i-speak-kanoe
收藏Hugging Face2025-11-20 更新2025-11-21 收录
下载链接:
https://huggingface.co/datasets/carpenterbb/i-speak-kanoe
下载链接
链接失效反馈官方服务:
资源简介:
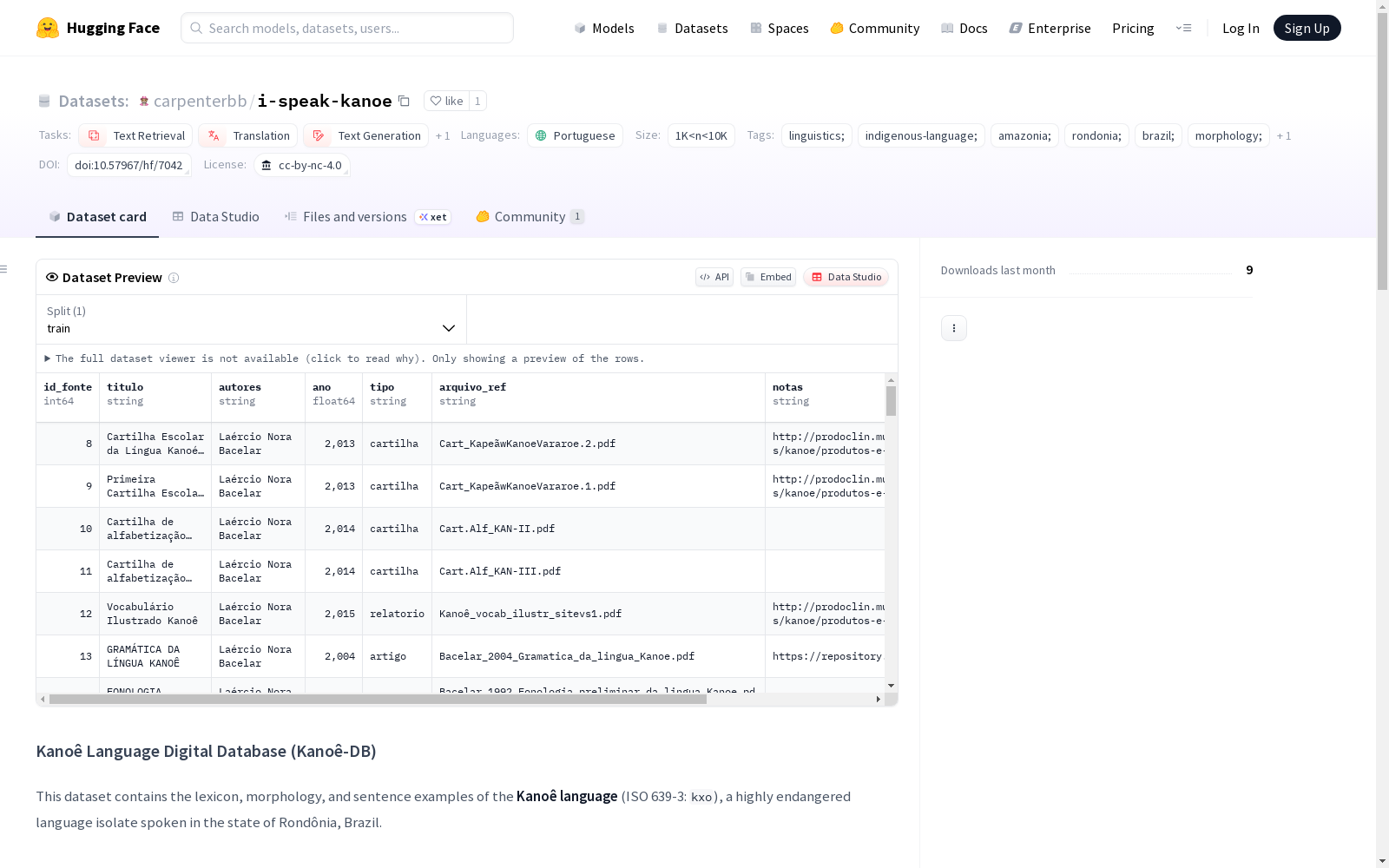
Kanoê语言数字数据库包含Kanoê语言(ISO 639-3代码:`kxo`)的词汇、形态学和句子示例,Kanoê语言是一种在巴西朗多尼亚州高度濒危的语言孤立语。该数据库还包括葡萄牙语的翻译。数据集大约有1600个词条和300个有上下文的例句,数据来源于1992年至2025年的田野调查。
创建时间:
2025-11-20
原始信息汇总
Kanoê语言数字数据库数据集概述
数据集基本信息
- 名称:Kanoê语言数字数据库
- 语言:Kanoê语和葡萄牙语
- 许可证:Creative Commons Attribution 4.0
- 数据规模:1K<n<10K
数据集内容
- 词条数量:约1,600个词目
- 例句数量:约300个语境化句子
- 数据类型:词典、形态学和句子示例
- 语言特征:高度濒危的语言孤立语
地理来源
- 地区:巴西朗多尼亚州
- 语言状态:高度濒危
数据结构
1. palavra.csv(词目)
- 包含词目和语法分类
- 字段:id_palavra、termo_kanoe、classe_gramatical
2. significado.csv(词义)
- 包含语义定义和文化注释
- 字段:traducao_primaria、nota_cultural、fk_id_palavra
3. frase.csv(句子)
- 包含语境化例句
- 字段:texto_kanoe、traducao_pt、fk_id_palavra、fk_id_bibliografia
4. pronuncia.csv(发音)
- 包含语音转录
- 字段:ipa、grafia
5. bibliografia.csv(参考文献)
- 包含数据提取的主要来源目录
- 字段:titulo、autores、ano
数据来源
- 收集时间:1992-2025年
- 收集方式:与Kanoê语使用者进行的实地调查数据
引用信息
- DOI:https://doi.org/10.57967/hf/7042
作者信息
- 作者:GABRIELLY ALVES GOMES、IAGO DE SOUSA ARAGÃO
搜集汇总
数据集介绍
构建方式
在亚马逊语言学研究领域,Kanoê语言数字数据库的构建体现了系统的田野调查方法。该数据集基于1992年至2025年间在巴西朗多尼亚地区开展的持续性田野工作,通过专业语言学家与卡诺埃语母语者的直接互动,采集了约1600个词条及其语法分类。数据采用关系型数据库架构进行组织,将词汇、语义、例句及发音等要素分别存储于五个互相关联的CSV文件中,确保了语言数据的结构化与可追溯性。
特点
作为濒危语言保护的珍贵资源,该数据集具有多重学术价值。其核心特征在于完整收录了卡诺埃语这一语言孤立症的词汇体系与形态结构,每个词条均标注标准拼写与语法类别,并配备详尽的葡萄牙语释义与文化注释。特别值得注意的是数据集包含约300个语境化例句,通过原文与译文的对照呈现,为研究该语言的句法特征提供了真实语料支撑。语音数据采用国际音标进行系统转写,进一步增强了语言材料的学术适用性。
使用方法
对于语言文档化研究而言,该数据集支持多维度的学术应用。研究者可通过关联查询机制,在词汇表、语义库、例句集和发音记录之间建立交叉引用,实现从词形到语用的全面分析。数据文件采用标准CSV格式,兼容主流统计分析工具与数据库管理系统,便于开展词汇统计、对比语言学和形态句法研究。在具体操作中,用户可通过外键关联实现跨表数据整合,例如将特定词汇的所有例句与其语音变体进行联合分析,为濒危语言研究提供系统化数据支持。
背景与挑战
背景概述
在濒危语言保护研究领域,Kanoê语作为巴西朗多尼亚州特有的语言孤立体系,其数字化记录工作始于1992年由Bacelar与Unternbäumen团队开展的田野调查。该数据集持续收录至2025年,系统整合了约1600个词条与300个语境化例句,通过词法分类与语音转写体系,为语言人类学与计算语言学提供了珍贵样本。其结构化数据库设计不仅承载着语言本体特征,更蕴含着亚马逊流域原住民文化的集体记忆,对世界语言多样性档案构建具有里程碑意义。
当前挑战
构建过程中面临双重挑战:在领域问题层面,需克服语言孤立系谱归属模糊性导致的类型学定位困难,同时解决因使用者锐减造成的语义验证困境;在技术实施层面,田野调查需建立跨文化信任机制以获取真实语料,而将声学信号转化为标准IPA标注时,还需处理音位变体与方言差异的复杂性。数据库关系模型的设计必须兼顾语言学理论规范与土著知识系统的特殊性,这对数字人文技术的适应性提出更高要求。
常用场景
实际应用
在语言复兴实践中,该数据库成为社区语言教育的重要资源。母语教育工作者可依据标准正字法开发识字教材,语言振兴项目能够基于真实语料设计教学方案。数字化存档形式便于建立语音库和词典工具,为Kanoê族群的文化传承提供技术支撑,同时也为巴西语言政策制定者提供了决策依据。
衍生相关工作
基于该数据集衍生的研究已形成多个重要方向。计算语言学家利用其结构化数据开发自动形态分析工具,人类学者结合文化注释开展认知语义研究。在语言技术领域,该语料支撑了低资源机器翻译系统的开发尝试,同时催生了跨语言信息检索的新方法,为其他濒危语言数字化项目提供了可复制的范式。
以上内容由遇见数据集搜集并总结生成


