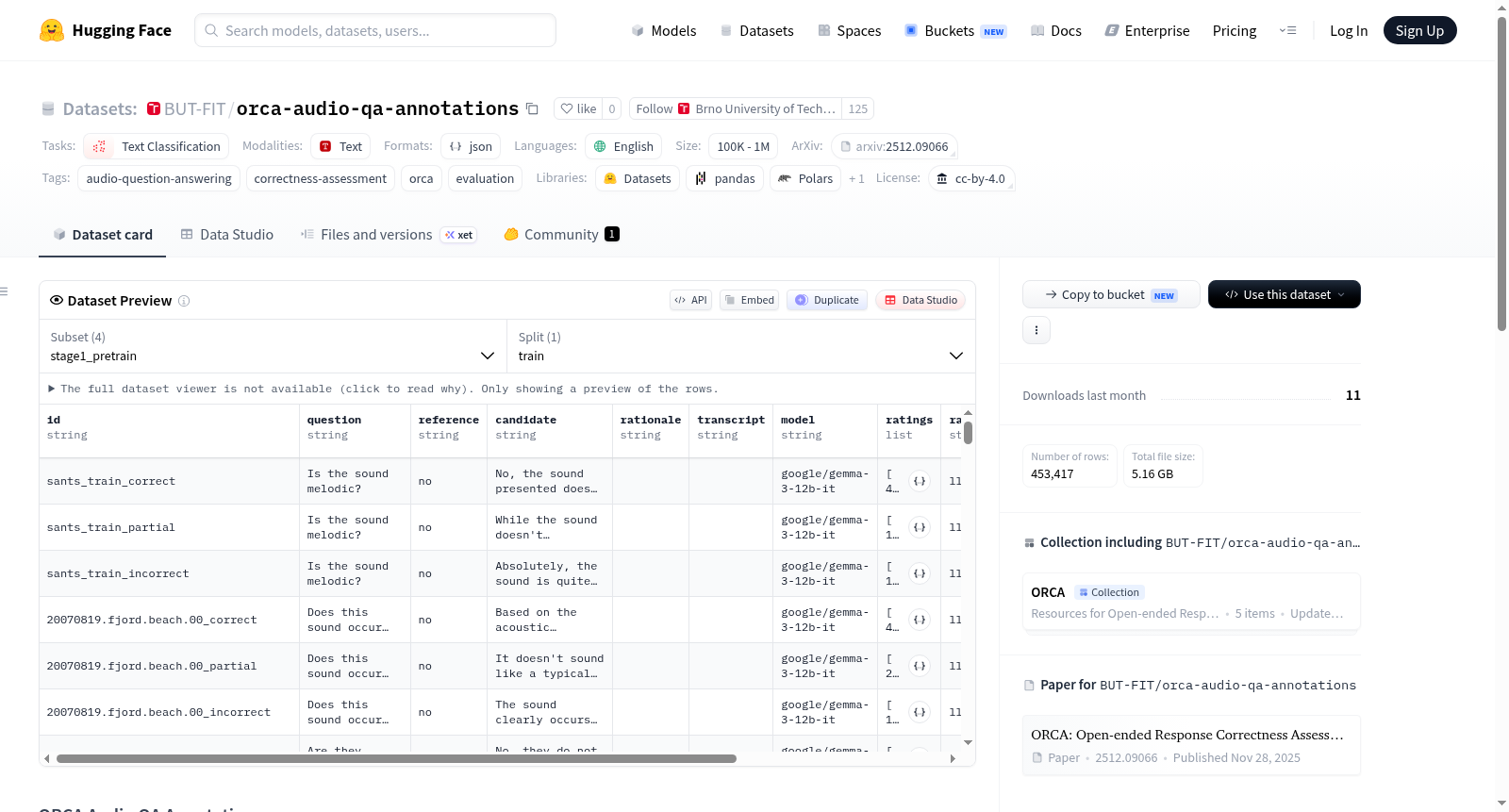
orca-audio-qa-annotations
收藏数据集概述
数据集名称: ORCA Audio QA Annotations
许可协议: CC-BY 4.0
语言: 英语
任务类别: 文本分类
数据集规模: 1M < n < 10M
数据集描述
该数据集用于训练和评估 ORCA(Open-ended Response Correctness Assessment) 模型,这是一个针对音频问答任务的开式回答正确性评分模型。ORCA 采用三阶段课程训练策略,每阶段对应一个或多个数据文件。
数据集配置与文件
| 配置名称 | 文件名称 | 样本数量 | 数据来源 |
|---|---|---|---|
stage1_pretrain |
s1-synthetic-qa-ratings.jsonl |
5,332,242 | 50 个 LLM 评委 |
stage2_benchmark |
s2-mmau-mmar-llm-judge-ratings.jsonl |
449,730 | 5 个 LLM 评委 |
stage3_mmau_mmar |
s3-mmau-mmar-human-judge-ratings.jsonl |
2,447 | 人类标注员 |
stage3_mmau_pro |
s3-mmau-pro-human-judge-ratings.jsonl |
1,240 | 人类标注员 |
相关资源
- 论文: ORCA: Open-ended Response Correctness Assessment for Audio Question Answering — 已被 TACL 2026 接受
- 代码、模型与使用说明: github.com/BUTSpeechFIT/ORCA
引用
bibtex @article{sedlacek-etal-2026-orca, title={ORCA: Open-ended Response Correctness Assessment for Audio Question Answering}, author={Sedl{a}v{c}ek, v{S}imon and Barahona, Sara and Bola~{n}os, Cecilia and Herrera-Alarc{o}n, Laura and Udupa, Sathvik and L{o}pez, Fernando and Ferner, Allison and Lozano-Diez, Alicia and Yusuf, Bolaji and Kesiraju, Santosh and Duraiswami, Ramani and v{C}ernock{y}, Jan}, howpublished={Accepted to Transactions of the Association for Computational Linguistics}, year={2026}, url={https://arxiv.org/abs/2512.09066} }