedings of the 7th ACM conference on Recommender systems, pp. 165-172. 2013.
- Xiang Zhang, Junbo Zhao, Yann LeCun. Character-level Convolutional Networks for Text Classification. Advances in Neural Information Processing Systems 28 (NIPS 2015)
搜集汇总
数据集介绍
构建方式
该数据集通过采集亚马逊网站上的商品评论构建而成,涵盖了约3500万条评论,时间跨度达18年。数据集的构建基于情感分类的需求,将评分1和2视为负面评论,评分4和5视为正面评论,忽略了评分3的样本。在训练集和测试集中,每个类别分别包含了180万和20万的样本。
使用方法
使用该数据集时,用户可以从Hugging Face网站下载,并根据提供的train和test文件进行训练和评估。数据集支持文本分类和情感分类任务,用户可以根据自己的需求,利用数据集中的特征进行模型训练和性能评估,如准确率、F1分数等指标。
背景与挑战
背景概述
Amazon Review Polarity数据集,由Xiang Zhang于2013年构建,主要研究人员为Xiang Zhang、Junbo Zhao和Yann LeCun。该数据集源于亚马逊网站上的用户评论,涵盖约3500万条评论,时间跨度18年,主要用于文本分类领域,尤其是情感分析研究。数据集按照评论的情感极性分为正面(4星和5星)与负面(1星和2星),忽略了3星评论,为研究者提供了一个重要的基准数据集,对情感分析领域产生了深远的影响。
当前挑战
该数据集在构建过程中遇到的挑战主要包括:如何从大量非结构化的评论数据中提取有效的情感信息,以及如何处理数据中的噪声和异常值。在使用过程中,研究者面临的挑战包括如何提高分类模型的准确性和泛化能力,以及如何识别和处理数据中可能存在的偏见和局限性。
常用场景
经典使用场景
在自然语言处理领域,fancyzhx/amazon_polarity数据集被广泛用于情感分析的基准测试。该数据集包含了亚马逊商品评论文本,根据评论文本的情感色彩,将其归类为正面或负面,从而训练和评估模型的情感识别能力。
解决学术问题
fancyzhx/amazon_polarity数据集解决了情感分析中的数据标注和模型评估问题。它提供了一个大规模、经过标注的数据集,使得研究者能够在统一的评价标准下,如准确率、F1分数等,对模型进行训练和验证,推动了情感分析领域的研究进展。
实际应用
在实际应用中,fancyzhx/amazon_polarity数据集可用于构建智能客服系统、产品推荐系统等,通过分析用户评论文本的情感倾向,为用户提供更加个性化的服务,增强用户体验。
数据集最近研究
最新研究方向
在自然语言处理领域,情感分析是文本分类任务中的一个重要分支。近年来,Amazon Review Polarity数据集作为情感分析的标准数据集之一,被广泛应用于评估和比较各种文本分类模型。该数据集的最新研究方向主要集中在深度学习模型的优化,尤其是对卷积神经网络和循环神经网络的改进,以及跨域和跨语言的情感分析研究。此外,研究者们还关注数据集中的偏见和多样性问题,探索如何减少数据偏差以提高模型的公平性和准确性。这些研究对于提升在线商品推荐系统的质量,增强用户交互体验具有重要的意义和影响。
以上内容由遇见数据集搜集并总结生成


