svakulenk0/qrecc
收藏Hugging Face2022-07-02 更新2024-03-04 收录
下载链接:
https://hf-mirror.com/datasets/svakulenk0/qrecc
下载链接
链接失效反馈官方服务:
资源简介:
QReCC(对话上下文中的问题重写)是一个端到端的开放领域问答数据集,包含14K个对话和81K个问答对。该数据集的目的是提供一个具有挑战性的基准,用于端到端的对话式问答,包括问题重写、段落检索和阅读理解等子任务。QReCC的任务是在一个包含10M个网页的集合中找到对话问题的答案,这些网页被分割成54M个段落。同一对话中的问题的答案可能分布在多个网页上。段落集合应从Zenodo下载(passages.zip)。
QReCC (Question Rewriting in Conversational Context) is an end-to-end open-domain question answering dataset containing 14K dialogues and 81K question-answer pairs. This dataset aims to provide a challenging benchmark for end-to-end conversational question answering, covering subtasks such as question rewriting, passage retrieval, and reading comprehension. The task of QReCC is to locate answers to conversational questions from a corpus of 10 million web pages, which are split into 54 million passages. Answers to questions within the same dialogue may be scattered across multiple web pages. The passage corpus can be downloaded from Zenodo (passages.zip).
提供机构:
svakulenk0
原始信息汇总
数据集概述 - QReCC
数据集描述
数据集总结
QReCC(Question Rewriting in Conversational Context)是一个包含14K对话和81K问答对的端到端开放域问答数据集。该数据集旨在为包括问题重写、文章检索和阅读理解在内的端到端对话问答提供一个挑战性的基准。
支持的任务和排行榜
- 问答
语言
- 英语
数据集结构
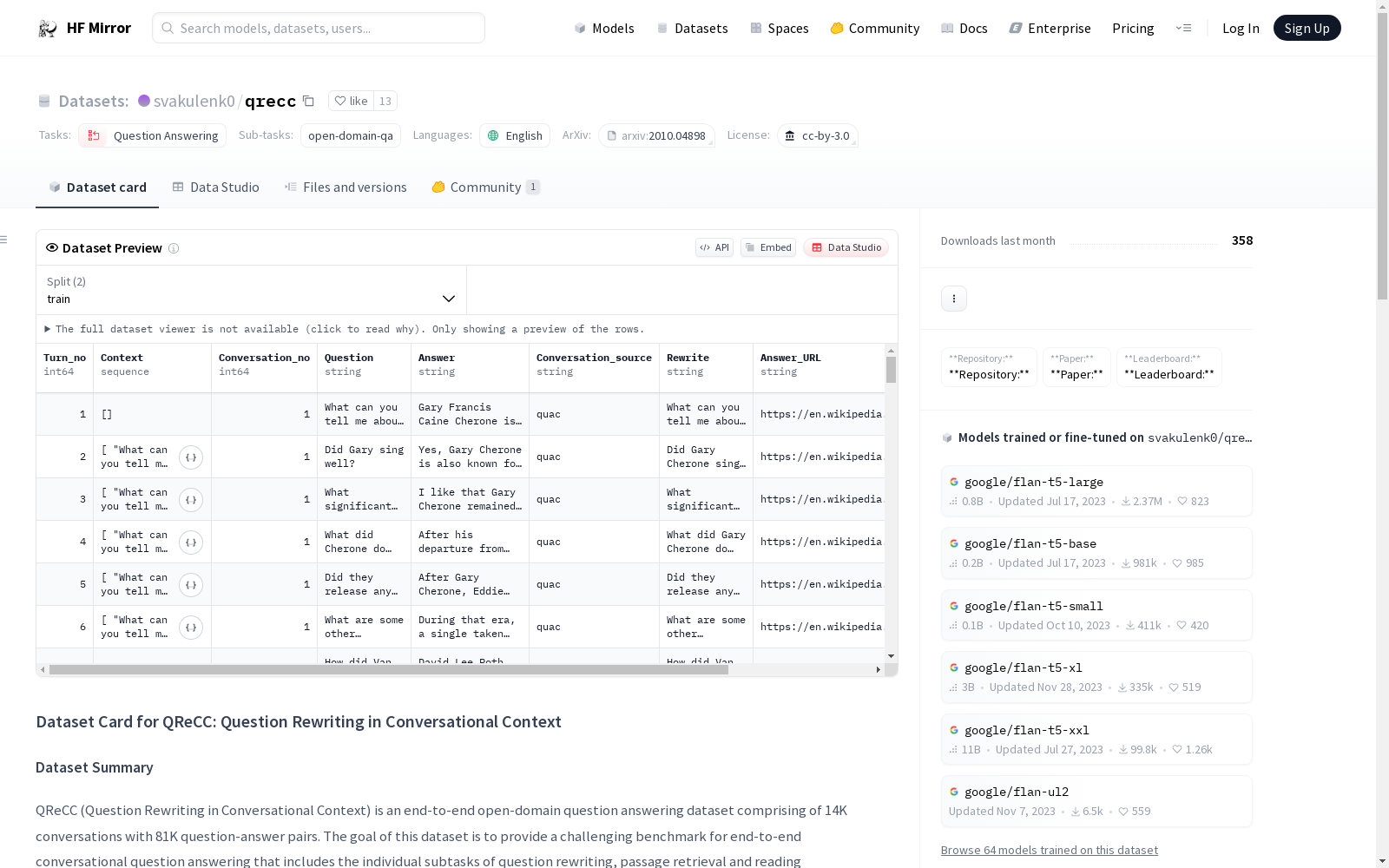
数据实例
数据集中的一个示例包含以下字段:
- Context(上下文)
- Question(问题)
- Rewrite(重写问题)
- Answer(答案)
- Answer_URL(答案来源URL)
- Conversation_no(对话编号)
- Turn_no(回合编号)
- Conversation_source(对话来源)
数据分割
- 训练集:63501
- 测试集:16451
数据集创建
源数据
- QuAC
- TREC CAsT
- Natural Questions
附加信息
许可信息
- CC BY-SA 3.0
引用信息
@inproceedings{ qrecc, title={Open-Domain Question Answering Goes Conversational via Question Rewriting}, author={Anantha, Raviteja and Vakulenko, Svitlana and Tu, Zhucheng and Longpre, Shayne and Pulman, Stephen and Chappidi, Srinivas}, booktitle={ NAACL }, year={2021} }
搜集汇总
数据集介绍
构建方式
QReCC数据集的构建基于QuAC、TREC CAsT以及Natural Questions等源数据,通过专家生成和现有数据收集的方式,形成了包含14K对话和81K问答对的开放域问题回答数据集。该数据集旨在为端到端的会话式问题回答提供具有挑战性的基准,涵盖了问题重写、篇章检索和阅读理解等子任务。
特点
QReCC数据集的特点在于其对话式的问题回答情境,问题可能跨越多个网页的篇章来分布答案。此外,数据集以英语为语言,提供了包含上下文、问题、重写问题、答案以及相关链接等信息的实例结构。数据集分为训练集和测试集,分别包含63501和16451个实例。
使用方法
使用QReCC数据集时,用户需先从Zenodo下载相关的篇章集合。该数据集适用于问题回答任务,可通过训练模型来识别对话中的问题,并重写问题以检索和阅读相关网页篇章,最终生成正确答案。数据集的使用遵循CC BY-SA 3.0许可协议,用户需在遵循协议的基础上进行使用和引用。
背景与挑战
背景概述
QReCC数据集,即对话上下文中的问题重写数据集,是由Raviteja Anantha、Svitlana Vakulenko等研究人员于2021年创建的。该数据集旨在为端到端开放领域问答提供一项具有挑战性的基准,涵盖问题重写、段落检索和阅读理解等子任务。QReCC数据集包含了14K个对话和81K个问题-答案对,其来源于QuAC、TREC CAsT和Natural Questions等数据集,对开放领域问答研究具有重要的推动作用。
当前挑战
QReCC数据集面临的挑战主要在于:1) 如何在对话上下文中准确地进行问题重写,以适应不断变化的对话情境;2) 如何高效地检索和整合分布在不同网页上的答案信息。此外,构建此类数据集时,还需克服数据收集、标注和整合过程中的技术难题,以确保数据的质量和实用性。
常用场景
经典使用场景
在当前自然语言处理领域,QReCC数据集以其独特的端到端开放域问题回答特性,成为学术研究的重要资源。该数据集包含14K对话和81K问答对,旨在为问题重写、篇章检索和阅读理解等子任务提供一个富有挑战性的基准。典型的使用场景是,研究者利用该数据集来训练和评估对话系统在理解并回应复杂、多轮对话中的问题时的性能。
解决学术问题
QReCC数据集解决了学术研究中如何真实模拟对话环境下的开放式问题回答的难题。它为研究者和开发者提供了一个平台,用以评估和改进对话系统的理解能力,特别是在处理跨多个网页分布的问题答案时。该数据集的意义在于推动了对话系统在自然语言处理领域的发展,并为相关算法提供了性能衡量的标准。
衍生相关工作
基于QReCC数据集,学术界已衍生出一系列相关工作,包括对话系统的评价方法研究、问题重写算法的优化、篇章检索技术的改进等。这些研究不仅拓宽了对话系统的应用范围,也为自然语言处理领域带来了新的研究方向和突破。
以上内容由遇见数据集搜集并总结生成


