OmniBench
收藏Hugging Face2024-09-24 更新2024-12-12 收录
下载链接:
https://huggingface.co/datasets/m-a-p/OmniBench
下载链接
链接失效反馈官方服务:
资源简介:
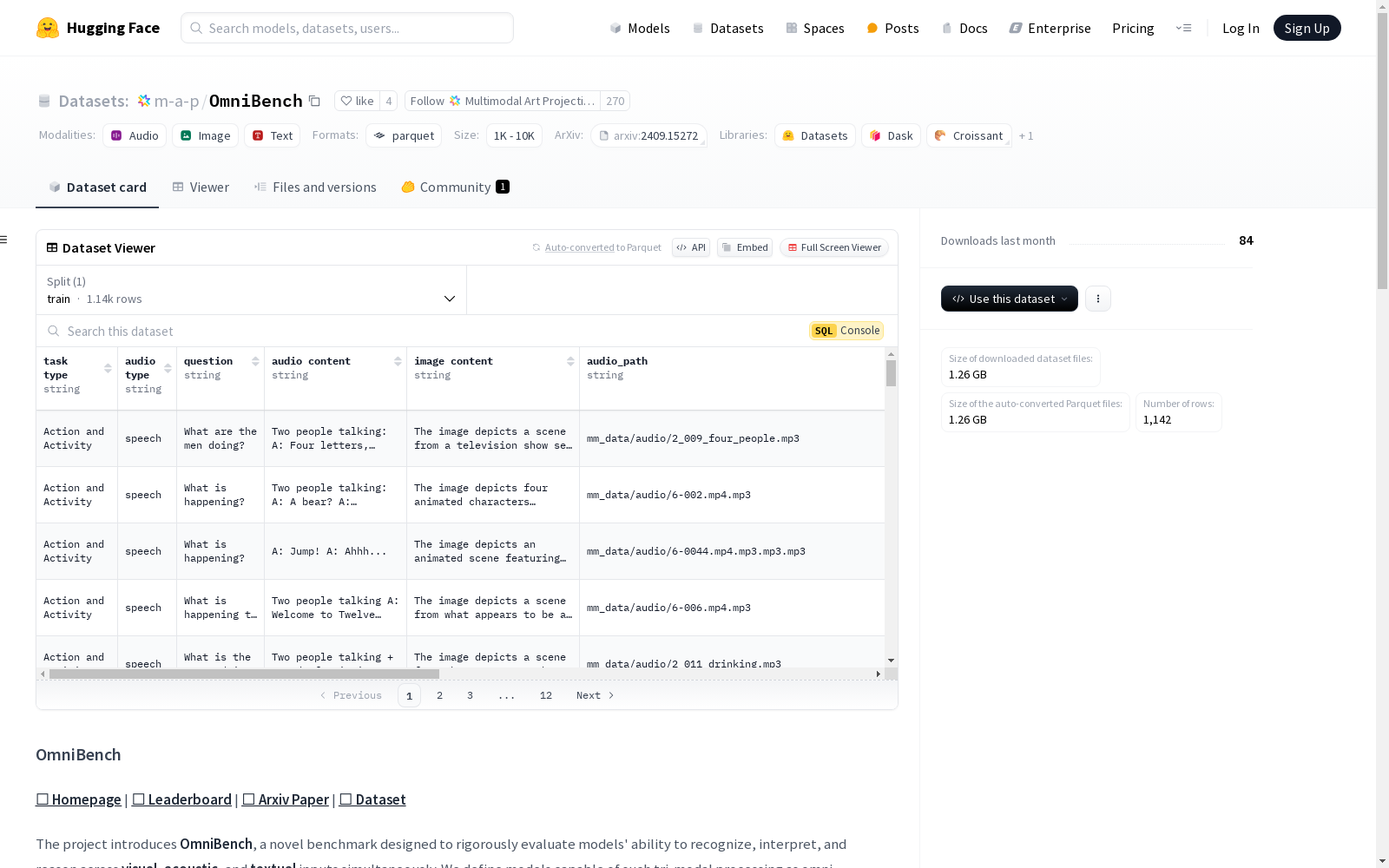
OmniBench数据集是一个多模态基准测试数据集,用于评估模型在视觉、声学和文本输入上的综合处理能力。数据集包含以下特征:任务类型(字符串,表示7种任务类型之一)、音频类型(字符串,表示3种音频类型之一)、问题(字符串,表示问题内容)、选项(字符串列表,表示多选题的四个选项)、答案(字符串,表示正确答案,必须在选项中)、音频路径(字符串,音频文件的基本名称,使用时需前置'mm_data/audio')、图像路径(字符串,图像文件的基本名称,使用时需前置'mm_data/image')、音频内容(字符串,用于文本替代实验的人工注释音频转录)、图像内容(字符串,用于文本替代实验的VLM生成的图像描述)。此外,数据集还包含音频和图像的实际内容,分别以numpy数组和PIL.Image对象的形式存储。数据集分为训练集,包含1142个样本。
The OmniBench dataset is a multimodal benchmark dataset developed to evaluate the comprehensive processing capabilities of models across visual, acoustic, and textual inputs. It includes the following features: task type (string, one of seven predefined task types), audio type (string, one of three predefined audio types), question (string, the content of the query), options (list of strings, four options for multiple-choice questions), answer (string, the correct answer that must be included in the provided options), audio path (string, the base filename of the audio file, with the prefix 'mm_data/audio' required for access), image path (string, the base filename of the image file, with the prefix 'mm_data/image' required for access), audio content (string, manually annotated audio transcripts used for text substitution experiments), and image content (string, image descriptions generated by VLM for text substitution experiments). Additionally, the dataset contains the actual audio and image data, which are stored as numpy arrays and PIL.Image objects respectively. The dataset is divided into a training set comprising 1142 samples.
提供机构:
Multimodal Art Projection
创建时间:
2024-09-24
原始信息汇总
OmniBench 数据集概述
数据集信息
特征
- task type: 字符串,表示任务类型。
- audio type: 字符串,表示音频类型(语音、声音事件、音乐)。
- question: 字符串,表示问题。
- audio content: 字符串,表示音频内容的转录文本。
- image content: 字符串,表示图像内容的描述文本。
- audio_path: 字符串,表示音频文件路径的基名。
- image_path: 字符串,表示图像文件路径的基名。
- index: 整数,表示问题ID。
- answer: 字符串,表示正确答案,必须在
options中出现。 - options: 字符串序列,表示多选题的四个选项。
- audio: 音频数据,包含wav文件的numpy数组(仅适用于HF版本)。
- image: 图像数据,包含
PIL.Image()对象(仅适用于HF版本)。
数据分割
- train: 训练集,包含1142个样本,大小为1228472891.864字节。
数据集大小
- 下载大小: 1263570029字节
- 数据集大小: 1228472891.864字节
数据集配置
- config_name: default
- data_files:
- split: train
- path: data/train-*
- data_files:
数据集下载
python from datasets import load_dataset
dataset = load_dataset("m-a-p/OmniBench")
检查数据样本
print(dataset) print(dataset[train][0])
搜集汇总
数据集介绍
构建方式
OmniBench数据集的构建旨在评估模型在视觉、听觉和文本输入上的多模态处理能力。该数据集通过整合多种任务类型和音频类型,生成了包含问题、选项、答案、音频路径和图像路径的丰富样本。每个样本均经过精心设计,确保涵盖不同的音频类型(如语音、声音事件和音乐)和任务类型,以全面测试模型的跨模态推理能力。
特点
OmniBench数据集的特点在于其多模态特性,涵盖了视觉、听觉和文本三种输入形式。数据集中的每个样本均包含问题、选项、答案、音频内容和图像内容,且音频和图像均以路径或直接数据形式提供。此外,数据集还提供了人类标注的音频转录文本和视觉语言模型生成的图像描述,为研究多模态替代实验提供了丰富资源。
使用方法
OmniBench数据集可通过HuggingFace平台直接加载,使用`load_dataset`函数即可获取数据集。加载后,用户可通过索引访问样本,查看问题、选项、答案、音频和图像等内容。音频和图像数据以numpy数组和PIL图像对象形式提供,便于直接用于模型训练和评估。此外,数据集还支持多模态替代实验,用户可利用音频转录文本和图像描述进行文本替代研究。
背景与挑战
背景概述
OmniBench数据集由Yizhi Li等研究人员于2024年提出,旨在评估模型在视觉、听觉和文本输入上的多模态处理能力。该数据集的核心研究问题是如何构建一个能够同时处理图像、音频和文本信息的通用语言模型(OLMs)。OmniBench的推出标志着多模态人工智能研究的一个重要里程碑,为研究者提供了一个标准化的基准,以评估和比较不同模型在复杂多模态任务中的表现。该数据集的影响力不仅体现在其多模态任务的多样性上,还在于其推动了多模态模型在实际应用中的发展。
当前挑战
OmniBench数据集面临的挑战主要体现在两个方面。首先,多模态数据的融合与理解是一个复杂的任务,模型需要同时处理图像、音频和文本信息,并从中提取出有意义的关联。这种跨模态的信息整合对模型的架构和训练方法提出了极高的要求。其次,数据集的构建过程中,如何确保不同模态数据之间的对齐与一致性也是一个技术难题。例如,音频与图像的同步标注、文本与视觉信息的匹配等,都需要精确的人工干预和自动化技术的支持。这些挑战不仅考验了数据集的构建质量,也对模型的泛化能力和鲁棒性提出了更高的要求。
常用场景
经典使用场景
OmniBench数据集主要用于评估模型在处理视觉、听觉和文本输入时的多模态理解能力。通过提供包含图像、音频和文本问题的任务,该数据集能够全面测试模型在跨模态信息融合和推理方面的表现。经典使用场景包括多模态问答、音频-图像联合理解以及跨模态推理任务。
衍生相关工作
基于OmniBench数据集,研究者们开发了多种多模态模型,如UnifiedIO2系列和Gemini-1.5-Pro等。这些模型在跨模态任务中表现出色,推动了多模态人工智能技术的进步。此外,该数据集还激发了多模态预训练模型的研究,为后续的多模态基准测试和模型优化提供了重要参考。
数据集最近研究
最新研究方向
在人工智能领域,多模态学习正逐渐成为研究热点,OmniBench数据集的推出为这一领域提供了全新的评估基准。该数据集通过结合视觉、听觉和文本输入,旨在评估模型在跨模态识别、解释和推理方面的能力。近年来,随着大模型技术的快速发展,OmniBench为研究者提供了一个标准化的平台,用于测试和比较不同模型在多模态任务中的表现。特别是在音频与图像结合的复杂场景中,OmniBench的数据结构为模型的多模态融合能力提供了丰富的实验场景。当前,基于该数据集的研究主要集中在提升模型在跨模态任务中的泛化能力和鲁棒性,尤其是在低资源环境下的表现。此外,OmniBench还为多模态大模型的预训练和微调提供了新的思路,推动了多模态学习在自然语言处理、计算机视觉和音频处理等领域的交叉应用。
以上内容由遇见数据集搜集并总结生成


