FaceCaption-15M, FaceCaptionHQ-4M, HumanCaption-10M, HumanCaption-HQ
收藏github2025-01-15 更新2025-01-20 收录
下载链接:
https://github.com/ddw2AIGROUP2CQUPT/Large-Scale-Multimodal-Face-Datasets
下载链接
链接失效反馈官方服务:
资源简介:
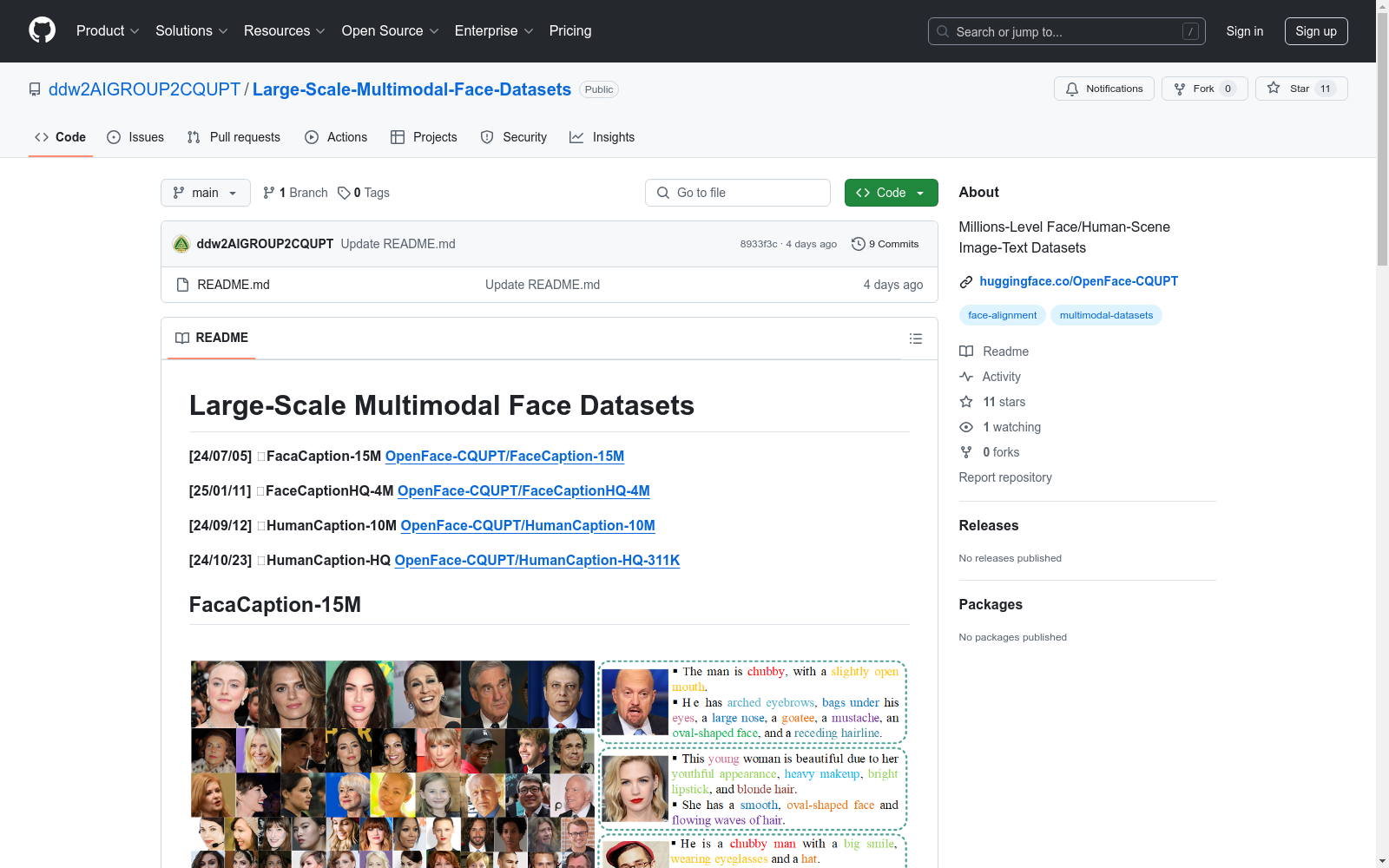
FaceCaption-15M是一个大规模、多样化且高质量的面部图像数据集,附带自然语言描述(面部图像到文本)。该数据集旨在促进面部中心任务的研究。FaceCaption-15M包含超过1500万对的面部图像及其对应的面部特征自然语言描述,是目前最大的面部图像字幕数据集。FaceCaptionHQ-4M包含约400万对从FaceCaption-15M中清理出的面部图像-文本对。HumanCaption-10M是一个大规模、多样化且高质量的人类相关图像数据集,附带自然语言描述(图像到文本)。该数据集旨在促进人类中心任务的研究。HumanCaption-10M包含约1000万张人类相关图像及其对应的面部特征自然语言描述,是FaceCaption-15M的第二代版本。HumanCaption-HQ包含约31.1万张人类相关图像及其对应的自然语言描述。与HumanCaption-10M相比,该数据集不仅包括相关的面部语言描述,还筛选出更高分辨率的图像,并利用GPT-4V的强大视觉理解能力生成更详细和准确的文本描述。
FaceCaption-15M is a large-scale, diverse, and high-quality facial image dataset paired with natural language descriptions for facial image-to-text tasks. It aims to advance research in face-centric tasks. FaceCaption-15M contains over 15 million facial image-text pairs with corresponding natural language descriptions of facial features, making it the largest facial image captioning dataset to date. FaceCaptionHQ-4M includes approximately 4 million curated facial image-text pairs filtered from FaceCaption-15M. HumanCaption-10M is a large-scale, diverse, and high-quality human-centric image dataset paired with natural language descriptions for image-to-text tasks, designed to promote research in human-centric tasks. It contains roughly 10 million human-related images paired with corresponding natural language descriptions of facial features, and is the second-generation iteration of FaceCaption-15M. HumanCaption-HQ includes approximately 311,000 human-related images paired with corresponding natural language descriptions. Compared with HumanCaption-10M, this dataset not only covers relevant facial language descriptions, but also screens out higher-resolution images, and leverages the powerful visual understanding capabilities of GPT-4V to generate more detailed and accurate textual descriptions.
创建时间:
2025-01-15
原始信息汇总
大规模多模态人脸数据集概述
数据集列表
-
FaceCaption-15M
- 描述: 一个大规模、多样化且高质量的人脸图像数据集,包含超过1500万对人脸图像及其对应的自然语言描述(人脸图像到文本)。该数据集旨在促进以人脸为中心的任务研究。
- 特点:
- 包含1500万对人脸图像和文本描述。
- 是目前最大的人脸图像描述数据集。
- 更新:
- 2024年9月1日,发布了FaceCaption-15M的图像嵌入。
-
FaceCaptionHQ-4M
- 描述: 包含约400万对人脸图像-文本对,这些数据是从FaceCaption-15M中清理出来的。
- 特点:
- 数据经过清理,质量更高。
- 包含400万对人脸图像和文本描述。
-
HumanCaption-10M
- 描述: 一个大规模、多样化且高质量的人类相关图像数据集,包含约1000万张人类相关图像及其对应的自然语言描述(图像到文本)。该数据集旨在促进以人类为中心的任务研究。
- 特点:
- 包含1000万张人类相关图像和文本描述。
- 是FaceCaption-15M的第二代版本。
-
HumanCaption-HQ
- 描述: 包含约31.1万张人类相关图像及其对应的自然语言描述。与HumanCaption-10M相比,该数据集不仅包含相关的面部语言描述,还筛选出更高分辨率的图像,并利用GPT-4V的强大视觉理解能力生成更详细和准确的文本描述。
- 特点:
- 包含31.1万张人类相关图像和文本描述。
- 用于第二阶段训练HumanVLM,增强模型在描述生成和视觉理解方面的能力。
数据集链接
搜集汇总
数据集介绍
构建方式
FaceCaption-15M、FaceCaptionHQ-4M、HumanCaption-10M和HumanCaption-HQ数据集的构建基于大规模的多模态数据收集与处理。FaceCaption-15M作为基础数据集,包含了超过1500万张面部图像及其对应的自然语言描述,涵盖了丰富的面部特征。FaceCaptionHQ-4M则通过对FaceCaption-15M进行清洗和筛选,保留了约400万对高质量的面部图像-文本对。HumanCaption-10M进一步扩展了数据范围,包含了约1000万张与人类相关的图像及其描述,是FaceCaption-15M的升级版本。HumanCaption-HQ则通过筛选高分辨率图像,并利用GPT-4V的强大视觉理解能力生成更详细的文本描述,形成了约31.1万对高质量的人类相关图像-文本对。
特点
这些数据集的特点在于其规模庞大、多样性丰富且质量高。FaceCaption-15M是目前最大的面部图像描述数据集,涵盖了广泛的面部特征和自然语言描述。FaceCaptionHQ-4M则在FaceCaption-15M的基础上进行了优化,确保了数据的质量。HumanCaption-10M进一步扩展了数据范围,涵盖了更多与人类相关的图像及其描述。HumanCaption-HQ则通过高分辨率图像和GPT-4V生成的详细描述,提供了更高质量的图像-文本对,适用于更精细的视觉理解和描述生成任务。
使用方法
这些数据集的使用方法主要集中在面部和人类相关的视觉任务研究中。FaceCaption-15M和FaceCaptionHQ-4M可用于面部图像描述生成、面部识别等任务的研究。HumanCaption-10M和HumanCaption-HQ则适用于更广泛的人类相关视觉任务,如人体姿态估计、行为识别等。用户可以通过Hugging Face平台获取这些数据集,并利用其提供的图像嵌入和文本描述进行模型训练和评估。HumanCaption-HQ还可用于增强模型在描述生成和视觉理解方面的能力,特别是在高分辨率图像和详细文本描述的场景下。
背景与挑战
背景概述
FaceCaption-15M、FaceCaptionHQ-4M、HumanCaption-10M和HumanCaption-HQ是由OpenFace-CQUPT团队开发的一系列大规模多模态人脸数据集,旨在推动人脸相关任务的研究。FaceCaption-15M作为该系列的首个数据集,于2024年发布,包含超过1500万对人脸图像及其自然语言描述,成为迄今为止最大规模的人脸图像描述数据集。随后发布的FaceCaptionHQ-4M、HumanCaption-10M和HumanCaption-HQ进一步优化了数据质量,扩展了研究范围。这些数据集不仅为人脸识别、图像生成和自然语言处理等任务提供了丰富的资源,还通过引入GPT-4V等先进技术,提升了数据描述的准确性和多样性。
当前挑战
这些数据集在构建和应用过程中面临多重挑战。首先,数据规模庞大且多样性要求高,如何在保证数据质量的同时实现高效的数据清洗和标注是一个关键问题。其次,自然语言描述与图像之间的对齐需要高度精确,尤其是在人脸特征描述中,细微的差异可能导致模型理解的偏差。此外,数据集的构建还依赖于先进的视觉理解技术,如GPT-4V,这对计算资源和算法优化提出了更高要求。最后,如何将这些数据集有效应用于实际任务,如提升模型的视觉理解和生成能力,仍需进一步探索和验证。
常用场景
经典使用场景
FaceCaption-15M、FaceCaptionHQ-4M、HumanCaption-10M和HumanCaption-HQ数据集在计算机视觉和自然语言处理领域具有广泛的应用。这些数据集最经典的使用场景包括面部图像与自然语言描述的匹配任务,例如面部图像生成、面部特征识别以及基于文本的面部图像检索。通过提供大规模、高质量的面部图像与文本描述对,这些数据集为研究人员提供了丰富的实验材料,推动了多模态学习技术的发展。
解决学术问题
这些数据集解决了多模态学习中的关键问题,例如如何将视觉信息与自然语言描述进行有效对齐,以及如何生成高质量的面部图像描述。通过提供大规模的面部图像与文本对,研究人员能够训练更强大的模型,提升面部识别、图像生成和文本生成任务的性能。此外,这些数据集还为跨模态检索、面部属性分析和情感识别等研究提供了重要支持,推动了计算机视觉与自然语言处理的深度融合。
衍生相关工作
基于这些数据集,研究人员开发了一系列经典的多模态学习模型和应用。例如,HumanVLM模型利用HumanCaption-HQ数据集进行训练,显著提升了视觉理解和描述生成的能力。此外,这些数据集还催生了大量关于面部图像生成、跨模态检索和自然语言描述生成的研究工作,推动了多模态学习领域的前沿发展。相关研究成果在顶级会议和期刊上广泛发表,进一步扩大了这些数据集的影响力。
以上内容由遇见数据集搜集并总结生成


