opc-sft-stage1
收藏魔搭社区2026-04-30 更新2024-11-30 收录
下载链接:
https://modelscope.cn/datasets/AI-ModelScope/opc-sft-stage1
下载链接
链接失效反馈官方服务:
资源简介:

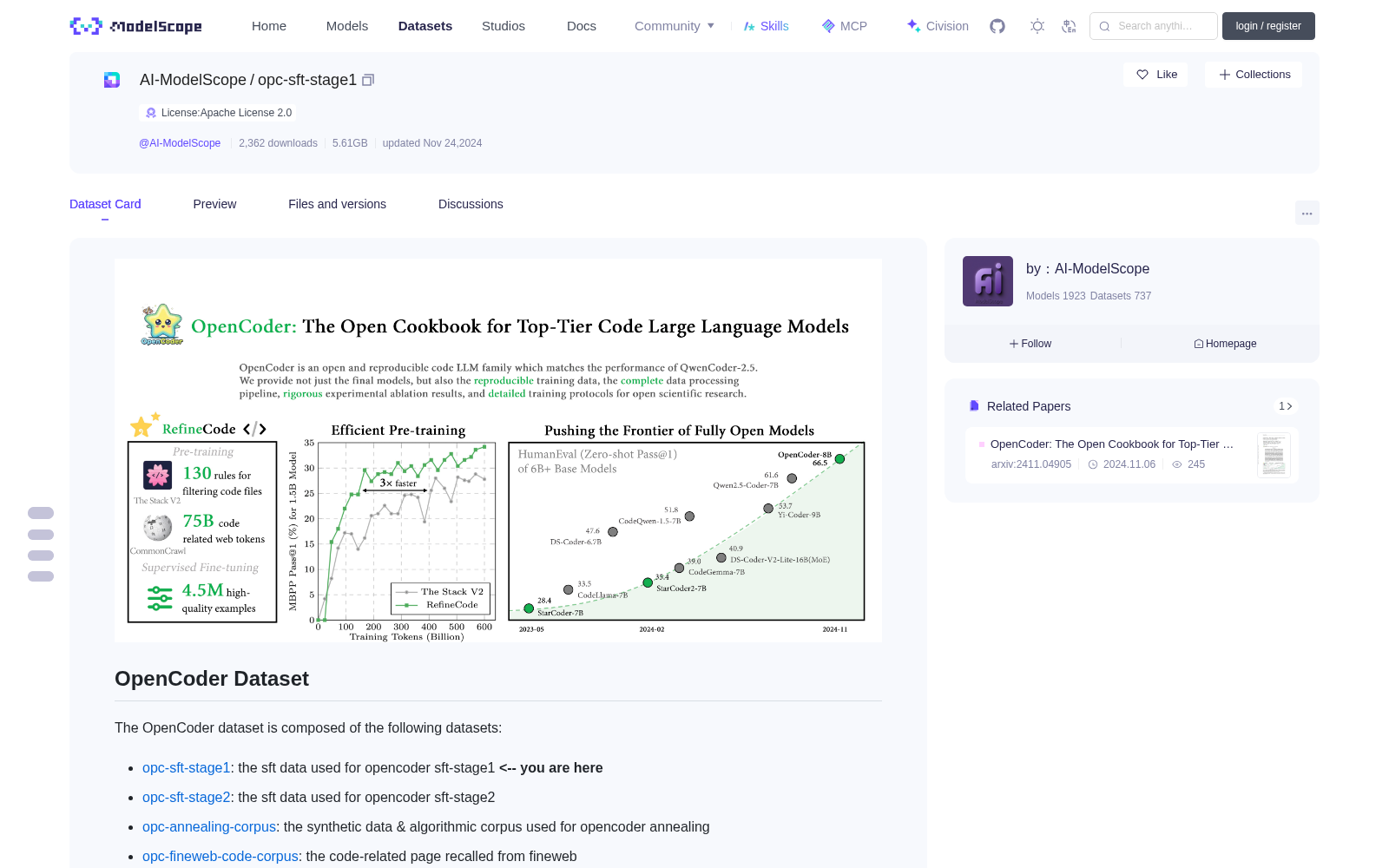
# OpenCoder Dataset
The OpenCoder dataset is composed of the following datasets:
* [opc-sft-stage1](https://huggingface.co/datasets/OpenCoder-LLM/opc-sft-stage1): the sft data used for opencoder sft-stage1 **<-- you are here**
* [opc-sft-stage2](https://huggingface.co/datasets/OpenCoder-LLM/opc-sft-stage2): the sft data used for opencoder sft-stage2
* [opc-annealing-corpus](https://huggingface.co/datasets/OpenCoder-LLM/opc-annealing-corpus): the synthetic data & algorithmic corpus used for opencoder annealing
* [opc-fineweb-code-corpus](https://huggingface.co/datasets/OpenCoder-LLM/fineweb-code-corpus): the code-related page recalled from fineweb
* [opc-fineweb-math-corpus](https://huggingface.co/datasets/OpenCoder-LLM/fineweb-math-corpus): the math-related page recalled from fineweb
* [refineCode-code-corpus-meta](https://huggingface.co/datasets/OpenCoder-LLM/RefineCode-code-corpus-meta): the meta-data of RefineCode
Detailed information about the data can be found in our [paper](https://arxiv.org/abs/2411.04905).
## sft-stage1 summary
This dataset is used in OpenCoder's Stage 1 and consists of three parts:
* **Filtered_infinity_instruct**: Filtered from [infinity_instruct](https://huggingface.co/datasets/BAAI/Infinity-Instruct) using LLM to extract code-related content. Since the original outputs were often low-quality (e.g., overly concise responses, inconsistent code formatting), we recommend regenerating them with a stronger LLM based on the given instructions.
* **Realuser_instruct**: Extracted bilingual code-related instructions from GPT conversation histories like [ShareGPT](https://github.com/domeccleston/sharegpt) and [WildChat](https://huggingface.co/datasets/allenai/WildChat). Low-quality responses were regenerated.This portion of data, sampled from real users, is of high quality and greatly enhances the practical performance of code LLMs
* **Largescale_diverse_instruct**: Generated using a pipeline based on seeds like CommonCrawl and Source Code. This dataset provides diverse code-related instructions.
## How to use it
```python
from datasets import load_dataset
realuser_instruct = load_dataset("OpenCoder-LLM/opc-sft-stage1", "realuser_instruct")
filtered_infinity_instruct = load_dataset("OpenCoder-LLM/opc-sft-stage1", "filtered_infinity_instryuct")
largescale_diverse_instruct = load_dataset("OpenCoder-LLM/opc-sft-stage1", "largescale_diverse_instruct")
```
## Citation Information
Please consider citing our [paper](https://arxiv.org/abs/2411.04905) if you find this dataset useful:
```
@inproceedings{Huang2024OpenCoderTO,
title = {OpenCoder: The Open Cookbook for Top-Tier Code Large Language Models},
author = {Siming Huang and Tianhao Cheng and Jason Klein Liu and Jiaran Hao and Liuyihan Song and Yang Xu and J. Yang and J. H. Liu and Chenchen Zhang and Linzheng Chai and Ruifeng Yuan and Zhaoxiang Zhang and Jie Fu and Qian Liu and Ge Zhang and Zili Wang and Yuan Qi and Yinghui Xu and Wei Chu},
year = {2024},
url = {https://arxiv.org/pdf/2411.04905}
}
```
# OpenCoder 数据集
OpenCoder 数据集由以下多个数据集组成:
* [opc-sft-stage1](https://huggingface.co/datasets/OpenCoder-LLM/opc-sft-stage1):用于OpenCoder监督微调(Supervised Fine-Tuning, SFT)阶段1的SFT数据 **<-- 您当前位于此处**
* [opc-sft-stage2](https://huggingface.co/datasets/OpenCoder-LLM/opc-sft-stage2):用于OpenCoder监督微调阶段2的SFT数据
* [opc-annealing-corpus](https://huggingface.co/datasets/OpenCoder-LLM/opc-annealing-corpus):用于OpenCoder退火训练的合成数据与算法语料库
* [opc-fineweb-code-corpus](https://huggingface.co/datasets/OpenCoder-LLM/opc-fineweb-code-corpus):从FineWeb中召回的代码相关网页数据
* [opc-fineweb-math-corpus](https://huggingface.co/datasets/OpenCoder-LLM/opc-fineweb-math-corpus):从FineWeb中召回的数学相关网页数据
* [refineCode-code-corpus-meta](https://huggingface.co/datasets/OpenCoder-LLM/RefineCode-code-corpus-meta):RefineCode的元数据
有关该数据集的详细信息可参阅我们的[论文](https://arxiv.org/abs/2411.04905)。
## 监督微调阶段1 数据集概述
本数据集应用于OpenCoder的第一阶段训练,包含三个子部分:
* **Filtered_infinity_instruct**:通过大语言模型(Large Language Model, LLM)从[infinity_instruct](https://huggingface.co/datasets/BAAI/Infinity-Instruct)中筛选提取的代码相关内容。由于原始输出质量参差不齐(例如回答过于简洁、代码格式不一致),我们建议基于给定指令使用性能更强的大语言模型重新生成回答。
* **Realuser_instruct**:从[ShareGPT](https://github.com/domeccleston/sharegpt)与[WildChat](https://huggingface.co/datasets/allenai/WildChat)等GPT对话历史中提取的双语代码相关指令。我们已对低质量回复进行了重新生成。该部分数据源自真实用户,质量较高,可有效提升代码大语言模型的实际应用性能。
* **Largescale_diverse_instruct**:基于CommonCrawl与源代码等种子数据通过流水线生成的数据集,可提供多样化的代码相关指令。
## 使用方法
python
from datasets import load_dataset
realuser_instruct = load_dataset("OpenCoder-LLM/opc-sft-stage1", "realuser_instruct")
filtered_infinity_instruct = load_dataset("OpenCoder-LLM/opc-sft-stage1", "filtered_infinity_instryuct")
largescale_diverse_instruct = load_dataset("OpenCoder-LLM/opc-sft-stage1", "largescale_diverse_instruct")
## 引用信息
若您认为本数据集对您的研究有所帮助,请引用我们的[论文](https://arxiv.org/abs/2411.04905):
@inproceedings{Huang2024OpenCoderTO,
title = {OpenCoder: The Open Cookbook for Top-Tier Code Large Language Models},
author = {Siming Huang and Tianhao Cheng and Jason Klein Liu and Jiaran Hao and Liuyihan Song and Yang Xu and J. Yang and J. H. Liu and Chenchen Zhang and Linzheng Chai and Ruifeng Yuan and Zhaoxiang Zhang and Jie Fu and Qian Liu and Ge Zhang and Zili Wang and Yuan Qi and Yinghui Xu and Wei Chu},
year = {2024},
url = {https://arxiv.org/pdf/2411.04905}
}
提供机构:
maas创建时间:
2024-11-13
搜集汇总
数据集介绍
背景与挑战
背景概述
opc-sft-stage1是OpenCoder数据集的一部分,专用于Stage 1的监督微调,包含过滤的代码相关指令、高质量的真实用户指令以及大规模多样化指令。该数据集大小为5.61GB,采用Apache License 2.0许可证,旨在提升代码大语言模型的实用性能。
以上内容由遇见数据集搜集并总结生成


