ds4sd/SynthTabNet_OTSL
收藏Hugging Face2023-08-31 更新2024-03-04 收录
下载链接:
https://hf-mirror.com/datasets/ds4sd/SynthTabNet_OTSL
下载链接
链接失效反馈官方服务:
资源简介:
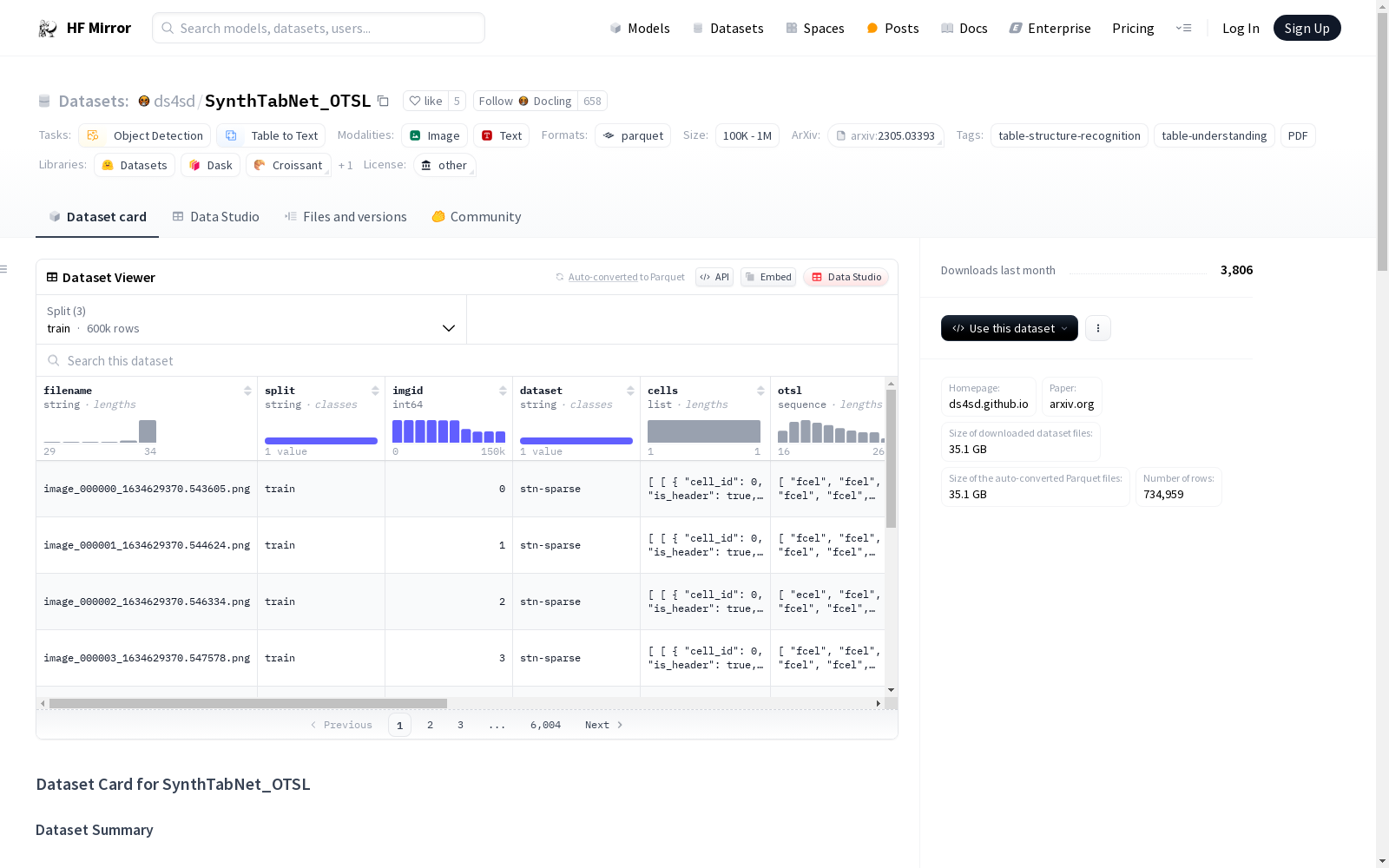
该数据集是将原始的SynthTabNet转换为OTSL格式,用于表格结构识别任务。数据集包含四个部分,每个部分有150k个表格,总计600k个表格。每个部分根据表格的外观、大小、结构和内容进行划分,并分为训练集、测试集和验证集。数据集的结构包括单元格内容、OTSL格式、HTML结构、恢复的HTML、列数、行数和图像。OTSL词汇表定义了不同类型的单元格标记。数据集由IBM Research的Deep Search团队转换和维护。
This dataset is constructed by converting the original SynthTabNet dataset into OTSL format for table structure recognition tasks. The dataset consists of four subsets, each containing 150k tables, with a total of 600k tables. Each subset is partitioned based on table appearance, size, structure and content, and is further split into training, test, and validation sets. The dataset includes cell content, OTSL-formatted data, HTML structure, recovered HTML, column count, row count, and corresponding table images. The OTSL vocabulary defines various types of cell tokens. This dataset was converted and is maintained by the Deep Search Team at IBM Research.
提供机构:
ds4sd
原始信息汇总
数据集卡片 for SynthTabNet_OTSL
数据集描述
数据集概述
SynthTabNet_OTSL 数据集是原始 SynthTabNet 数据集的转换版本,采用了我们论文中提出的 OTSL 格式。该数据集包括原始注释以及新的添加内容。SynthTabNet 分为 4 部分,每部分包含 150k 张表格(总共 600k 张)。每部分根据表格的大小、结构、样式和内容的不同进行分类,并分为训练、测试和验证集。
| 外观样式 | 记录数 |
|---|---|
| Fintabnet | 150k |
| Marketing | 150k |
| PubTabNet | 150k |
| Sparse | 150k |
数据集结构
- cells: 原始数据集单元格的地面真实内容。
- otsl: 新的简化表格结构令牌格式。
- html: 原始数据集的地面真实 HTML(结构)。
- html_restored: 从 OTSL 生成的 HTML。
- cols: 网格列长度。
- rows: 网格行长度。
- image: PIL 图像。
OTSL 词汇表
OTSL: 新的简化表格结构令牌格式。更多关于 OTSL 表格结构格式及其概念的信息可以从我们的论文中阅读。该数据集的格式扩展了论文中提出的工作,并引入了轻微的修改:
- "fcel" - 包含内容的单元格
- "ecel" - 空的单元格
- "lcel" - 向左看的单元格(处理水平合并的单元格)
- "ucel" - 向上看的单元格(处理垂直合并的单元格)
- "xcel" - 2D 跨度单元格,在本数据集中 - 覆盖合并单元格的整个区域
- "nl" - 新行令牌
数据分割
数据集提供了三个分割:
trainvaltest
附加信息
数据集策展人
该数据集由 IBM Research 的 Deep Search 团队 转换。
策展人:
- Maksym Lysak, @maxmnemonic
- Ahmed Nassar, @nassarofficial
- Christoph Auer, @cau-git
- Nikos Livathinos, @nikos-livathinos
- Peter Staar, @PeterStaar-IBM
引用信息
bib @misc{lysak2023optimized, title={Optimized Table Tokenization for Table Structure Recognition}, author={Maksym Lysak and Ahmed Nassar and Nikolaos Livathinos and Christoph Auer and Peter Staar}, year={2023}, eprint={2305.03393}, archivePrefix={arXiv}, primaryClass={cs.CV} }
搜集汇总
数据集介绍
构建方式
SynthTabNet_OTSL数据集是由IBM Research的Deep Search团队基于原始SynthTabNet数据集,按照其在论文《Optimized Table Tokenization for Table Structure Recognition》中提出的OTSL格式进行转换而成的。该数据集包含四部分,每部分有15万张表格,总计60万张。这些表格在大小、结构、风格和内容上具有不同的外观特征,并被划分为训练集、验证集和测试集。
特点
该数据集的特点在于引入了OTSL(Optimized Table Structure Tokenization)格式,这是一种新的简化的表格结构标记格式。OTSL通过使用特定的标记来表示表格中的不同单元格类型,例如内容单元格、空单元格、左右合并单元格、上下合并单元格以及二维跨度单元格等,从而优化了表格结构的识别。此外,数据集提供了原始数据集的单元格标注、HTML结构标注以及从OTSL生成的HTML。
使用方法
使用SynthTabNet_OTSL数据集时,研究者可以访问三种数据划分:训练集、验证集和测试集。数据集的结构包括单元格内容标注、OTSL格式的标注、原始HTML结构标注、从OTSL恢复的HTML、列数、行数以及PIL图像。用户可以根据自己的研究需求,选择相应的数据划分和标注类型进行模型训练和评估。
背景与挑战
背景概述
SynthTabNet_OTSL数据集源于IBM Research的Deep Search团队,其创建旨在推进表格结构识别领域的研究。该数据集是在2023年通过对原始SynthTabNet的转换而构建,包含60万张表格,分为四个部分,每部分具有不同的外观风格。数据集的核心研究问题是优化表格的标记化过程,以提升表格结构识别的准确性。该数据集的构建对表格理解领域产生了重要影响,为相关研究提供了丰富的实验资源。
当前挑战
数据集构建过程中的挑战主要包括:如何有效地转换原始SynthTabNet数据集至OTSL格式,并保持其结构和内容的完整性;如何处理不同风格和结构的表格,以确保数据集的多样性和泛化能力;以及如何在保证数据质量的同时,处理大规模数据集的存储和计算挑战。在研究领域问题方面,挑战包括如何通过优化的表格结构识别技术,准确识别表格中的内容,尤其是处理合并单元格和空白单元格的识别问题。
常用场景
经典使用场景
在表格结构识别领域,SynthTabNet_OTSL数据集的典型应用场景在于,通过对大量表格图像的深度学习模型训练,实现对表格结构的高效解析与内容提取。该数据集提供了不同风格、大小和结构的表格,使得模型能够适应多种表格识别任务,如表格分类、结构识别以及内容理解等。
实际应用
在实际应用中,SynthTabNet_OTSL数据集被广泛应用于金融、市场营销、出版等行业,帮助实现自动化表格解析,从而提升数据处理效率,降低人工成本。此外,该数据集在电子文档处理、信息检索等领域的应用也日益广泛。
衍生相关工作
基于SynthTabNet_OTSL数据集,学术界和工业界衍生出了一系列相关研究工作,包括但不限于改进表格识别算法、提出新的表格结构表示方法、以及开发更加智能的表格处理系统。这些工作进一步推动了表格理解技术的发展,并为相关领域的应用提供了强有力的支持。
以上内容由遇见数据集搜集并总结生成


