turkic_tts_dataset
收藏Hugging Face2026-05-11 更新2026-05-15 收录
下载链接:
https://huggingface.co/datasets/futureDoctor/turkic_tts_dataset
下载链接
链接失效反馈官方服务:
资源简介:
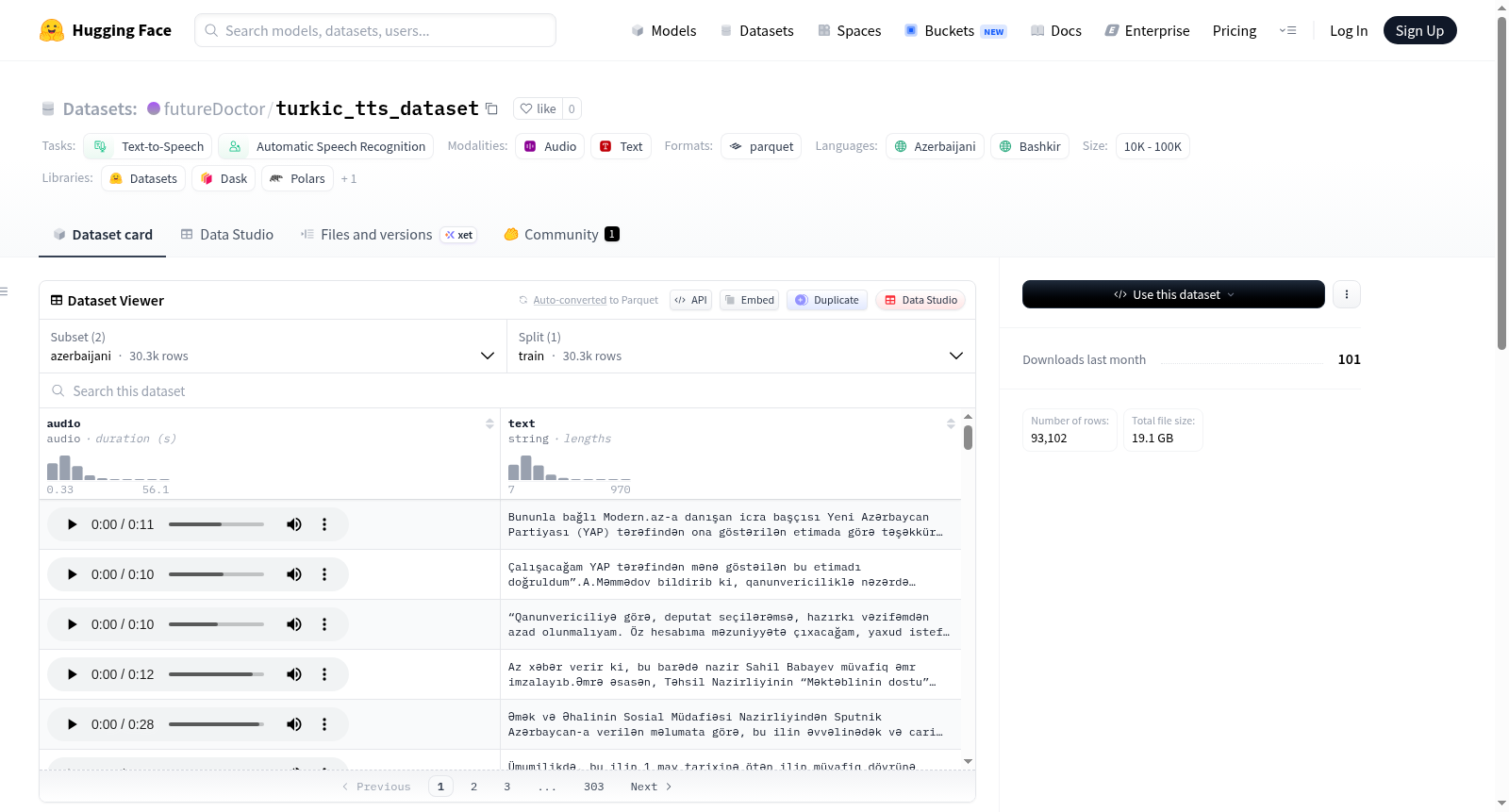
该数据集是一个用于文本转语音(TTS)任务的阿塞拜疆语(az)数据集,遵循MIT许可证。数据以配置形式组织,当前包含一个名为az的配置,其训练集数据位于data/azerbaijani/目录下,格式为Parquet文件。
This dataset is an Azerbaijani (az) dataset for text-to-speech (TTS) tasks, licensed under MIT. The data is organized in configurations, currently including one configuration named az, with training split data located in the data/azerbaijani/ directory in Parquet format.
创建时间:
2026-05-09
搜集汇总
数据集介绍
构建方式
该数据集为支持突厥语系多语言文本转语音任务而构建,整合了阿塞拜疆语与巴什基尔语两大子集的语音资源。阿塞拜疆语子集源自BHOSAI/Azerbaijani_News_TTS数据集,包含一位女性发音人的新闻语音样本;巴什基尔语子集则来自AigizK/bashkort_tts_dataset,汇聚8位发音人(7位女性与1位男性,其中部分为ElevenLabs克隆语音)的语料。数据以Parquet格式统一存储,并按照语言子集划分,通过HuggingFace Datasets库实现高效加载。
特点
该数据集具备跨语言与多发音人特性,覆盖阿塞拜疆语与巴什基尔语两种突厥语系语言,合计提供9位发音人的语音样本。每个样本包含音频、文本转录、原始数据来源链接、发音人标识及性别字段,结构清晰。尤其值得关注的是,巴什基尔语子集引入了ElevenLabs合成语音,为低资源语言的语音合成研究提供了独特的增强数据。数据集以独立子集形式呈现,便于按需选用。
使用方法
用户可通过HuggingFace Datasets库便捷加载数据。以Python为例,使用`load_dataset("futureDoctor/turkic_tts_dataset", "azerbaijani", split="train")`加载阿塞拜疆语子集,类似地修改配置名为"bashkir"即可获取巴什基尔语子集。加载后的数据集包含`audio`、`text`等字段,可直接用于训练文本转语音或自动语音识别模型。由于数据以Parquet格式存储,亦支持通过其他数据处理工具进行访问与分析。
背景与挑战
背景概述
突厥语系作为横跨欧亚大陆的重要语族,其下属语言的语音合成研究长期受限于高质量标注数据的匮乏。Turkic TTS Dataset于近期由研究者构建并发布,旨在填补该语系在多语言文本转语音(TTS)与自动语音识别(ASR)领域的资源空白。该数据集整合了阿塞拜疆语和巴什基尔语两大子集的语音数据,前者源自BHOSAI/Azerbaijani_News_TTS项目,包含一位女性发音人的新闻语音;后者则采集自AigizK/bashkort_tts_dataset,涵盖八位发音人(七女一男)的克隆语音。通过统一的数据模式(含音频、文本、说话人标识等字段),该数据集为突厥语系的跨语言语音建模提供了标准化基准,对推动低资源语言语音技术研究具有开拓性意义。
当前挑战
该数据集面临的核心挑战来自领域问题与构建过程双重维度。在领域层面,突厥语系语言普遍存在形态复杂、音系多样且语料稀缺的特点,现有TTS与ASR模型往往偏向印欧语系数据,导致对阿塞拜疆语和巴什基尔语的合成与识别效果欠佳,因此需要针对性数据来驱动模型鲁棒性提升。在构建过程中,数据集的来源异质性构成了显著障碍:阿塞拜疆语数据仅依赖单一女声且语域局限于新闻,可能引入风格偏差;而巴什基尔语子集尽管发音人数量较多,却采用ElevenLabs语音克隆技术生成,其合成音质与自然语音的差距可能影响下游任务的泛化能力。此外,不同子集间说话人标注粒度不一、录音环境未作统一规范,给跨语言模型训练中的声学特征对齐带来额外挑战。
常用场景
经典使用场景
在跨语言语音合成与自动语音识别领域,Turkic TTS Dataset凭借其精心收录的阿塞拜疆语和巴什基尔语高质量语音-文本配对数据,成为研究突厥语系低资源语音技术的基石。研究者常利用该数据集构建多说话人、多风格的文本转语音系统,尤其针对女性与男性声学特征差异进行建模。数据集提供的标准化音频格式与清晰标注的说话人ID、性别属性,使得语音克隆、语种自适应合成等前沿任务的训练与评估变得可行,为探索突厥语系语言的韵律节奏与发音规律提供了可靠的数据支撑。
实际应用
在实际部署中,Turkic TTS Dataset直接驱动了面向突厥语系用户的语音助手、有声书生成及无障碍阅读工具的研发。例如,基于该数据集训练的文本转语音模型可被集成到新闻播报系统中,生成带有地域特色的阿塞拜疆语语音;巴什基尔语子集则支持文化遗产数字化项目,将书面文献转化为语音。此外,数据集中的性别与说话人标签使得个性化语音定制成为可能,如为教育平台创建虚拟教师的专属声库,或为通信类应用提供多角色语音交互体验。这些应用有效提升了突厥语系语言在数字世界中的活跃度与传播效率。
衍生相关工作
围绕Turkic TTS Dataset已涌现出多项代表性研究成果。研究者基于该数据集提出了面向突厥语系的跨语言语音合成迁移学习框架,通过共享声学模型实现了阿塞拜疆语与巴什基尔语之间的零资源语音生成。另有工作利用其多说话人特性,开发了结合风格迁移的语音克隆技术,使得克隆语音在保留原始说话人特征的同时能够适配不同情感或语境。该数据集还常作为基准出现在少样本多语言TTS的对比实验中,与Common Voice、VoxPopuli等通用语音数据集一道,催生了针对低资源语言的音素级数据增强方法,推动了语音技术向小众语言的普惠化发展。
以上内容由遇见数据集搜集并总结生成


