open-web-math/open-web-math
收藏Hugging Face2023-10-17 更新2024-03-04 收录
下载链接:
https://hf-mirror.com/datasets/open-web-math/open-web-math
下载链接
链接失效反馈官方服务:
资源简介:
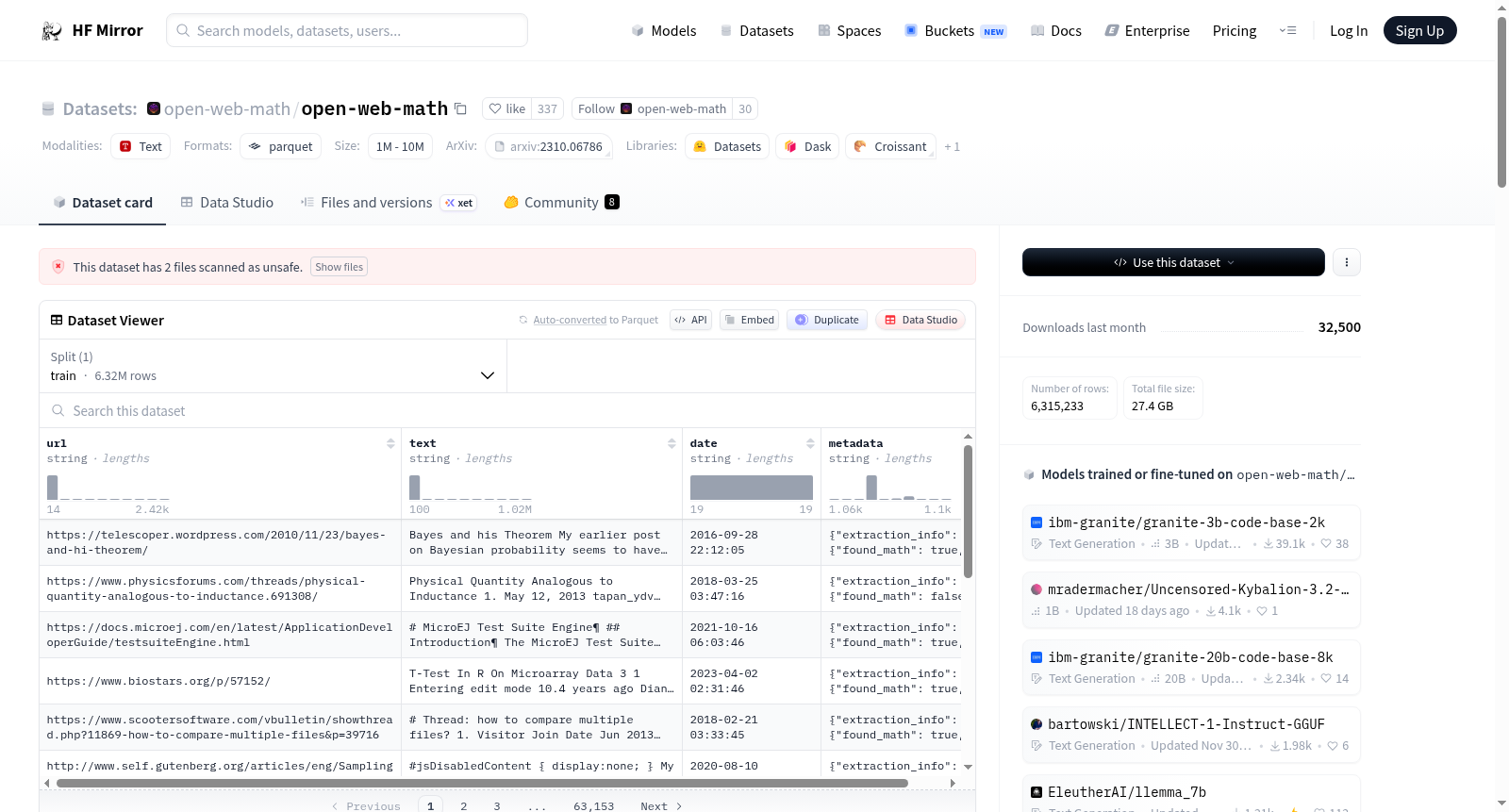
OpenWebMath是一个包含互联网上大部分高质量数学文本的数据集。该数据集从Common Crawl的2000亿个HTML文件中过滤和提取,最终包含630万份文档,总计147亿个标记。数据集的结构包括文本、URL、日期和元数据。数据集适用于大型语言模型的预训练和微调。数据集的处理流程包括预过滤HTML文档、文本提取、内容分类和过滤、去重以及人工检查。
OpenWebMath is a dataset containing most of the high-quality mathematical text available on the Internet. It is constructed by filtering and extracting from 200 billion HTML files within Common Crawl, ultimately comprising 6.3 million documents with a total of 14.7 billion tokens. The dataset includes text, URLs, dates, and metadata as its core structural components. It is suitable for pre-training and fine-tuning of large language models (LLMs). The processing pipeline for building this dataset involves pre-filtering HTML documents, text extraction, content classification and filtering, deduplication, and manual inspection.
提供机构:
open-web-math
原始信息汇总
数据集概述
基本信息
- 名称: OpenWebMath
- 语言: 英语(en)
- 任务类别: 文本生成(text-generation)
- 规模类别: 10B<n<100B
- 许可证: ODC-By
数据集结构
- 特征:
url: 字符串类型text: 字符串类型date: 字符串类型metadata: 字符串类型
- 分割:
train: 6315233个样本,总大小56651995057字节
下载与使用
- 下载大小: 16370689925字节
- 数据集总大小: 56651995057字节
- 使用示例: python from datasets import load_dataset ds = load_dataset("open-web-math/open-web-math")
内容描述
- 来源: 从Common Crawl的200亿HTML文件中筛选出,包含630万文档,总计147亿个令牌。
- 应用: 用于预训练和微调大型语言模型。
- 文档来源: 超过13万个不同域名,包括论坛、教育页面和博客。
- 常见域名:
- stackexchange.com: 9.55%
- nature.com: 3.14%
- wordpress.com: 2.66%
- physicsforums.com: 2.38%
- github.io: 1.49%
- zbmath.org: 1.27%
- wikipedia.org: 1.27%
- groundai.com: 1.12%
- blogspot.com: 1.07%
- mathoverflow.net: 1.02%
处理流程
- 预过滤HTML文档
- 文本提取
- 内容分类与过滤
- 去重
- 人工检查
许可证与引用
-
许可证: ODC-By 1.0,同时遵守Common Crawl的使用条款。
-
引用信息:
@misc{paster2023openwebmath, title={OpenWebMath: An Open Dataset of High-Quality Mathematical Web Text}, author={Keiran Paster and Marco Dos Santos and Zhangir Azerbayev and Jimmy Ba}, year={2023}, eprint={2310.06786}, archivePrefix={arXiv}, primaryClass={cs.AI} }
搜集汇总
数据集介绍
构建方式
OpenWebMath 数据集源自于海量的 Common Crawl 网络存档,该存档包含超过 2000 亿份 HTML 文档。为了从这片广袤的互联网数学文本中提炼精华,研究者设计了一套精密的多阶段流水线。首先,通过预过滤器快速筛选出可能包含数学内容的文档,以节省计算资源。随后,利用先进的文本提取技术,从 HTML 中精准剥离出正文与 LaTeX 格式的数学公式,并有效去除网页模板等冗余信息。接着,采用 FastText 语言识别模型确保语料的英文纯净性,结合基于 Proof-Pile 训练的 KenLM 模型过滤高困惑度文本,并运用自研的 MathScore 模型甄别并保留数学相关文档。最后,通过 SimHash 算法进行去重处理,并辅以人工审查,剔除低质量页面,最终构建出包含 630 万篇文档、总计 147 亿词元的精选数学语料库。
特点
OpenWebMath 数据集的核心特质在于其卓越的质量与广泛的学科覆盖。其内容跨越数学、物理学、统计学与计算机科学等多个领域,来源涵盖 StackExchange、Nature、Wikipedia 等超过 13 万个权威域名,确保了知识来源的多样性与可靠性。数据集中每篇文档均保留完整的文本、来源 URL、抓取日期以及提取过程中的元数据,为后续分析提供了丰富的信息维度。尤为突出的是,该数据集对 LaTeX 数学公式的提取进行了深度优化,极大提升了数学符号与表达式的保真度,使其成为预训练与微调大型语言模型的理想之选。相较于其他网络数据集,其显著减少了网页样板代码的干扰,从而呈现出更为纯粹、连贯的数学文本流。
使用方法
OpenWebMath 数据集的使用极为便捷,完全兼容 Hugging Face 生态。用户只需通过一行简单的 Python 代码 `load_dataset("open-web-math/open-web-math")` 即可加载整个数据集。加载后的数据以字典形式呈现,包含 'text'(文档文本)、'url'(来源链接)、'date'(抓取日期)及 'metadata'(提取过程信息)四个字段。该数据集主要面向大语言模型的预训练与微调任务,尤其适用于需要增强数学推理能力的场景。研究者可直接将其作为训练语料,或依据 'url' 与 'date' 字段进行领域特定的子集筛选。数据集采用 ODC-By 1.0 开放许可,在遵守 CommonCrawl 使用条款的前提下,用户可以自由地将其用于学术研究与商业应用。
背景与挑战
背景概述
在人工智能领域,数学推理能力的提升对大型语言模型的发展至关重要,然而高质量的数学文本数据却长期稀缺。OpenWebMath数据集由Keiran Paster、Marco Dos Santos、Zhangir Azerbayev和Jimmy Ba于2023年创建,旨在填补这一空白。该数据集从超过2000亿个Common Crawl HTML文件中精心筛选并提取出630万个文档,总计147亿个token,涵盖了数学、物理学、统计学、计算机科学等多个学科。其核心研究问题在于如何从海量互联网文本中高效提取并保留高质量的数学内容,以支持大语言模型的预训练与微调。OpenWebMath的问世为数学领域的人工智能研究提供了重要资源,推动了模型在符号推理、问题求解等方面的能力边界,对相关领域产生了深远影响。
当前挑战
OpenWebMath所解决的领域挑战在于大语言模型在数学推理任务中常因缺乏高质量训练数据而表现不佳,传统网络文本数据集包含大量噪声、低质量内容及不完整的数学表达式。构建过程中,团队面临多重技术难题:首先,需从Common Crawl的庞大语料中预筛选出包含数学内容的文档,避免处理时间浪费;其次,提取LaTeX格式的数学表达式并去除HTML模板噪声,确保文本纯净;再次,利用语言识别模型过滤非英语文档,并借助KenLM模型剔除高困惑度低质量文本,同时开发MathScore模型精准识别数学文档;最后,通过SimHash算法进行去重,并辅以人工检查,确保数据集的最终质量。这些步骤共同构成了一个严谨的流水线,旨在产出高纯度、高覆盖率的数学文本资源。
常用场景
经典使用场景
OpenWebMath 数据集作为大规模、高质量数学文本的集合,其经典使用场景在于为大型语言模型的预训练与微调阶段提供专属的数学领域语料。该数据集从超过 2000 亿份 Common Crawl HTML 文件中,通过严密的过滤与提取流程,最终汇聚成 630 万篇文档、共计 147 亿词元的数学内容,覆盖数学、物理学、统计学、计算机科学等多学科知识。研究者常借助该数据集增强模型对数学符号、公式推导及逻辑推理的理解能力,使其在生成数学内容时展现出更高的准确性与连贯性,进而成为数学领域语言模型训练的基石资源。
解决学术问题
在学术研究层面,OpenWebMath 数据集有效解决了数学领域高质量文本数据匮乏的瓶颈问题。传统通用语料库中,数学内容往往因格式复杂、噪声过多而被稀释,导致模型在数学推理、问题求解等任务中表现欠佳。该数据集通过引入 MathScore 模型筛选、LaTeX 内容精准提取及 KenLM 困惑度过滤等技术,显著提升了数学文本的纯度与可用性。其发布为数学语言模型的可复现研究提供了标准化基准,推动了数学推理能力评估体系的完善,并促使学界重新审视预训练数据质量对模型性能的深远影响。
衍生相关工作
OpenWebMath 数据集衍生了一系列具有影响力的研究工作。在其基础上,研究者开发了专注于数学推理的专用语言模型,如通过该数据集预训练后微调于数学问题解答的模型,在 GSM8K 和 MATH 等基准上取得突破性进展。同时,该数据集启发了对数学文本去重与质量评估方法的深入探索,例如基于 SimHash 的文档去重策略和 MathScore 分类器的改进版本。此外,OpenWebMath 还催生了跨领域知识迁移的研究,将数学推理能力泛化至物理、工程等学科,进一步拓展了预训练数据构建的范式边界。
以上内容由遇见数据集搜集并总结生成


