alkintin/huchenfeng-dataset
收藏Hugging Face2025-12-08 更新2025-12-20 收录
下载链接:
https://hf-mirror.com/datasets/alkintin/huchenfeng-dataset
下载链接
链接失效反馈官方服务:
资源简介:
---
language:
- zh
license: other
pretty_name: HuChenFeng Dialogue Dataset
size_categories:
- 50K<n<100K
task_categories:
- text-generation
task_ids:
- dialogue-generation
source_datasets:
- original
tags:
- 户晨风
---
# Dataset Card: HuChenFeng Dialogue Dataset
## Dataset Summary
HuChenFeng Dialogue Dataset 收录了 81,060 条高质量的中文单轮对话,每条样本由一个「用户」提问与一段长篇的「主播」回答组成,完整保留了知名主播 **户晨风** 的口语化表达、情绪变化与节奏。原始素材来自 2023–2025 年的直播转录,先经 Whisper Large-v3 语音识别,再由 Gemini-2.5-Flash 清洗去噪,最终使用 Gemini-2.5-Flash-Lite 为每段回答生成 3–5 个不同角度的问题。生成的问题与对应原回答经人工与规则联动过滤,最后导出为 `question_answer.jsonl`(ChatML 风格 `messages` 列表),可直接用于监督微调(SFT)、LoRA/QLoRA、角色扮演代理构建等任务。
* **规模**:81,060 条问答对(≈2.8B tokens,Qwen 分词),平均问题 18.3 个中文字,回答 342.7 个中文字。
* **格式**:JSON Lines,每行一个样本,字段同 `transformers` ChatML(`user` → `assistant`)。
* **来源**:户晨风 2023–2025 年[直播转录](https://github.com/Olcmyk/HuChenFeng)。
* **用途**:适合训练中文风格迁移、长篇回答、直播带货口吻或人格化聊天的模型,也可作为 prompt 工程与数据合成案例。
## Supported Tasks and Leaderboards
- **Dialogue / Instruction Tuning**:训练中文问答、角色扮演、对话安全或记忆模块。
- **Data Augmentation**:可为其他中文会话系统提供长篇回答示例。
## Languages
- **Input language**:Simplified Chinese (zh-Hans),包含大量口语、俚语、幽默用法以及中文夹杂口头禅。
## Dataset Structure
### Data Instances
```json
{
"messages": [
{"role": "user", "content": "你觉得现在的大学还有含金量吗?"},
{"role": "assistant", "content": "你读大学,你有点含金量也行,说白了水个学历..."}
]
}
```
回答通常是 1–3 段长文本,保持主播原始口吻;不同问题可能指向相同回答,以保留多问法效果。
### Data Fields
- `messages` *(List[Dict])*:标准 ChatML 对话列表,长度固定 2。
- `role` *(str)*:`"user"` 或 `"assistant"`。
- `content` *(str)*:UTF-8 中文文本,已去除 Markdown/表情符号,仅保留原生口语。
## Data Collection
### Curation Rationale
- 通过公开直播内容构建能体现主播人格、语速、逻辑跳跃等特征的风格化语料,填补中文口语 LoRA/SFT 数据缺口。
### Source Data
#### Initial Data Collection and Normalization
1. **语音转文字**:户晨风 2023–2025 直播音频 → Whisper Large-v3(≈200 万字)。
2. **转录切分**:仅保留 ≥200 字的完整段落,分月归档 (`dataset/2024年05月/*.md` 等)。
3. **语料清洗**:Gemini-2.5-Flash 删除噪声(读评论、重复口癖、背景音乐描述、ASR 错误)。
4. **问法生成**:Gemini-2.5-Flash-Lite 按段生成 3–5 个不同视角、语气提问。
5. **数据库存储**:写入 `raw_dialogues.db` → `train_dialogues`(长回答列表) → `question_answer_table`(问题、回答、模型版本、状态)。
6. **导出**:`train/generate_dataset.py` 过滤 `status=1` 且 `LEN(question)>2` 的行,输出 ChatML JSONL。
#### Who are the source language producers?
- 主体为主播户晨风在直播中的即兴独白,问题由 Gemini-2.5-Flash-Lite 自动生成,再由开发者审核。
## Annotations
### Annotation Process
- 由自动问法生成 + 规则过滤 + 人工抽检。`status` 字段记录是否通过审核,只有通过记录会进入导出的 JSONL。
### Who are the annotators?
- 项目维护者(HuChenFeng 团队)负责审查脚本日志、抽样评估以及剔除不合格的问答对。
## Citation
如果本数据集对你的工作有帮助,请引用本仓库:
```bibtex
@misc{huchenfeng_dialogue_2024,
title = {HuChenFeng Dialogue Dataset},
author = {tinymindkin and contributors},
howpublished = {GitHub repository},
url = {https://github.com/tinymindkin/huchenfeng},
year = {2024}
}
```
## Contributions
- Dataset curators & maintainers: [@tinymindkin](https://github.com/tinymindkin) and HuChenFeng project collaborators.
- 感谢 [Olcmyk/HuChenFeng](https://github.com/Olcmyk/HuChenFeng) 提供完整直播文字稿参考。
---
语言:
- 简体中文
许可证:其他
展示名称:户晨风对话数据集
样本规模分类:
- 50000 < 样本数 < 100000
任务类别:
- 文本生成
任务子类别:
- 对话生成
源数据集:
- 原创
标签:
- 户晨风
---
# 数据集卡片:户晨风对话数据集
## 数据集概览
户晨风对话数据集共收录81060条高质量中文单轮对话样本,每条样本均由1组「用户」提问与一段长篇「主播」回复构成,完整还原了知名主播**户晨风**的口语化表达、情绪起伏与叙事节奏。原始素材源自2023至2025年的直播转录内容,先通过Whisper Large-v3进行语音识别,再经Gemini-2.5-Flash完成降噪清洗,最终使用Gemini-2.5-Flash-Lite为每段回复生成3至5个不同视角的提问。生成的提问与对应原回复经人工与规则联动过滤后,导出为`question_answer.jsonl`(采用ChatML风格的`messages`列表格式),可直接用于监督微调(SFT)、LoRA/QLoRA、角色扮演AI智能体构建等任务。
* **规模**:共计81060组问答对(经Qwen分词器统计约含28亿Token),单条提问平均长度为18.3个中文字符,单条回复平均长度为342.7个中文字符。
* **格式**:采用JSON Lines格式,每行对应一条样本,字段与`transformers`库的ChatML格式保持一致(`user` → `assistant`)。
* **来源**:户晨风2023至2025年[直播转录内容](https://github.com/Olcmyk/HuChenFeng)。
* **用途**:适用于训练具备中文风格迁移能力、长篇回复生成、直播带货口吻或人格化聊天的模型,亦可作为提示词工程与数据合成的参考案例。
## 支持任务与排行榜
- **对话/指令微调**:可用于训练中文问答、角色扮演、对话安全或记忆模块。
- **数据增强**:可为其他中文会话系统提供长篇回复生成示例。
## 语言
- **输入语言**:简体中文(zh-Hans),包含大量口语表达、俚语、幽默用法及中文口头禅。
## 数据集结构
### 样本示例
json
{
"messages": [
{"role": "user", "content": "你觉得现在的大学还有含金量吗?"},
{"role": "assistant", "content": "你读大学,你有点含金量也行,说白了水个学历..."}
]
}
回复通常为1至3段长文本,严格保留主播原始口吻;不同提问可对应同一段回复,以保留多提问视角的效果。
### 数据字段
- `messages` *(List[Dict])*:标准ChatML对话列表,固定长度为2。
- `role` *(str)*:取值为`"user"`或`"assistant"`。
- `content` *(str)*:UTF-8编码中文文本,已去除Markdown格式与表情符号,仅保留原生口语内容。
## 数据采集
### 筛选逻辑
通过公开直播内容构建能够体现主播人格特征、语速特点、逻辑跳跃性等风格化语料,填补中文口语化LoRA/SFT训练数据的缺口。
### 源数据
#### 初始采集与标准化流程
1. **语音转写**:将户晨风2023至2025年的直播音频通过Whisper Large-v3转换为文本(总字数约200万字)。
2. **转录切分**:仅保留长度≥200字的完整段落,并按月归档(如`dataset/2024年05月/*.md`等)。
3. **语料清洗**:使用Gemini-2.5-Flash删除噪声内容(如读评论环节、重复口癖、背景音乐描述、ASR识别错误等)。
4. **提问生成**:通过Gemini-2.5-Flash-Lite为每段回复生成3至5个不同视角、语气的提问。
5. **数据库存储**:将处理后的数据写入`raw_dialogues.db`的`train_dialogues`表(存储长回复列表)与`question_answer_table`表(存储提问、回复、模型版本与审核状态)。
6. **导出**:通过`train/generate_dataset.py`脚本过滤`status=1`且`LEN(question)>2`的条目,输出ChatML格式的JSONL文件。
#### 语料生产者
主体为主播户晨风在直播中的即兴独白,提问由Gemini-2.5-Flash-Lite自动生成后经开发者审核。
## 标注
### 标注流程
采用自动提问生成+规则过滤+人工抽检的三级审核机制。`status`字段用于记录审核结果,仅通过审核的条目才会被纳入最终导出的JSONL文件。
### 标注人员
项目维护者(户晨风团队)负责审查脚本日志、抽样评估并剔除不合格的问答对。
## 引用说明
若本数据集对你的研究工作有所帮助,请引用本仓库:
bibtex
@misc{huchenfeng_dialogue_2024,
title = {HuChenFeng Dialogue Dataset},
author = {tinymindkin and contributors},
howpublished = {GitHub repository},
url = {https://github.com/tinymindkin/huchenfeng},
year = {2024}
}
## 贡献
- 数据集整理与维护者:[@tinymindkin](https://github.com/tinymindkin)及户晨风项目协作成员。
- 感谢[Olcmyk/HuChenFeng](https://github.com/Olcmyk/HuChenFeng)提供完整直播文字稿参考。
提供机构:
alkintin
搜集汇总
数据集介绍
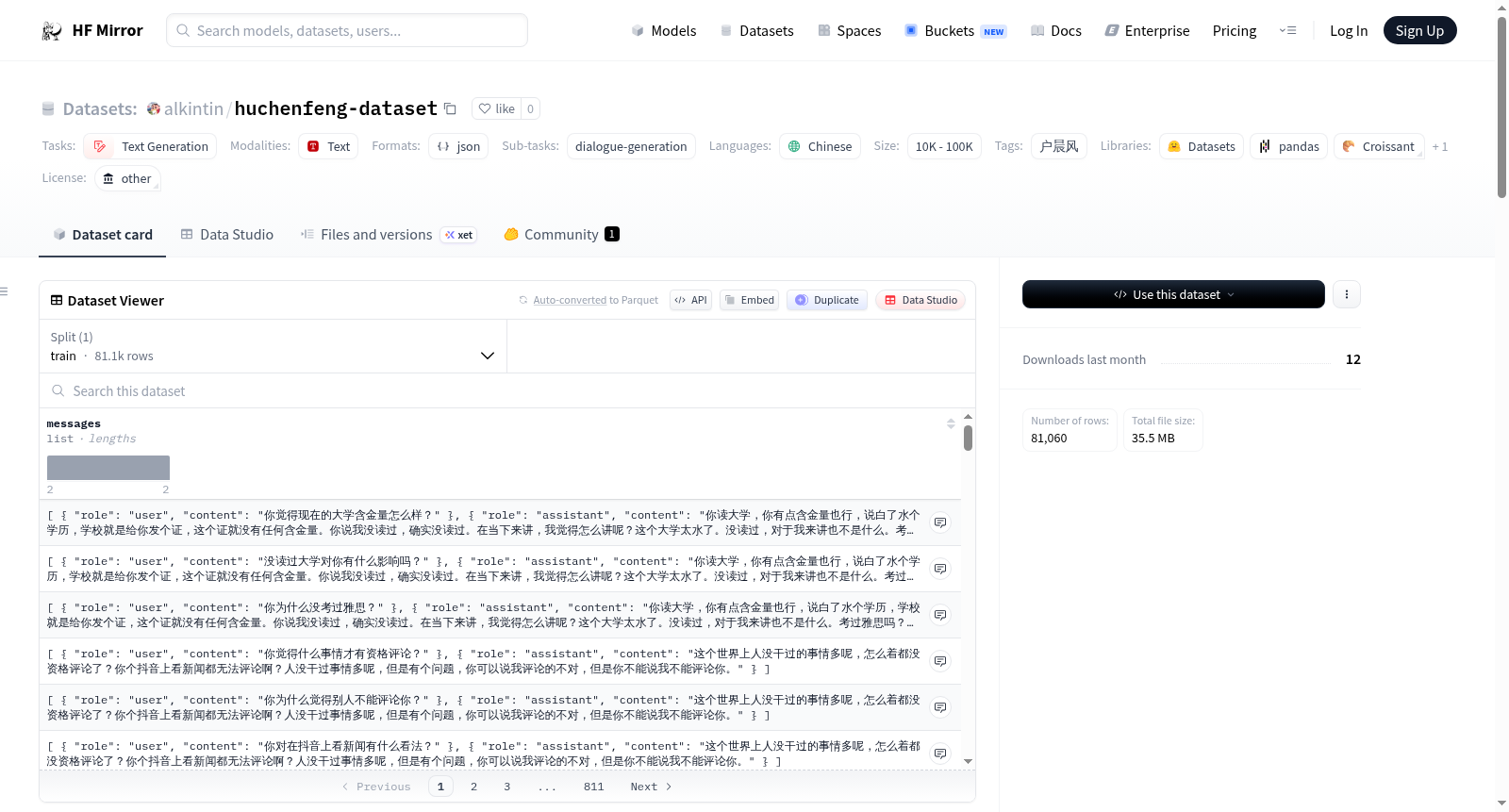
构建方式
在中文口语风格化语料库构建领域,HuChenFeng对话数据集通过系统化的多阶段流程生成。其基础素材源于2023至2025年间知名主播户晨风的公开直播内容,首先经由Whisper Large-v3模型完成高精度语音识别与转录。随后,利用Gemini-2.5-Flash模型对原始文本进行深度清洗,有效剔除了包括背景噪音、重复口癖及自动语音识别错误在内的各类干扰信息。核心构建环节则采用Gemini-2.5-Flash-Lite模型,为每一段清洗后的主播回答自动生成三至五个不同视角与语气的问题,从而形成问答对。最终,通过结合规则过滤与人工抽检的严格审核机制,确保数据质量,并将合格样本以ChatML风格的JSON Lines格式导出,形成可直接用于模型训练的标准化语料。
特点
该数据集的核心特征在于其高度风格化与真实性,完整保留了主播户晨风独特的口语表达、情绪起伏与逻辑跳跃模式,为中文自然语言处理研究提供了稀缺的口语化、人格化语料。数据规模达八万一千余条高质量单轮对话,平均回答长度超过三百四十字,蕴含丰富的长篇连贯表达实例。其格式严格遵循ChatML标准,每条样本由固定的用户提问与助理回答二元结构组成,便于与主流训练框架无缝集成。内容上,数据集涵盖了大量的中文口语、俚语及幽默用法,生动再现了直播场景下的即时互动语境,为训练具备特定风格迁移能力或长文本生成能力的模型提供了坚实基础。
使用方法
该数据集主要应用于对话生成与指令微调等自然语言处理任务。研究者可直接加载JSON Lines格式的文件,其中每条记录包含一个符合ChatML规范的消息列表,即可将其用于监督微调(SFT)或参数高效微调方法(如LoRA/QLoRA)的训练流程。数据集特别适用于开发具有中文口语风格、长篇回答能力或特定角色扮演功能的对话代理。此外,其高质量的长篇回答示例也可作为数据增强的素材,为其他中文对话系统提供风格参考。在实际使用中,开发者需注意数据以简体中文为主且包含大量口语特征,适用于针对相关风格与领域进行模型优化与评估。
背景与挑战
背景概述
在人工智能对话系统蓬勃发展的时代,构建富含特定风格与人格化表达的中文对话数据集,对于推动个性化语言模型的研究与应用具有关键意义。HuChenFeng Dialogue Dataset应运而生,由tinymindkin等研究人员于2024年主导创建,其核心研究问题聚焦于如何从真实直播场景中提取并结构化高质量口语语料,以填补中文风格化监督微调数据的空白。该数据集以知名主播户晨风2023至2025年的直播转录为原始素材,通过先进的语音识别与语言模型技术进行清洗与问题生成,最终形成了包含八万余条问答对的语料库。它不仅为中文角色扮演、长篇回答生成等任务提供了宝贵的资源,也为探索口语化、情绪化语言建模开辟了新的路径,对中文自然语言处理领域,特别是在风格迁移与人格化代理构建方面,产生了积极的推动作用。
当前挑战
该数据集旨在解决的领域核心挑战,在于如何精准建模并复现特定个体的口语风格、情感节奏与逻辑跳跃,以训练出能够生成高度拟人化、风格一致长篇对话的模型。这要求数据不仅内容准确,更需深度捕捉原说话者独特的表达习惯与语境信息。在构建过程中,团队面临多重技术挑战:首先,从非结构化的直播音频到结构化文本的转换,需克服语音识别在嘈杂环境、口语化表达及特定俚语上的识别误差;其次,自动化生成与原始回答语义匹配且角度多元的问题,对生成模型的语境理解与创造力提出了高要求;最后,确保最终语料在去除噪声(如重复口癖、背景描述)的同时,完整保留主播的人格特质与表达精髓,依赖于精细的规则过滤与人工审核流程,这构成了数据质量控制的关键难点。
常用场景
经典使用场景
在自然语言处理领域,HuChenFeng Dialogue Dataset 作为高质量中文口语对话语料,其经典使用场景聚焦于对话生成模型的监督微调。该数据集通过保留主播户晨风独特的口语化表达、情绪起伏与逻辑跳跃,为模型训练提供了富含人格特征的文本范例。研究者常利用其进行风格迁移学习,使生成模型能够模仿特定人物的语言习惯,生成具有鲜明个性色彩的长篇回答,从而在角色扮演、个性化聊天机器人等任务中展现卓越性能。
解决学术问题
该数据集有效解决了中文自然语言处理中风格化语料稀缺的学术难题。传统对话数据集往往缺乏鲜活的口语特征与连贯的长篇表达,而 HuChenFeng 数据集通过转录真实直播内容,并辅以智能清洗与问题生成,构建了大规模、高质量的口语风格语料库。这为研究中文口语理解与生成、对话风格建模、以及数据增强方法提供了坚实的数据基础,推动了人格化对话系统与领域自适应等前沿方向的发展。
衍生相关工作
围绕该数据集,已衍生出多项聚焦于中文风格化对话生成的经典研究工作。例如,基于其进行的 LoRA/QLoRA 高效微调实践,探索了在有限算力下实现模型人格化适配的技术路径。同时,该数据集常被用作评估对话安全性与长文本连贯性的基准数据之一。相关研究进一步探讨了如何从单轮对话中提取并建模说话人的稳定风格特征,为构建具有一致人设的对话代理提供了重要的方法论启示。
以上内容由遇见数据集搜集并总结生成


