Polish Medical Exams
收藏arXiv2024-12-01 更新2024-12-06 收录
下载链接:
https://huggingface.co/spaces/amu-cai/Polish_Medical_Exams
下载链接
链接失效反馈官方服务:
资源简介:
波兰医学考试数据集(Polish Medical Exams)是由亚当·密茨凯维奇大学创建的一个用于跨语言医学知识转移评估的新基准数据集。该数据集包含超过24,000道从波兰医学考试中心和首席医学委员会公开资源中网络爬取的考试题目,涵盖了医学和牙科的执照考试及专业考试。部分题目还包括高质量的人工翻译的英语版本,便于进行跨语言分析。数据集的创建旨在评估大型语言模型在医学领域的性能,特别是其在波兰语和英语医学考试中的表现,以解决跨语言和领域特定理解的问题。
The Polish Medical Exams dataset is a novel benchmark dataset created by Adam Mickiewicz University for cross-lingual medical knowledge transfer evaluation. It contains over 24,000 exam questions crawled from public resources of the Polish Medical Examinations Center and the Chief Medical Council, covering licensing and professional examinations for medicine and dentistry. Some questions also include high-quality manually translated English versions to facilitate cross-lingual analysis. The dataset is designed to evaluate the performance of large language models (LLMs) in the medical domain, particularly their performance in Polish and English medical examinations, to address issues related to cross-lingual and domain-specific understanding.
提供机构:
亚当·密茨凯维奇大学
创建时间:
2024-12-01
搜集汇总
数据集介绍
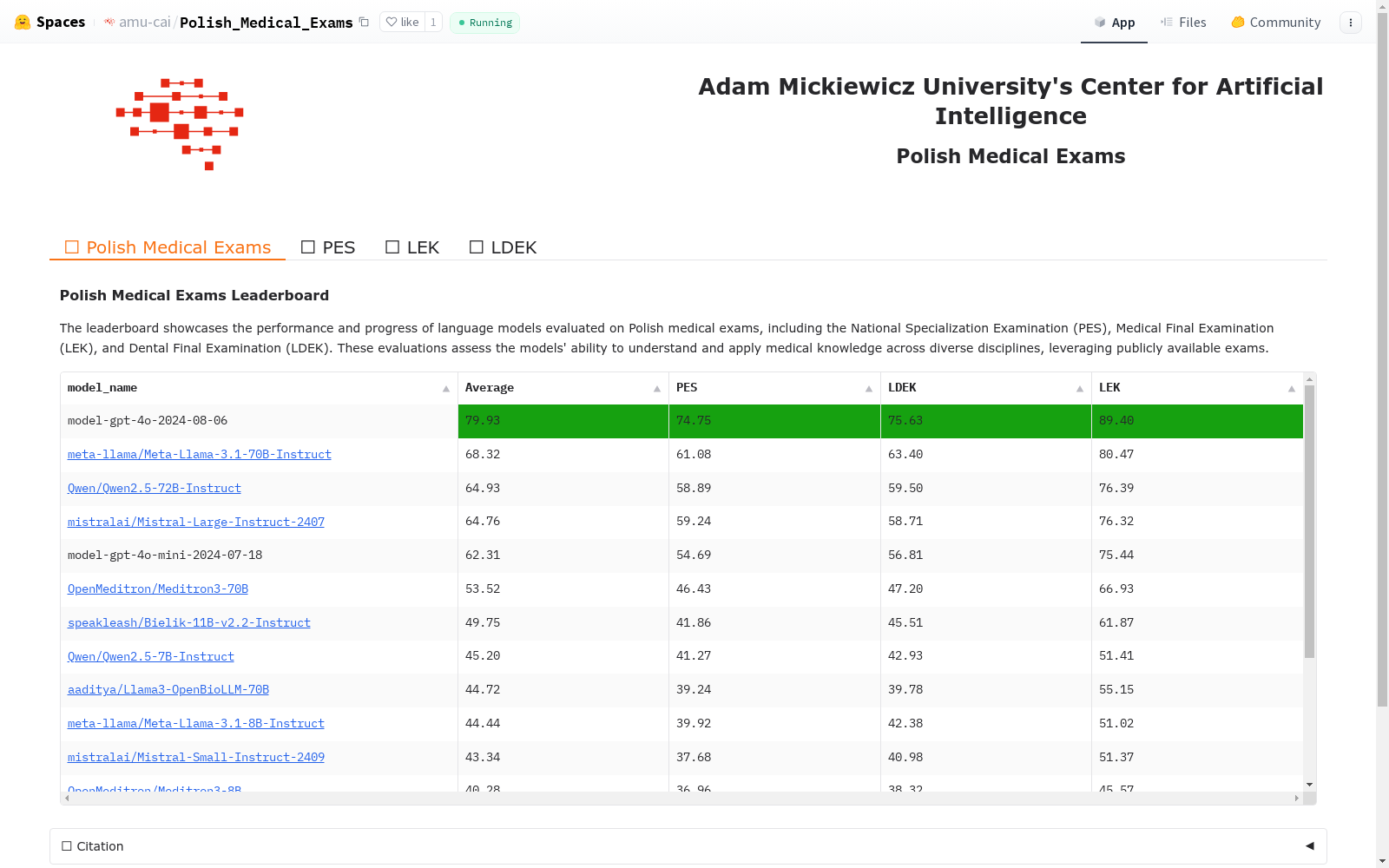
构建方式
波兰医学考试数据集(Polish Medical Exams)是通过网络爬虫从波兰医学考试中心和首席医学委员会提供的公开资源中构建的。该数据集包含了超过24,000道考试题目,涵盖了波兰医学执照和专业考试(LEK, LDEK, PES)。部分题目还包括了波兰语和英语的平行语料,其中英语部分由考试中心专业翻译,供外国考生使用。通过从这些现有的考试题目中创建结构化的基准数据集,研究者系统地评估了包括通用、领域特定和波兰语特定的大型语言模型(LLMs),并将其性能与人类医学生进行了比较。
特点
波兰医学考试数据集的一个显著特点是其包含了大量波兰语和英语的平行语料,这为跨语言医学知识转移评估提供了宝贵的资源。此外,数据集的构建基于真实的医学考试题目,确保了内容的实用性和专业性。数据集还涵盖了多个医学专业领域,包括内科、外科、儿科等,为评估模型在不同医学专业中的表现提供了全面的数据支持。
使用方法
波兰医学考试数据集主要用于评估大型语言模型在医学领域的性能,特别是跨语言知识转移的能力。研究者可以通过该数据集比较不同模型在波兰语和英语考试题目上的表现,分析模型在不同医学专业中的优劣。此外,该数据集还可用于训练和微调专注于波兰语医学领域的语言模型,以提高其在实际医学考试中的应用效果。
背景与挑战
背景概述
波兰医学考试数据集(Polish Medical Exams)由亚当·米茨凯维奇大学(Adam Mickiewicz University)的研究人员于近期创建,旨在评估大型语言模型(LLMs)在跨语言医学知识转移中的表现。该数据集基于波兰医学执照和专业考试(LEK, LDEK, PES),涵盖了超过24,000道考试题目,其中部分题目提供了波兰语和英语的平行语料。通过这一结构化的基准数据集,研究者系统地评估了包括通用、领域特定和波兰语特定模型在内的多种LLMs,并将其表现与人类医学生进行了比较。研究发现,尽管如GPT-4等模型在某些领域接近人类表现,但在跨语言翻译和领域特定理解方面仍存在显著挑战。
当前挑战
波兰医学考试数据集面临的挑战主要包括两个方面:一是解决跨语言知识转移的问题,即模型在处理非英语医学内容时的表现;二是构建过程中遇到的挑战,如数据获取和处理的复杂性。数据集的构建涉及从公开资源中网络爬取大量考试题目,并确保这些题目的准确性和与当前医学知识的契合度。此外,模型在处理特定医学领域的专业知识时,如牙科和儿科,表现出了明显的不足,这表明现代LLMs在捕捉这些领域的细微差别方面仍有待提高。
常用场景
经典使用场景
波兰医学考试数据集(Polish Medical Exams)主要用于跨语言医学知识转移评估。该数据集包含超过24,000道医学考试题目,涵盖了波兰医学执照和专业考试(LEK, LDEK, PES)的内容。经典使用场景包括评估大型语言模型(LLMs)在处理波兰语医学考试题目时的表现,特别是与英语版本的对比分析。通过这种跨语言的评估,研究者可以深入了解模型在不同语言环境下的性能差异,从而为多语言医学知识转移提供有力支持。
解决学术问题
该数据集解决了在医学领域中跨语言知识转移的学术研究问题。由于大多数研究集中在英语语言环境中,波兰医学考试数据集的引入填补了这一空白,使得研究者能够评估和比较不同语言环境下大型语言模型的表现。这不仅有助于揭示模型在多语言环境中的局限性,还强调了在临床实践中部署LLMs时需要考虑的伦理和性能问题。通过系统地评估和比较不同模型的表现,该数据集为跨语言医学知识转移提供了重要的实证依据。
衍生相关工作
波兰医学考试数据集的引入催生了一系列相关研究工作。例如,研究者利用该数据集对GPT-4等大型语言模型进行了深入评估,揭示了这些模型在处理波兰语医学考试题目时的性能表现。此外,该数据集还促进了跨语言医学知识转移的研究,推动了多语言医学数据集的开发和应用。相关工作还包括对模型在不同医学专业考试中的表现进行细分分析,以及探讨语言和文化因素对模型性能的影响。这些衍生研究为医学领域的语言模型应用提供了宝贵的理论和实证支持。
以上内容由遇见数据集搜集并总结生成


