EMMA
收藏Hugging Face2025-01-10 更新2025-01-11 收录
下载链接:
https://huggingface.co/datasets/luckychao/EMMA
下载链接
链接失效反馈官方服务:
资源简介:
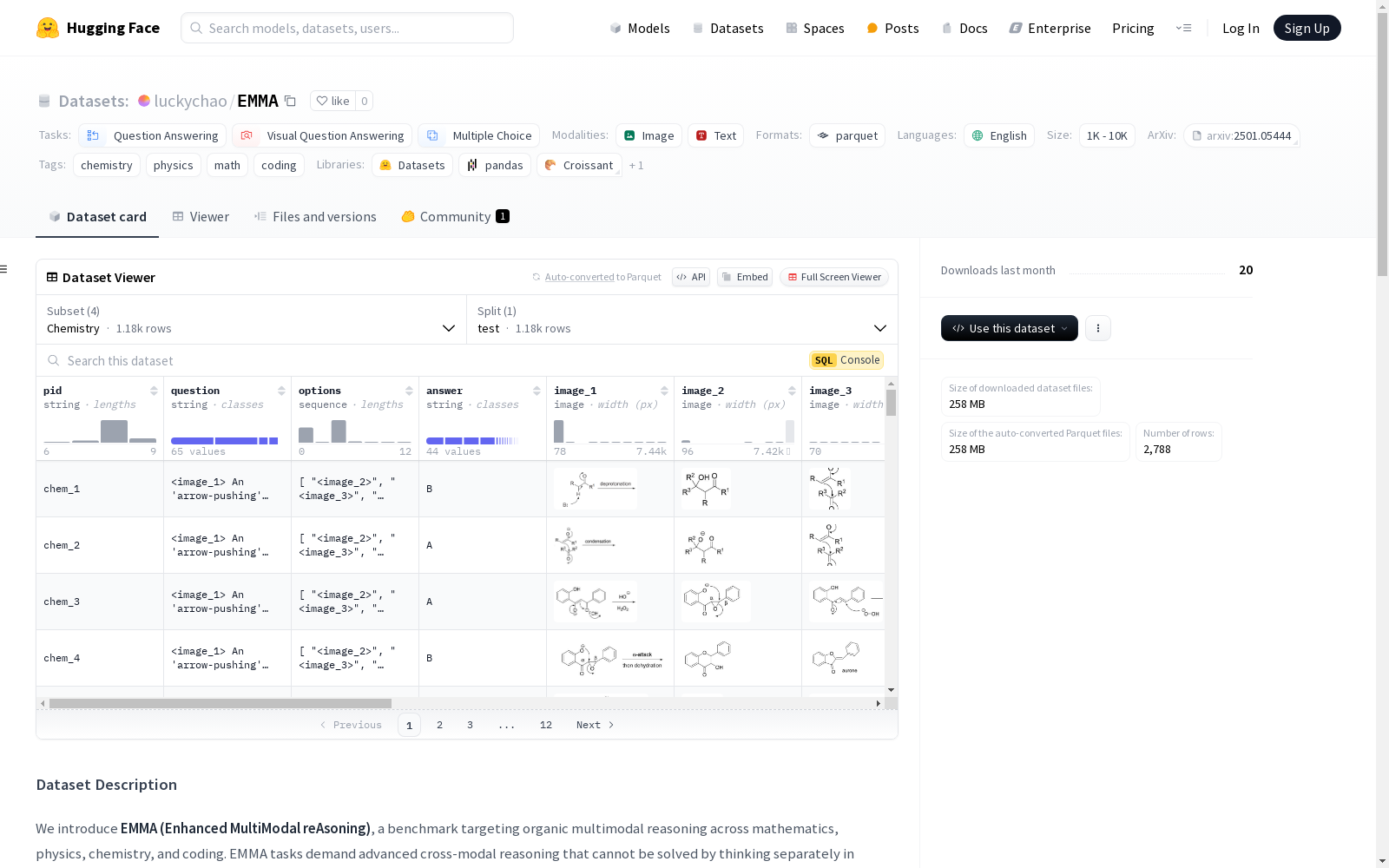
我们引入了**EMMA(增强型多模态推理)**,这是一个针对数学、物理、化学和编程领域的有机多模态推理的基准。EMMA任务需要高级的跨模态推理,不能通过单独思考每个模态来解决,为MLLMs的推理能力提供了一个增强的测试套件。EMMA由2,788个问题组成,其中1,796个是新构建的,涵盖四个领域。在每个学科中,我们进一步根据每个问题所测量的具体技能提供细粒度的标签。
We introduce **EMMA (Enhanced Multimodal Reasoning)**, a benchmark for organic multimodal reasoning across the domains of mathematics, physics, chemistry, and programming. EMMA tasks demand advanced cross-modal reasoning that cannot be resolved by independently reasoning over each single modality, thereby serving as an enhanced test suite for evaluating the reasoning capabilities of Multimodal Large Language Models (MLLMs). EMMA consists of 2,788 questions, 1,796 of which are newly developed and span the four aforementioned domains. For each discipline, we further assign fine-grained labels based on the specific skills that each question is intended to assess.
创建时间:
2025-01-09
搜集汇总
数据集介绍
构建方式
EMMA数据集通过整合数学、物理、化学和编程四个领域的多模态问题,构建了一个包含2,788个问题的基准测试集。其中1,796个问题为新构建,其余则来自现有数据集。每个问题均经过精细标注,涵盖问题类型、任务类别、所需技能等多个维度,确保数据集的多样性和复杂性。数据集的构建过程注重跨模态推理能力的评估,旨在为多模态大语言模型(MLLMs)提供更具挑战性的测试环境。
特点
EMMA数据集的核心特点在于其多模态性质,每个问题不仅包含文本描述,还配备了多达五张相关图像,要求模型具备跨模态推理能力。此外,数据集提供了详细的解题步骤、背景知识和问题分类信息,便于研究者深入分析模型的推理过程。数据集涵盖的领域广泛,问题类型多样,包括选择题和开放式问题,能够全面评估模型在不同任务中的表现。
使用方法
EMMA数据集的使用方法简便,用户可通过Hugging Face的`datasets`库直接加载数据。以数学领域为例,使用`load_dataset`函数即可加载测试集。数据集以jsonl格式提供,包含问题ID、问题文本、选项、正确答案、图像、解题步骤等丰富信息。用户可通过自动评估脚本对模型性能进行量化评估,具体方法可参考GitHub仓库中的说明。数据集的设计旨在支持多模态推理研究,适用于模型训练、评估和对比分析。
背景与挑战
背景概述
EMMA(Enhanced MultiModal reAsoning)数据集是一个专注于跨模态推理的基准测试,涵盖数学、物理、化学和编程四个领域。该数据集由Yunzhuo Hao等研究人员于2025年提出,旨在评估多模态大语言模型(MLLMs)在复杂跨模态任务中的推理能力。EMMA包含2,788个问题,其中1,796个为新构建的问题,每个问题都标注了其所需的特定技能。该数据集的推出为多模态推理研究提供了新的测试平台,推动了相关领域的发展。
当前挑战
EMMA数据集面临的挑战主要体现在两个方面。首先,跨模态推理任务要求模型能够同时处理文本和图像信息,并从中提取有效关联,这对模型的综合能力提出了极高要求。其次,数据集的构建过程中,如何确保问题的多样性和复杂性,以及如何准确标注每个问题所需的技能,都是构建团队需要克服的难题。此外,数据集的规模较大,如何高效存储和分发数据也是一个技术挑战。
常用场景
经典使用场景
EMMA数据集在跨模态推理领域具有显著的应用价值,尤其在数学、物理、化学和编程等学科中。该数据集通过结合文本和图像信息,要求模型进行复杂的多模态推理,从而评估和提升多模态大语言模型(MLLMs)的推理能力。经典使用场景包括多模态问答任务,模型需要同时理解文本问题和相关图像信息,以生成准确的答案。
实际应用
在实际应用中,EMMA数据集可用于开发智能教育系统,帮助学生在多学科领域中进行高效学习。例如,通过分析学生在多模态问题中的表现,系统可以提供个性化的学习建议。此外,该数据集还可用于开发智能助手,帮助用户解决复杂的跨模态问题,如编程调试或科学实验设计。
衍生相关工作
EMMA数据集的发布催生了一系列相关研究工作,特别是在多模态推理模型的优化和评估方面。基于该数据集的研究成果包括改进的多模态融合算法、跨模态注意力机制以及针对特定学科的多模态推理模型。这些工作不仅提升了模型的性能,还为多模态推理领域提供了新的研究方向。
以上内容由遇见数据集搜集并总结生成


