gigatrue-slovak
收藏Hugging Face2024-12-12 更新2024-12-13 收录
下载链接:
https://huggingface.co/datasets/Plasmoxy/gigatrue-slovak
下载链接
链接失效反馈官方服务:
资源简介:
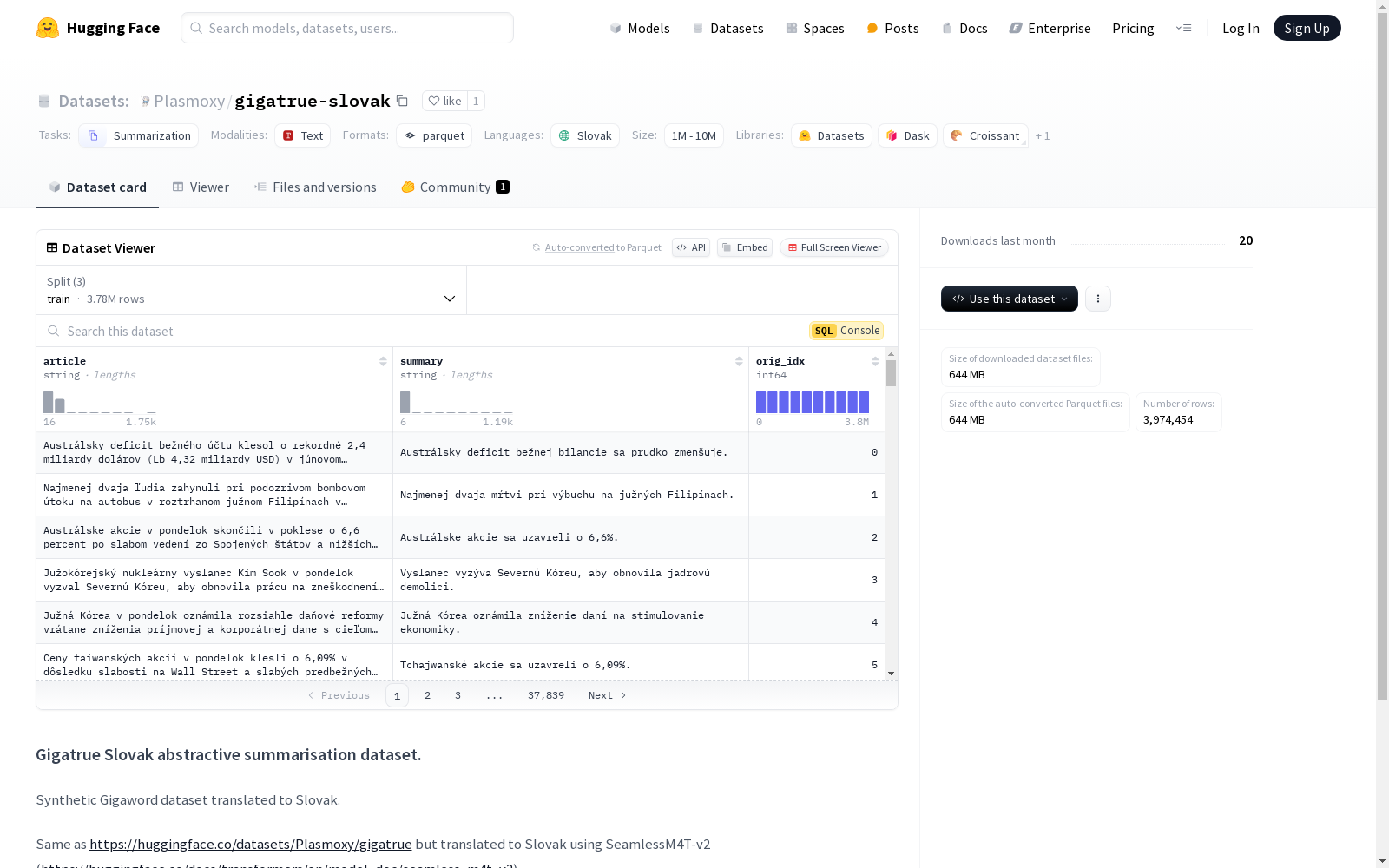
这是一个合成的大规模斯洛伐克语摘要数据集,它是从英文的Gigaword数据集翻译过来的。数据集包含文章和对应的摘要,以及原始索引。数据集分为训练、验证和测试集,适用于摘要任务。
创建时间:
2024-12-12
原始信息汇总
Gigatrue Slovak 数据集概述
数据集信息
-
特征:
article: 文章内容,数据类型为string。summary: 摘要内容,数据类型为string。orig_idx: 原始索引,数据类型为int64。
-
数据分割:
train: 训练集,包含 3,783,821 个样本,大小为 1,021,846,660 字节。validation: 验证集,包含 188,811 个样本,大小为 50,939,540 字节。test: 测试集,包含 1,822 个样本,大小为 480,530 字节。
-
下载大小: 644,294,477 字节。
-
数据集大小: 1,073,266,730 字节。
配置
- 配置名称:
default - 数据文件:
train:data/train-*validation:data/validation-*test:data/test-*
任务类别
- 摘要生成 (summarization)
语言
- 斯洛伐克语 (sk)
数据集名称
- Pretty Name: Gigatrue Slovak
数据集规模
- 1M < n < 10M
数据集来源
- 该数据集是基于 Harvard/gigaword 数据集的合成数据集,并翻译为斯洛伐克语。
- 翻译使用了 SeamlessM4T-v2 模型。
搜集汇总
数据集介绍
构建方式
Gigatrue-Slovak数据集的构建基于对原始英文数据集的翻译与改编。该数据集源自Harvard/gigaword数据集,通过SeamlessM4T-v2模型将英文文本翻译为斯洛伐克语,从而生成了斯洛伐克语版本的摘要数据集。这一过程确保了数据集在语言上的多样性和适用性,同时保留了原始数据集的结构和内容特征。
特点
Gigatrue-Slovak数据集的主要特点在于其大规模的斯洛伐克语文本数据,涵盖了从训练集到验证集和测试集的完整数据划分。数据集包含文章和对应的摘要,适用于抽象摘要任务,且数据量级在1百万到1千万条样本之间,适合进行大规模的模型训练和评估。
使用方法
该数据集可用于斯洛伐克语的抽象摘要任务,用户可以通过加载数据集的训练、验证和测试部分进行模型训练和性能评估。数据集的结构清晰,包含文章、摘要和原始索引,便于直接应用于自然语言处理模型,如Transformer模型,以提升斯洛伐克语摘要生成的能力。
背景与挑战
背景概述
Gigatrue-Slovak数据集是由研究人员将原始的Gigaword数据集翻译成斯洛伐克语而创建的,旨在为斯洛伐克语的抽象摘要任务提供丰富的资源。该数据集的核心研究问题是如何在非英语语境下,尤其是斯洛伐克语环境中,实现高效的文本摘要生成。通过使用SeamlessM4T-v2模型进行翻译,研究人员确保了数据集的高质量和语言准确性。该数据集的创建不仅丰富了斯洛伐克语的自然语言处理资源,还为多语言摘要生成技术的发展提供了重要的实验平台。
当前挑战
Gigatrue-Slovak数据集在构建过程中面临的主要挑战包括:首先,如何确保翻译后的文本在语义和语法上与原文保持一致,这需要依赖高质量的翻译模型。其次,斯洛伐克语作为一种相对小众的语言,其语言特性和语法结构可能与英语有较大差异,这增加了摘要生成的复杂性。此外,数据集的规模较大,如何高效地处理和存储这些数据也是一个技术难题。最后,由于斯洛伐克语的资源相对较少,如何评估摘要生成的质量也是一个亟待解决的问题。
常用场景
经典使用场景
Gigatrue-Slovak数据集在自然语言处理领域中,主要用于抽象摘要任务。该数据集通过提供大量的斯洛伐克语文章及其对应的摘要,为研究人员和开发者提供了一个丰富的资源库,用于训练和评估抽象摘要模型。其经典使用场景包括构建和优化基于深度学习的摘要生成模型,尤其是在多语言环境下,帮助模型更好地理解和生成斯洛伐克语的摘要内容。
实际应用
在实际应用中,Gigatrue-Slovak数据集可广泛应用于新闻自动化处理、内容推荐系统以及信息检索等领域。例如,新闻机构可以利用该数据集训练的模型自动生成新闻摘要,提升内容分发的效率;而内容推荐系统则可以通过生成精准的摘要,帮助用户快速获取所需信息,提升用户体验。
衍生相关工作
Gigatrue-Slovak数据集的发布催生了一系列相关研究工作。例如,基于该数据集的抽象摘要模型在多语言环境下的性能评估,以及如何利用迁移学习技术提升低资源语言的摘要生成效果等。此外,该数据集还为斯洛伐克语的自然语言处理研究提供了新的基准,促进了该领域技术的快速发展和创新。
以上内容由遇见数据集搜集并总结生成


