TTS-SCFChilSC
收藏Hugging Face2025-04-26 更新2025-04-27 收录
下载链接:
https://huggingface.co/datasets/MatrixStudio/TTS-SCFChilSC
下载链接
链接失效反馈官方服务:
资源简介:
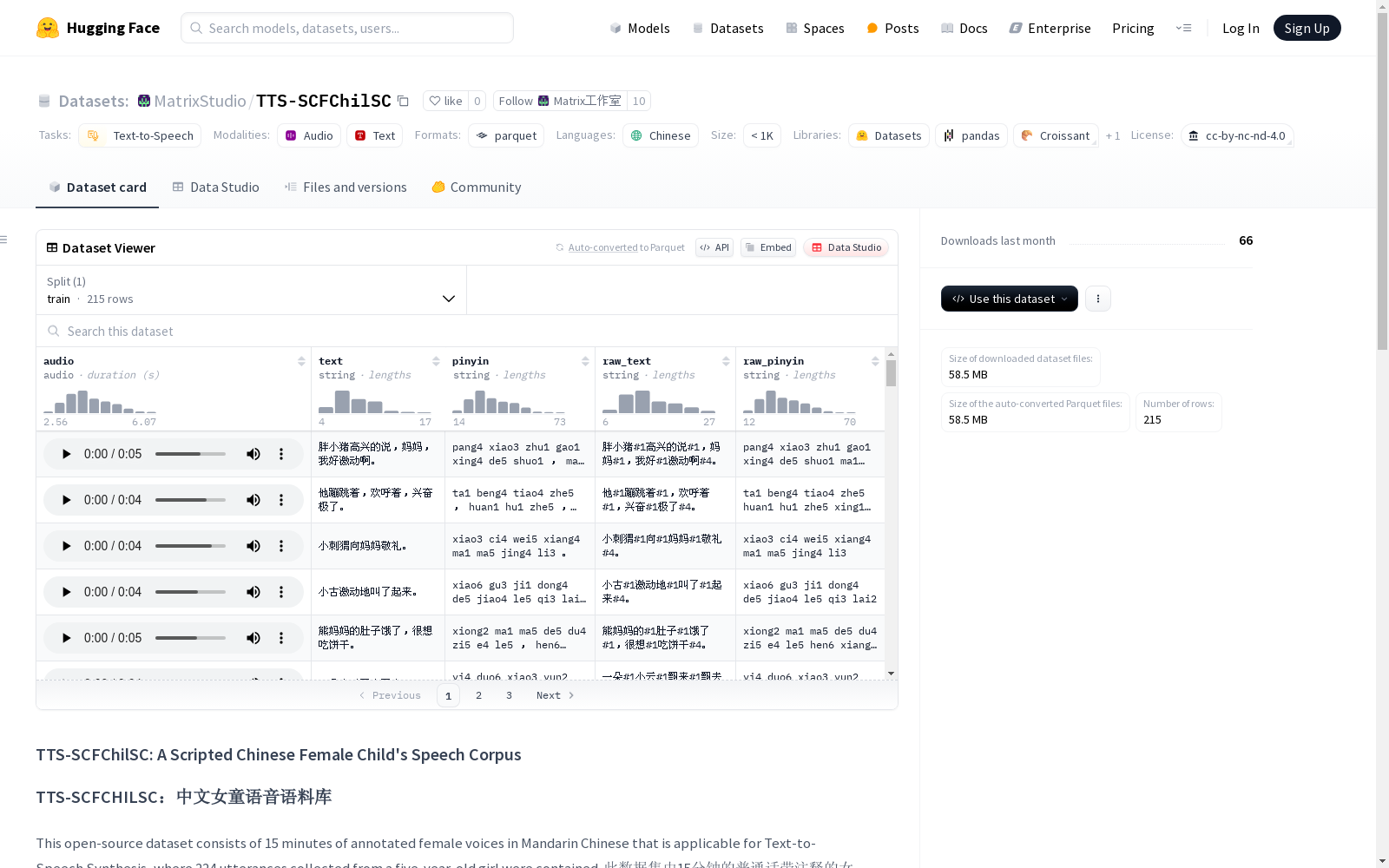
TTS-SCFChilSC是一个开源的数据集,包含15分钟的普通话注释女声语音,适用于语音合成。该数据集包含了一名5岁女孩的224条中文普通话语音,内容包括日常用语、寓言和故事。音频参数为44.1 kHz,16位,单声道。文件格式为WAV(PCM)和TXT(UTF-8)。录音设备为Philips K38003,录音环境为安静的室内环境。
TTS-SCFChilSC is an open-source dataset designed for speech synthesis. It contains 15 minutes of annotated Mandarin female speech, including 224 utterances in Mandarin Chinese from a 5-year-old girl, with content covering daily expressions, fables and stories. The audio specifications are 44.1 kHz, 16-bit, and single-channel. The supported file formats are WAV (PCM) and TXT (UTF-8). The recordings were made using a Philips K38003 device in a quiet indoor environment.
创建时间:
2025-04-24
搜集汇总
数据集介绍
构建方式
该数据集通过专业录音设备在安静室内环境下采集,由一名五岁女童朗读日常用语、寓言故事等文本内容,形成224条标准普通话语音样本。音频采用44.1kHz采样率、16位深度的单声道WAV格式存储,同步标注文本内容及拼音信息,构建过程严格遵循语音语料库的学术规范。
特点
作为专注于儿童语音合成的专业数据集,其核心价值在于收录了纯净的女童音色特征,包含215条涵盖日常生活与文学内容的语音样本。技术层面呈现44.1kHz高保真音质,配套文本标注采用UTF-8编码的TXT文件,原始拼音标注为研究汉语儿童发音规律提供了独特视角。
使用方法
研究者可通过HuggingFace平台直接加载数据集,利用audio字段获取波形数据,text与pinyin字段实现端到端语音合成模型的训练。特别适用于儿童语音合成、发音特征分析等研究场景,原始文本与拼音的双重标注支持多模态学习任务。使用时需注意遵守CC-BY-NC-ND 4.0许可协议。
背景与挑战
背景概述
TTS-SCFChilSC数据集是由Magic Data Technology构建的中文女童语音语料库,专注于为文本到语音合成(TTS)领域提供高质量的儿童语音数据资源。该数据集收录了224条由一名五岁女童朗读的普通话语音样本,涵盖日常用语、寓言和故事等内容,采样率为44.1kHz,16位深度,单声道格式。作为儿童语音合成领域的重要资源,该数据集填补了中文儿童语音数据稀缺的空白,为儿童语音合成系统的开发与优化提供了关键支持。
当前挑战
在儿童语音合成领域,TTS-SCFChilSC数据集面临的主要挑战包括儿童语音的声学特性与成人差异显著,如更高的基频和更宽的共振峰范围,这为声学建模带来了技术难度。数据构建过程中,儿童发音的不稳定性和录音环境的控制也是重要挑战,需确保语音质量的一致性和清晰度。此外,数据规模有限(仅15分钟)可能限制模型的泛化能力,需通过数据增强等技术手段加以弥补。
常用场景
经典使用场景
在语音合成技术领域,TTS-SCFChilSC数据集以其独特的女童语音样本成为研究儿童语音合成的关键资源。该数据集广泛应用于构建儿童语音合成系统,特别是在需要模拟自然童声的交互式应用中,如教育机器人、有声读物和儿童智能助手。其高质量的录音和详尽的标注为模型训练提供了坚实基础。
衍生相关工作
围绕该数据集已产生多项重要研究成果,包括基于深度学习的儿童语音克隆系统、跨年龄语音转换模型等。Magic Data Technology团队后续开发的儿童语音合成框架直接采用了本数据集作为基准测试集,相关论文在INTERSPEECH等国际会议上获得广泛关注。
数据集最近研究
最新研究方向
随着语音合成技术的快速发展,儿童语音合成逐渐成为研究热点。TTS-SCFChilSC数据集作为专门针对中文女童语音的语料库,为儿童语音合成领域提供了宝贵的数据支持。近年来,该数据集被广泛应用于基于深度学习的语音合成模型训练,特别是在生成自然流畅的儿童语音方面取得了显著进展。研究者们利用该数据集探索了儿童语音特有的声学特征,如高频成分更丰富、基频更高等特点,为改进语音合成系统的自然度和表现力提供了重要依据。同时,该数据集也在多模态交互系统、智能教育助手等应用中展现出巨大潜力,推动了儿童友好型语音技术的发展。
以上内容由遇见数据集搜集并总结生成


