bigbio/mlee
收藏Hugging Face2022-12-22 更新2024-03-04 收录
下载链接:
https://hf-mirror.com/datasets/bigbio/mlee
下载链接
链接失效反馈资源简介:
MLEE是一个关于血管生成论文摘要的事件抽取语料库,包含手动标注的实体、关系、事件和共指信息。这些标注涵盖了分子、细胞、组织和器官层面的过程。
MLEE is an event extraction corpus for abstracts of angiogenesis-related research papers, which contains manually annotated entities, relations, events and coreference information. These annotations cover processes at the molecular, cellular, tissue and organ levels.
提供机构:
bigbio
原始信息汇总
数据集概述
基本信息
- 语言: 英语
- 许可证: CC BY NC SA 3.0
- 多语言性: 单语种
- 数据集名称: MLEE
- 主页: http://www.nactem.ac.uk/MLEE/
- 是否公开: 是
- 是否可在PubMed上访问: 是
任务类型
- 事件抽取 (EVENT_EXTRACTION)
- 命名实体识别 (NAMED_ENTITY_RECOGNITION)
- 关系抽取 (RELATION_EXTRACTION)
- 共指消解 (COREFERENCE_RESOLUTION)
数据集描述
MLEE是一个事件抽取语料库,包含对关于血管生成论文摘要的手动标注。该数据集涵盖了实体、关系、事件和共指的标注,涉及分子、细胞、组织和器官级别的生物过程。
引用信息
@article{pyysalo2012event, title={Event extraction across multiple levels of biological organization}, author={Pyysalo, Sampo and Ohta, Tomoko and Miwa, Makoto and Cho, Han-Cheol and Tsujii, Junichi and Ananiadou, Sophia}, journal={Bioinformatics}, volume={28}, number={18}, pages={i575--i581}, year={2012}, publisher={Oxford University Press} }
AI搜集汇总
数据集介绍
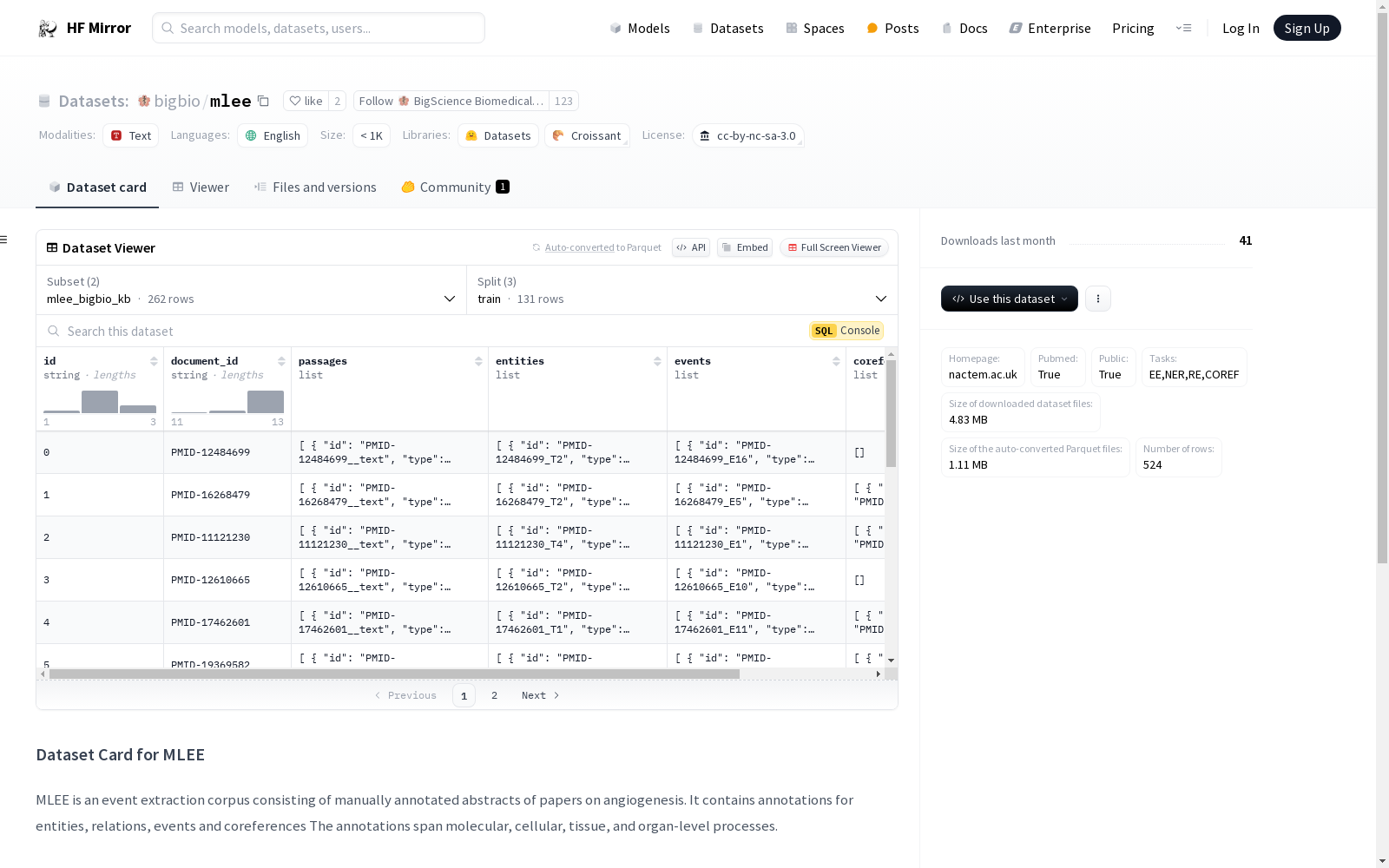
构建方式
MLEE数据集的构建基于对血管生成领域论文摘要的手动标注,涵盖了分子、细胞、组织和器官层面的过程。该数据集通过详细的标注,包括实体、关系、事件和共指关系,形成了丰富的事件抽取语料库。
特点
MLEE数据集的显著特点在于其多层次的生物组织标注,不仅包括事件抽取,还涉及命名实体识别、关系抽取和共指解析。这些特点使得该数据集在生物医学文本分析中具有广泛的应用潜力。
使用方法
MLEE数据集可用于训练和评估事件抽取、命名实体识别、关系抽取和共指解析等自然语言处理任务的模型。研究者可以通过访问其官方主页获取数据,并根据具体研究需求进行数据处理和模型训练。
背景与挑战
背景概述
MLEE数据集是由英国曼彻斯特大学的Nactem研究小组于2012年创建的,专注于生物医学领域的事件抽取任务。该数据集包含了关于血管生成(angiogenesis)的论文摘要,经过人工标注,涵盖了分子、细胞、组织和器官等多个层次的生物过程。主要研究人员包括Sampo Pyysalo、Tomoko Ohta等,他们的研究旨在解决生物医学文本中复杂事件和实体关系的自动识别问题。MLEE数据集的发布对生物医学信息学领域的事件抽取、命名实体识别、关系抽取和共指消解等任务产生了深远影响,为相关研究提供了宝贵的资源。
当前挑战
MLEE数据集在构建过程中面临的主要挑战包括:首先,生物医学文本的高度专业性和复杂性使得标注工作极为困难,需要具备深厚领域知识的专家进行精细标注。其次,事件抽取任务涉及多个层次的生物过程,如何准确捕捉和表示这些层次间的复杂关系是一个技术难题。此外,数据集中涉及的共指消解任务也极具挑战性,因为生物医学文本中的实体和事件往往具有高度的模糊性和多样性。这些挑战不仅影响了数据集的构建质量,也对后续的模型训练和算法设计提出了高要求。
常用场景
经典使用场景
MLEE数据集在生物医学领域中被广泛应用于事件抽取、命名实体识别、关系抽取和共指消解等任务。其经典使用场景包括从生物医学文献的摘要中自动提取分子、细胞、组织和器官级别的生物过程事件,从而支持生物医学研究中的知识发现和信息整合。
衍生相关工作
基于MLEE数据集,研究者们开发了多种事件抽取和实体识别算法,并在生物医学文本挖掘领域发表了多篇经典论文。这些工作不仅提升了事件抽取技术的准确性和效率,还促进了相关领域的技术交流和合作,形成了丰富的学术成果和技术积累。
数据集最近研究
最新研究方向
在生物医学领域,MLEE数据集因其对血管生成相关文献的深度标注而备受关注。该数据集不仅涵盖了命名实体识别、关系抽取、事件抽取和共指消解等核心任务,还特别强调了分子、细胞、组织和器官等多个生物层次的复杂交互。近年来,随着自然语言处理技术在生物医学文本分析中的广泛应用,MLEE数据集成为研究者探索多层次生物事件关系的前沿工具。其丰富的标注信息为开发更精确的生物事件抽取模型提供了宝贵的资源,推动了生物医学文本挖掘技术的进步,尤其在精准医疗和药物研发领域具有深远的应用价值。
以上内容由AI搜集并总结生成


