UEval
收藏arXiv2026-01-30 更新2026-02-02 收录
下载链接:
https://zlab-princeton.github.io/UEval
下载链接
链接失效反馈官方服务:
资源简介:
UEval是由普林斯顿大学团队构建的多模态生成评估基准,包含1000个专家精选的跨8类现实任务的问题,要求模型同时生成图像和文本回答。数据集涵盖科学图解、学术图表、生活指南等多样场景,每个问题配有人工验证的评分标准(共10417条),支持细粒度自动评估。其创新性在于采用基于量规的评估框架,通过前沿多模态大模型生成初始标准后经专家修订,解决了开放域多模态生成难以量化评估的难题,为统一模型的复杂推理和跨模态协调能力提供了标准化测试平台。
UEval is a multimodal generation evaluation benchmark developed by a team from Princeton University. It comprises 1,000 expert-selected questions spanning 8 categories of real-world tasks, requiring models to generate both image and text responses. The dataset covers diverse scenarios including scientific illustrations, academic charts, and daily life guides. Each question is paired with manually verified scoring criteria (totaling 10,417 entries), enabling fine-grained automatic evaluation. Its core innovation lies in the adoption of a rubric-based evaluation framework: initial criteria are generated by state-of-the-art multimodal large language models and then revised by domain experts, addressing the long-standing challenge of quantifiable evaluation for open-domain multimodal generation. This benchmark provides a standardized test platform for evaluating unified models' capabilities in complex reasoning and cross-modal coordination.
提供机构:
普林斯顿大学
创建时间:
2026-01-30
原始信息汇总
UEval: 统一多模态生成基准数据集概述
数据集基本信息
- 数据集名称: UEval
- 核心内容: 一个包含1,000个专家精心策划提示的基准,要求模型输出同时包含图像和文本。
- 数据来源: 来自8个不同的现实世界领域。
- 创建机构: 普林斯顿大学
- 相关论文: 《UEval: A Benchmark for Unified Multimodal Generation》
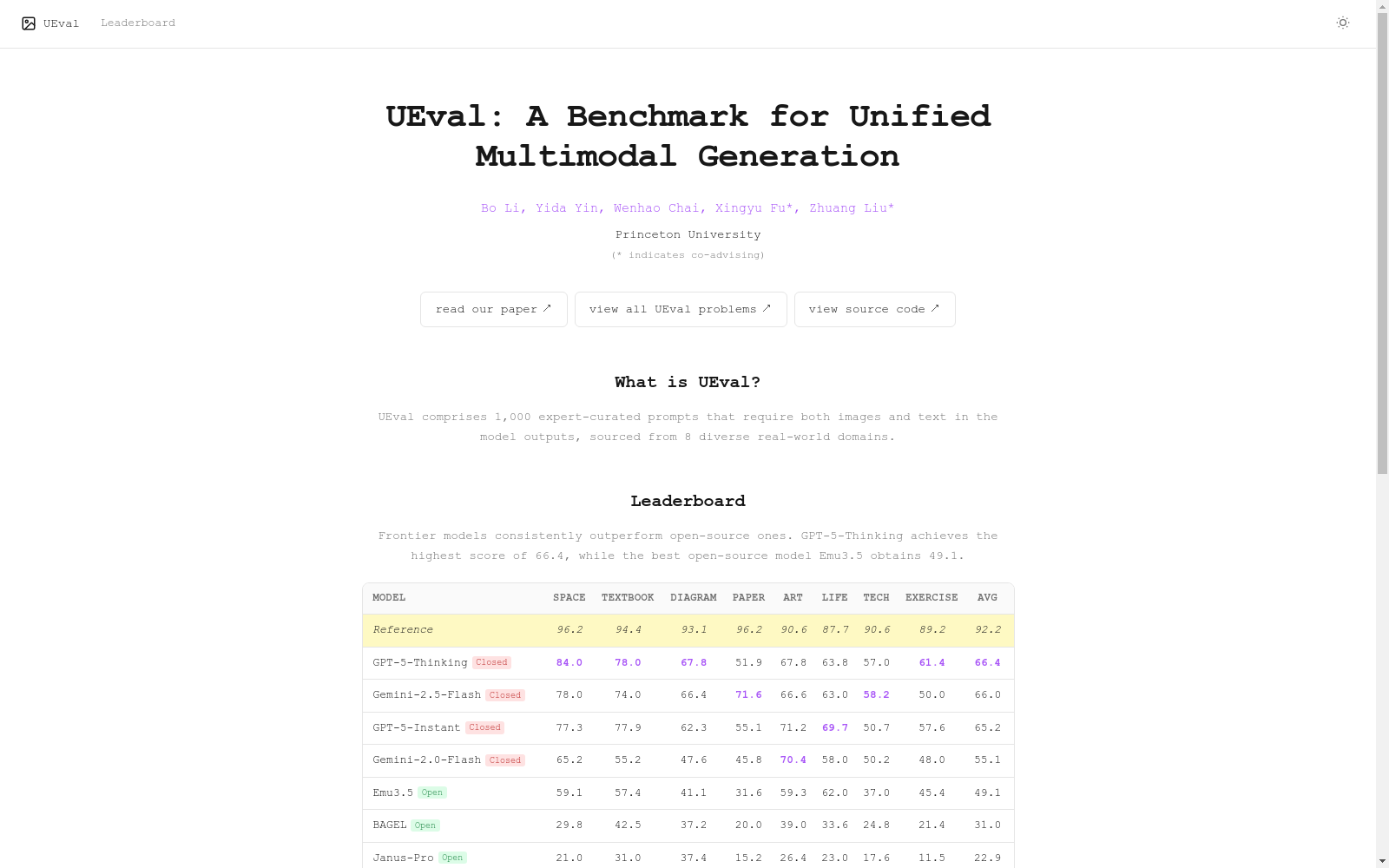
排行榜概览
- 最高分模型: GPT-5-Thinking (66.4分)
- 最佳开源模型: Emu3.5 (49.1分)
- 参考分数: 92.2分
- 总体趋势: 前沿模型持续优于开源模型。
模型性能详情(按领域平均分)
| 模型 | Space | Textbook | Diagram | Paper | Art | Life | Tech | Exercise | 平均分 |
|---|---|---|---|---|---|---|---|---|---|
| Reference | 96.2 | 94.4 | 93.1 | 96.2 | 90.6 | 87.7 | 90.6 | 89.2 | 92.2 |
| GPT-5-Thinking (Closed) | 84.0 | 78.0 | 67.8 | 51.9 | 67.8 | 63.8 | 57.0 | 61.4 | 66.4 |
| Gemini-2.5-Flash (Closed) | 78.0 | 74.0 | 66.4 | 71.6 | 66.6 | 63.0 | 58.2 | 50.0 | 66.0 |
| GPT-5-Instant (Closed) | 77.3 | 77.9 | 62.3 | 55.1 | 71.2 | 69.7 | 50.7 | 57.6 | 65.2 |
| Gemini-2.0-Flash (Closed) | 65.2 | 55.2 | 47.6 | 45.8 | 70.4 | 58.0 | 50.2 | 48.0 | 55.1 |
| Emu3.5 (Open) | 59.1 | 57.4 | 41.1 | 31.6 | 59.3 | 62.0 | 37.0 | 45.4 | 49.1 |
| BAGEL (Open) | 29.8 | 42.5 | 37.2 | 20.0 | 39.0 | 33.6 | 24.8 | 21.4 | 31.0 |
| Janus-Pro (Open) | 21.0 | 31.0 | 37.4 | 15.2 | 26.4 | 23.0 | 17.6 | 11.5 | 22.9 |
| Show-o2 (Open) | 25.4 | 33.1 | 33.2 | 17.4 | 25.6 | 15.6 | 17.4 | 13.1 | 22.6 |
| MMaDA (Open) | 10.8 | 20.0 | 14.2 | 13.3 | 15.7 | 15.8 | 12.4 | 12.6 | 14.4 |
评估领域
数据集涵盖以下8个评估领域:Space, Textbook, Diagram, Paper, Art, Life, Tech, Exercise。
快速开始
-
安装依赖:
pip install google-genai datasets pillow -
设置API密钥:
export GEMINI_API_KEY="your-api-key" -
运行评估脚本: bash python ueval_eval.py --model_output_path your_outputs.json --output_path results.json
-
完整文档: 参见GitHub。
引用信息
bibtex @article{li2026ueval, title = {UEval: A Benchmark for Unified Multimodal Generation}, author = {Li, Bo and Yin, Yida and Chai, Wenhao and Fu, Xingyu and Liu, Zhuang}, journal = {arXiv preprint arXiv:2601.22155}, year = {2026} }
搜集汇总
数据集介绍
构建方式
在统一多模态生成评估领域,UEval数据集通过专家精心策划的构建流程脱颖而出。该数据集包含来自八个现实世界任务的一千个问题,这些问题均要求模型输出同时包含图像和文本。构建过程中,首先为每个问题手动收集参考图像和文本答案,随后利用前沿的多模态大语言模型基于问题和参考答案生成初步的评分准则。为确保评估的精确性与可靠性,人类专家对这些自动生成的准则进行了细致的审查与优化,最终形成了总计10,417条经过验证的细粒度评分标准,从而为开放式多模态生成任务提供了可扩展且精细化的自动评估框架。
特点
UEval数据集的核心特点在于其针对统一多模态生成模型的深度评估能力。与以往侧重于单一模态理解或生成的基准不同,它要求模型对复杂查询进行跨模态推理,并协同生成图像和自然语言响应。数据集涵盖封闭式与开放式两大类任务,前者注重事实性理解与基于证据的解释,后者则侧重于需要多步规划与视觉一致性的技能指导。其创新的基于准则的评分体系,能够对模型输出的图像与文本进行多维度、细粒度的自动化评估,有效捕捉了真实场景中语言与视觉交互的丰富性,对当前最先进的模型也构成了显著挑战。
使用方法
使用UEval数据集进行评估时,研究者需将待测统一模型在数据集的一千个问题上进行推理与生成。评估过程采用数据依赖的准则评分法:对于每个问题,一个指定的多模态大语言模型法官(如Gemini-2.5-Pro)会依据预先定义好的细粒度评分准则,对模型生成的图像和文本响应进行逐一核对与打分。最终得分是满足的准则数量占总准则数量的比例。这种方法替代了传统的人力评分,实现了高效、可复现的自动化评估。研究显示,该评估框架与人类判断具有高度一致性,为衡量模型在复杂多模态生成任务上的性能提供了稳健的基准。
背景与挑战
背景概述
随着多模态人工智能技术的飞速发展,统一多模态模型逐渐成为研究热点,这类模型旨在单一系统中集成视觉理解与生成能力。然而,现有评估基准多局限于视觉问答或文本到图像生成等单一任务,未能充分衡量模型在需要同时生成图像与文本的复杂真实场景下的表现。为此,普林斯顿大学的研究团队于2026年推出了UEval基准,该基准包含来自八个现实任务的1000个专家精心设计的问题,要求模型输出兼具图像与文本的答案,以评估统一模型在开放环境下的多模态生成与推理能力。UEval的提出填补了该领域标准化评估工具的空白,为模型能力的全面衡量提供了重要依据。
当前挑战
UEval基准致力于解决统一多模态生成这一核心领域问题的评估挑战,其首要难点在于如何对开放式的、需要联合图像与文本生成的复杂回答进行客观、细粒度的自动化评分。传统基于大型语言模型的评判方法难以捕捉多模态输出的微妙差异。为此,UEval创新性地引入了基于量规的评分系统,通过前沿多模态大模型生成初始评估标准,再经人工专家验证与细化,最终构建了包含超过一万条验证标准的量规库,以实现可扩展的精细自动评分。在数据集构建过程中,挑战同样显著:如何从多样化的真实任务中收集和构建高质量的问题与参考答案对,确保其覆盖广泛的推理类型;以及如何设计有效的流程,使生成的大量评估量规既具备样本特异性,又能保持评判的一致性与可靠性,这些都对数据集的构建提出了高标准要求。
常用场景
经典使用场景
在统一多模态模型评估领域,UEval数据集被广泛应用于衡量模型在复杂多模态生成任务中的综合性能。该数据集通过涵盖空间、教科书、图表、论文、艺术、生活、技术和运动等八个现实世界任务,构建了1000个专家精心设计的问题,要求模型同时生成图像和文本以回应查询。其经典使用场景包括评估模型在需要图文并茂解释的学术概念阐述、多步骤视觉指南生成以及基于真实场景的推理应答等方面的能力,为研究者提供了一个标准化、可扩展的测试平台,以系统比较不同统一模型在开放性和封闭性任务上的表现。
实际应用
在实际应用层面,UEval数据集为开发能够处理现实世界多模态交互的智能系统提供了关键评估工具。其任务设计紧密贴合教育、科研、日常生活等场景,例如在学术写作中辅助生成解释性图表,在技能教学中创建分步骤视觉指南,或在文化遗产解说中提供图文并茂的说明。通过评估模型在这些任务上的表现,开发者能够识别现有系统的局限性,如多图像生成中的时序不一致问题,从而指导模型优化方向。该数据集的高效评估框架也降低了人工评分成本,为产业界快速迭代多模态生成产品提供了可靠的质量检验标准。
衍生相关工作
UEval数据集的发布促进了多模态评估领域的系列经典工作。其基于量规的评估方法启发了后续研究如VDC等基准在数据依赖性评分方面的改进。数据集揭示的推理模型优势(如GPT-5-Thinking)与非推理模型差距,引发了关于思维链机制在多模态生成中迁移效应的深入探讨,相关研究开始探索如何将推理轨迹有效整合到生成过程中。同时,UEval提供的细粒度任务分类和评分标准为后续统一模型(如Emu3.5、BAGEL等)的性能对比提供了基础,推动了模型在跨任务泛化能力和多步骤规划一致性方面的优化竞赛。
以上内容由遇见数据集搜集并总结生成


