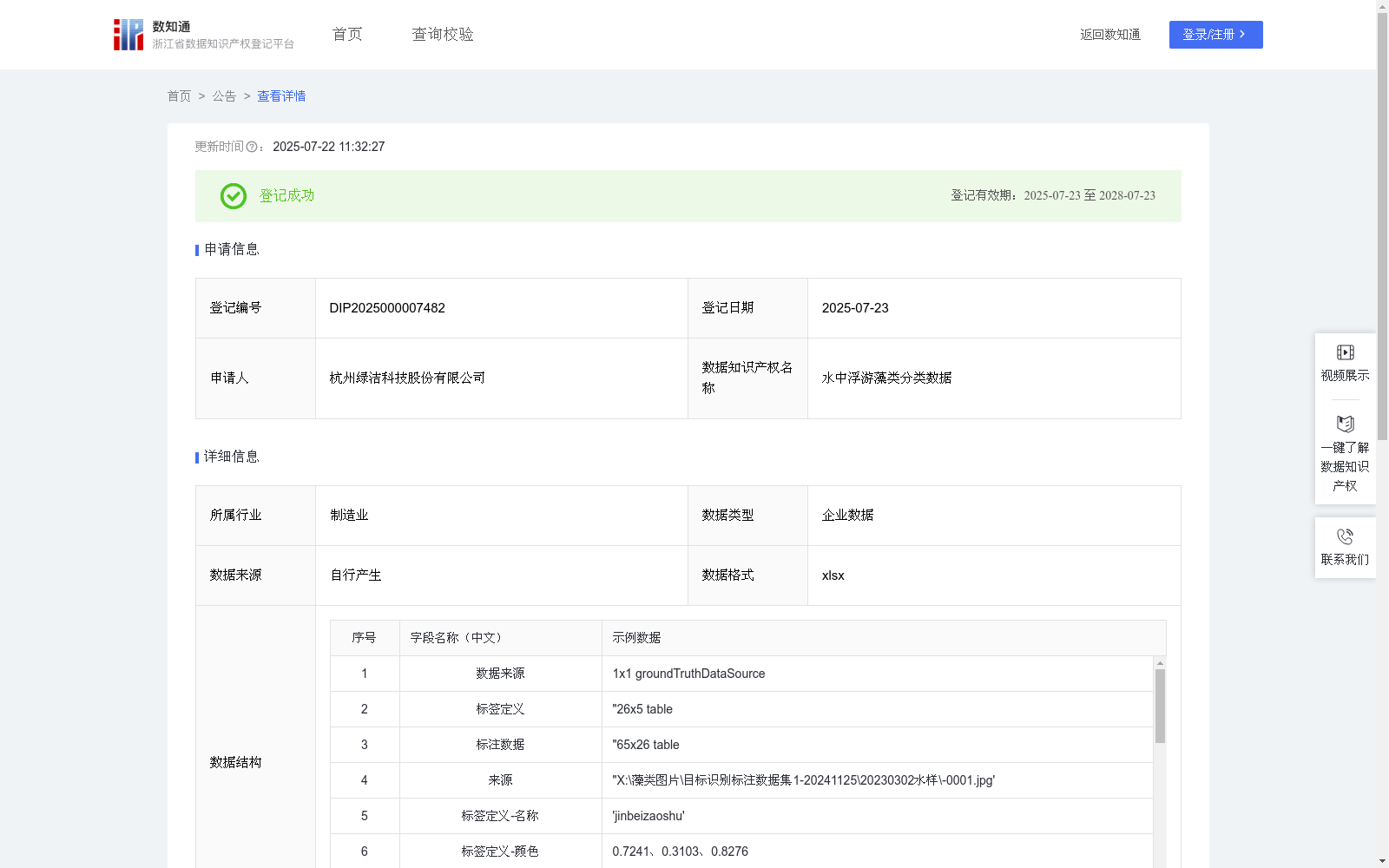
水中浮游藻类分类数据
收藏浙江省数据知识产权登记平台2025-07-22 更新2025-07-23 收录
下载链接:
https://www.zjip.org.cn/home/announce/trends/152529
下载链接
链接失效反馈官方服务:
资源简介:
对各种水体进行水样采集,通过水样固定、显微镜拍摄藻类图片、分析标注,建立各种属藻类数据集,作为标准数据集用于藻类AI识别模型训练、测试、验证,建立藻类自动识别算法,实现水体中藻类自动分类识别。(1)水样采集及处理:按照标准进行水样采集、固定、浓缩。
(2)水样图片数据获取:通过电动显微镜进行水样中浮游藻类图片扫描采集。
(3)数据标注:按照藻类形态学分类规则,将所采集的图片中藻类进行分类标注,包括命名藻类名称(Name)lanyinzaoshu(蓝隐藻属)、nangluozaoshu(囊裸藻属)、xiaoqiuzaoshu(小球藻属)、yizaoshu(衣藻属)等,定义标签颜色(LabelColor),形成标签定义(gTruth.LabelDefinitions)数据;用相应标签及标注框在每张水样图片上框出相应的藻类,形成包含各种藻类名称、藻类所在图片、藻类在图片上所处位置的标注数据(gTruth.LabelData)矩阵,大量标注数据(gTruth.LabelData)及藻类数据来源(gTruth.DataSource.Source)数据形成浮游藻类分类数据集。
(4)数据训练:利用yolo目标识别算法,将所标注数据集进行训练,建立藻类自动分类识别模型,其中学习率pg0/pg1/pg2动态衰减,最终<0.0001,轮次:至少训练50轮以上,观察损失收敛趋势。当训练/边界框损失<30%、训练/分类损失<20%、训练/DFL损失<30%、指标/精确率(B)>85%、指标/召回率(B)>80%、指标/mAP@0.5(B)>75%、指标/mAP@0.5:0.95(B)>55%、验证/边界框损失<40%、验证/分类损失<30%、验证/DFL损失<30%时模型为优质模型,当模型同时满足mAP@0.5 ≥ 65%、召回率 ≥ 70%、验证分类损失 ≤ 40%时可视为可用模型。
(5)藻类识别:将需要检测水样图片导入模型,即可实现水样中浮游藻类自动分类。
Water samples were collected from various aquatic environments, followed by sample fixation, microscopic imaging of algae, and annotation analysis, to establish a standard algal dataset for training, testing, and validating algal AI recognition models, thereby developing automatic algal recognition algorithms to achieve automated classification and identification of algae in water bodies.
(1) Water sample collection and processing: Standard protocols were followed for water sample collection, fixation, and concentration.
(2) Water sample image data acquisition: Images of planktonic algae in water samples were scanned and collected using a motorized microscope.
(3) Data annotation: Following algal morphological classification rules, algae in the collected images were classified and annotated. Specifically, algal names were assigned, including lanyinzaoshu (Cryptomonas, blue cryptomonad genus), nangluozaoshu (Trachelomonas, trailing flagellate genus), xiaoqiuzaoshu (Chlorella, chlorella genus), yizaoshu (Chlamydomonas, chlamydomonas genus), etc., with label colors (LabelColor) defined to form the label definition data ("gTruth.LabelDefinitions"); corresponding labels and bounding boxes were used to frame the target algae on each water sample image, creating an annotation data matrix ("gTruth.LabelData") that records the algal names, the source images of the algae, and their positions within the images. A large volume of annotation data ("gTruth.LabelData") and algal data source information ("gTruth.DataSource.Source") together constitute the planktonic algae classification dataset.
(4) Data training: The YOLO object detection algorithm was employed to train the annotated dataset, building an automatic algal classification and recognition model. The learning rates pg0/pg1/pg2 were dynamically decayed to a final value below 0.0001. The model was trained for at least 50 epochs, and the loss convergence trend was monitored. The model is categorized as a high-quality model when all of the following conditions are met: training/bounding box loss < 30%, training/classification loss < 20%, training/DFL loss < 30%, metric/precision(B) > 85%, metric/recall(B) > 80%, metric/mAP@0.5(B) > 75%, metric/mAP@0.5:0.95(B) > 55%, validation/bounding box loss < 40%, validation/classification loss < 30%, validation/DFL loss < 30%. The model is regarded as an available model when it simultaneously satisfies mAP@0.5 ≥ 65%, recall ≥ 70%, and validation/classification loss ≤ 40%.
(5) Algae recognition: By importing the water sample images to be detected into the trained model, automatic classification and identification of planktonic algae in the water samples can be realized.
提供机构:
杭州绿洁科技股份有限公司
创建时间:
2025-06-12
搜集汇总
数据集介绍
背景与挑战
背景概述
水中浮游藻类分类数据是一个由企业自行产生的数据集,包含519条记录,用于训练和验证藻类自动识别模型。数据集通过水样采集、显微镜拍摄和标注等步骤构建,支持藻类的自动分类识别。
以上内容由遇见数据集搜集并总结生成


