UniVLN
收藏Hugging Face2025-05-24 更新2025-05-25 收录
下载链接:
https://huggingface.co/datasets/JunweiZheng/UniVLN
下载链接
链接失效反馈官方服务:
资源简介:
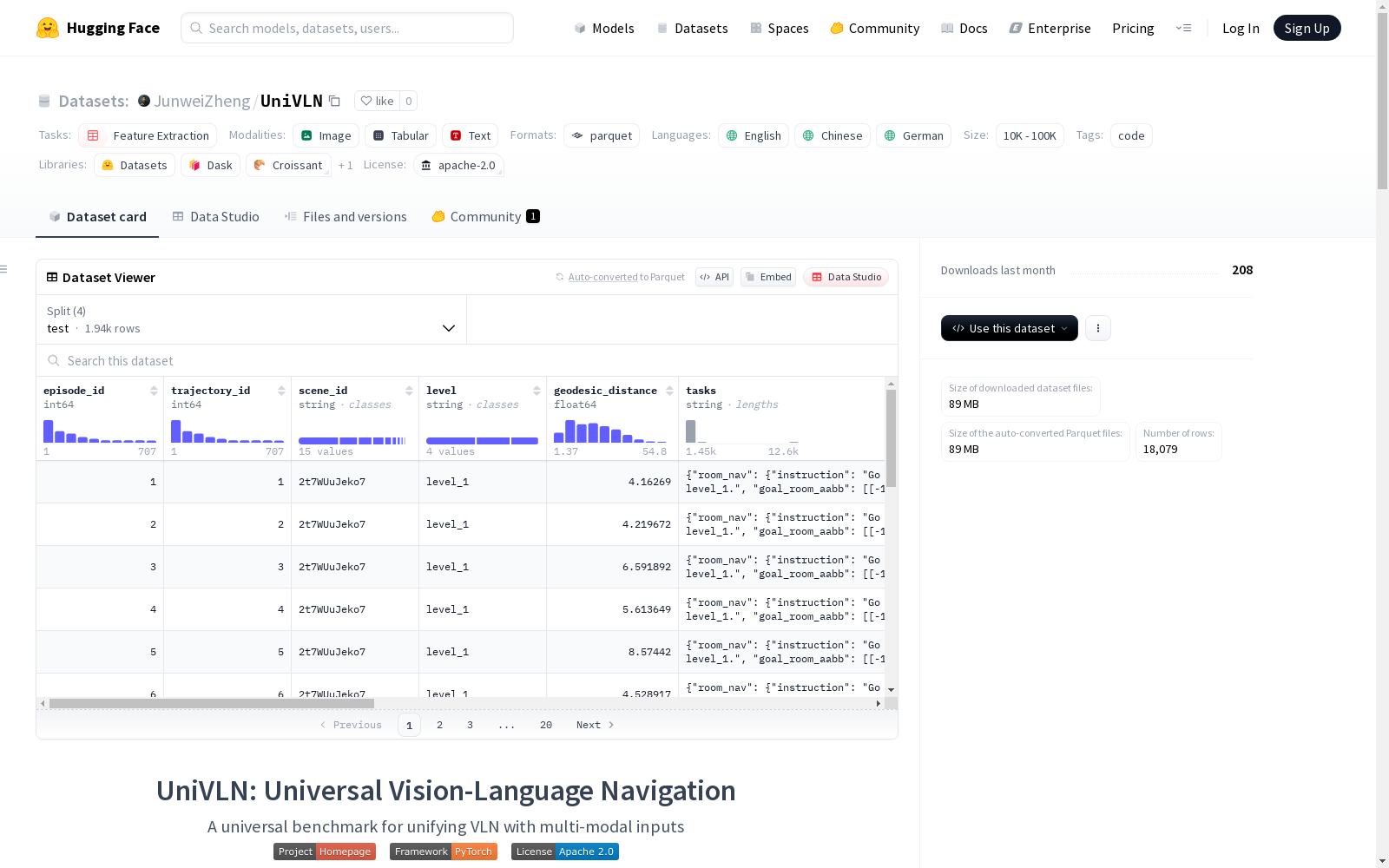
UniVLN是一个通用的视觉-语言导航任务统一基准,支持多模态输入。它包含了多种视觉导航任务,如对象导航、实例导航、图像导航、房间导航、点导航、指令导航和对话导航。数据集支持多种模态,包括视觉模态(如Pin、Pan、Fisheye、Depth、Event、Sem. Mask)、拓扑模态(如Occ. Map、Sem. Map、Topo. Map)和几何模态(如Point Cloud、Pose),以及音频和文本模态。数据集分为训练集、验证集(分为seen和unseen)和测试集,所有数据都以Parquet文件格式存储,并提供了JSON格式的轨迹数据样本。
UniVLN is a unified benchmark for general vision-language navigation tasks that supports multimodal inputs. It encompasses a variety of visual navigation tasks, including Object Navigation, Instance Navigation, Image Navigation, Room Navigation, Point Navigation, Instruction Navigation, and Dialogue Navigation. The dataset supports multiple modalities, namely visual modalities (e.g., Pin, Pan, Fisheye, Depth, Event, Sem. Mask), topological modalities (e.g., Occ. Map, Sem. Map, Topo. Map), geometric modalities (e.g., Point Cloud, Pose), as well as audio and text modalities. The dataset is divided into training set, validation set (split into seen and unseen subsets), and test set. All data are stored in Parquet file format, and JSON-formatted trajectory data samples are provided.
创建时间:
2025-05-16
原始信息汇总
UniVLN: Universal Vision-Language Navigation 数据集概述
基本信息
- 许可证: Apache 2.0
- 语言: 英语 (en)、中文 (zh)、德语 (de)
- 任务类别: 特征提取 (feature-extraction)
- 标签: 代码 (code)
- 数据集大小: 1B < n < 10B
- 数据集名称: UniVLN
- 项目主页: https://junweizheng93.github.io/publications/UniVLN/UniVLN.html
数据集结构
- 数据格式: Parquet 文件
- 数据分割:
trainval_seenval_unseentest
支持的视觉语言导航 (VLN) 任务
| 任务类型 | 支持情况 |
|---|---|
| 物体导航 (ObjNav) | ✅ |
| 实例导航 (InstanceNav) | ✅ |
| 图像导航 (ImgNav) | ✅ |
| 房间导航 (RoomNav) | ✅ |
| 点导航 (PointNav) | ✅ |
| 指令导航 (InstructionNav) | ✅ |
| 对话导航 (DialogNav) | ✅ |
支持的模态
| 模态类型 | 支持情况 |
|---|---|
| 视觉: Pin | ✅ |
| 视觉: Pan | ✅ |
| 视觉: Fisheye | ✅ |
| 视觉: Depth | ✅ |
| 视觉: Event | ✅ |
| 视觉: Sem. Mask | ✅ |
| 拓扑: Occ. Map | ✅ |
| 拓扑: Sem. Map | ✅ |
| 拓扑: Topo. Map | ✅ |
| 几何: Point Cloud | ✅ |
| 几何: Pose | ✅ |
| 音频: Male | ✅ |
| 音频: Female | ✅ |
| 文本: EN | ✅ |
| 文本: CN | ✅ |
| 文本: DE | ✅ |
| 文本: Dial. | ✅ |
文件夹结构
UniVLN ├── parquet_format ├── train │ ├── 17DRP5sb8fy │ │ ├── imgs │ │ ├── semantic_map_level_1.svg │ │ ├── trajectories.json │ ├── ... ├── val_seen ├── val_unseen ├── test
轨迹数据格式示例
json { "episode_id": 2, "trajectory_id": 2, "scene_id": "5q7pvUzZiYa", "level": "level_1", "tasks": { "room_nav": { ... }, "obj_nav": { ... }, "instance_nav": { ... }, "img_nav": { ... }, "point_nav": { ... }, "instruction_nav": { ... }, "dialog_nav": { ... } }, "start_position": xxx, "start_orientation": xxx, "end_position": xxx, "end_orientation": xxx, "geodesic_distance": 6.858829021453857, "reference_path": xxx, "available_actions": { ... }, "gt_actions": xxx, "gt_poses": xxx }
最新动态
- [2025/05/22] 上传 Parquet 文件以生成 croissant 文件。
- [2025/05/15] 发布 UniVLN 的第一个版本。
搜集汇总
数据集介绍
构建方式
UniVLN数据集作为视觉语言导航领域的通用基准,其构建过程体现了多模态融合的前沿理念。研究团队通过整合R2R、VLN-CE等9个主流数据集的轨迹数据,采用Parquet文件格式进行标准化存储,每个场景包含完整的视觉信息(全景图、深度图等)和语义地图。数据采集覆盖了7种导航任务类型,通过统一的数据结构将不同来源的轨迹数据重新标注为包含多语言指令、目标位置、动作序列等要素的标准化格式,确保了数据的兼容性和扩展性。
特点
该数据集最显著的特点是实现了视觉语言导航任务的全方位覆盖,支持包括ObjNav、InstanceNav等7类导航任务,以及视觉、拓扑、几何等14种模态输入。相较于现有数据集,UniVLN首次整合了鱼眼视角、事件相机数据、多语种文本(英/中/德)和对话导航等新型模态,其多语言指令系统包含平行翻译的导航描述。数据规模达到十亿级别,每个轨迹样本均包含精确的几何位置信息、参考路径及可执行动作集合,为跨模态导航研究提供了前所未有的丰富上下文。
使用方法
研究者可通过加载Parquet格式的分割数据(train/val_seen/val_unseen/test)快速开展实验。数据集采用场景ID层级化存储结构,每个场景文件夹包含图像数据、语义地图和轨迹文件。轨迹数据采用JSON标准化格式,明确标注了各任务的指令文本、目标位置容差半径以及动作空间定义。对于多任务学习,可直接调用tasks字段下的特定任务数据;跨模态研究则可结合视觉输入与对应语义地图。项目主页提供了PyTorch框架的接口建议,支持从端到端训练到零样本评估的全流程实验。
背景与挑战
背景概述
UniVLN(Universal Vision-Language Navigation)作为一项开创性的多模态导航基准数据集,由Junwei Zheng等人于2025年推出,旨在统一视觉语言导航(VLN)领域的多样化任务。该数据集整合了包括目标导航(ObjNav)、实例导航(InstanceNav)、图像导航(ImgNav)等七种核心任务,并支持视觉、拓扑、几何、音频及文本等多种模态输入。其多语言支持(英语、中文、德语)和丰富的环境表示(如深度图、语义掩码、点云等)使其成为跨模态导航研究的里程碑式资源,显著推动了具身智能与多模态交互的融合发展。
当前挑战
UniVLN面临的领域挑战在于解决多模态对齐与跨任务泛化的核心问题:视觉-语言模态的异构性导致特征融合困难,动态环境中长序列动作规划的时空一致性难以保持,且多语言指令的语义鸿沟加剧了跨文化场景的导航复杂度。构建过程中的技术挑战包括多源数据标准化(如统一深度图与语义地图的坐标系)、大规模轨迹标注的精度验证(尤其涉及跨任务重叠路径的冲突检测),以及实时事件流数据(Event Camera)与传统视觉数据的时空同步问题。
常用场景
经典使用场景
在视觉语言导航(VLN)领域,UniVLN数据集作为通用基准,为多模态输入的统一提供了标准化平台。该数据集广泛应用于智能体在复杂环境中基于视觉和语言指令的导航任务研究,涵盖从简单路径规划到复杂语义理解的多层次挑战。研究者通过该数据集可系统评估模型在跨模态对齐、长期依赖建模和环境适应性等方面的性能表现。
实际应用
该数据集支撑的服务机器人导航系统已在智能家居、医疗陪护等场景落地应用。通过融合深度视觉、语义地图和跨语言指令理解,系统能准确执行如'找到卧室里的药瓶'等复杂任务。在2023年DARPA地下挑战赛中,基于UniVLN训练的模型在未知环境导航任务中表现出色。
衍生相关工作
UniVLN催生了跨模态预训练框架UniVLN-BERT和动态环境适应模型DE-VLN等代表性工作。MetaAI提出的Oscar模型利用该数据集实现了视觉-语言-几何的多模态对齐,相关成果发表于NeurIPS 2024。数据集还支撑了首个支持中英德三语的通用导航基准Goat-Bench的开发。
以上内容由遇见数据集搜集并总结生成


