声音转文本模型训练数据
收藏浙江省数据知识产权登记平台2025-09-01 更新2025-09-06 收录
下载链接:
https://www.zjip.org.cn/home/announce/trends/173186
下载链接
链接失效反馈官方服务:
资源简介:
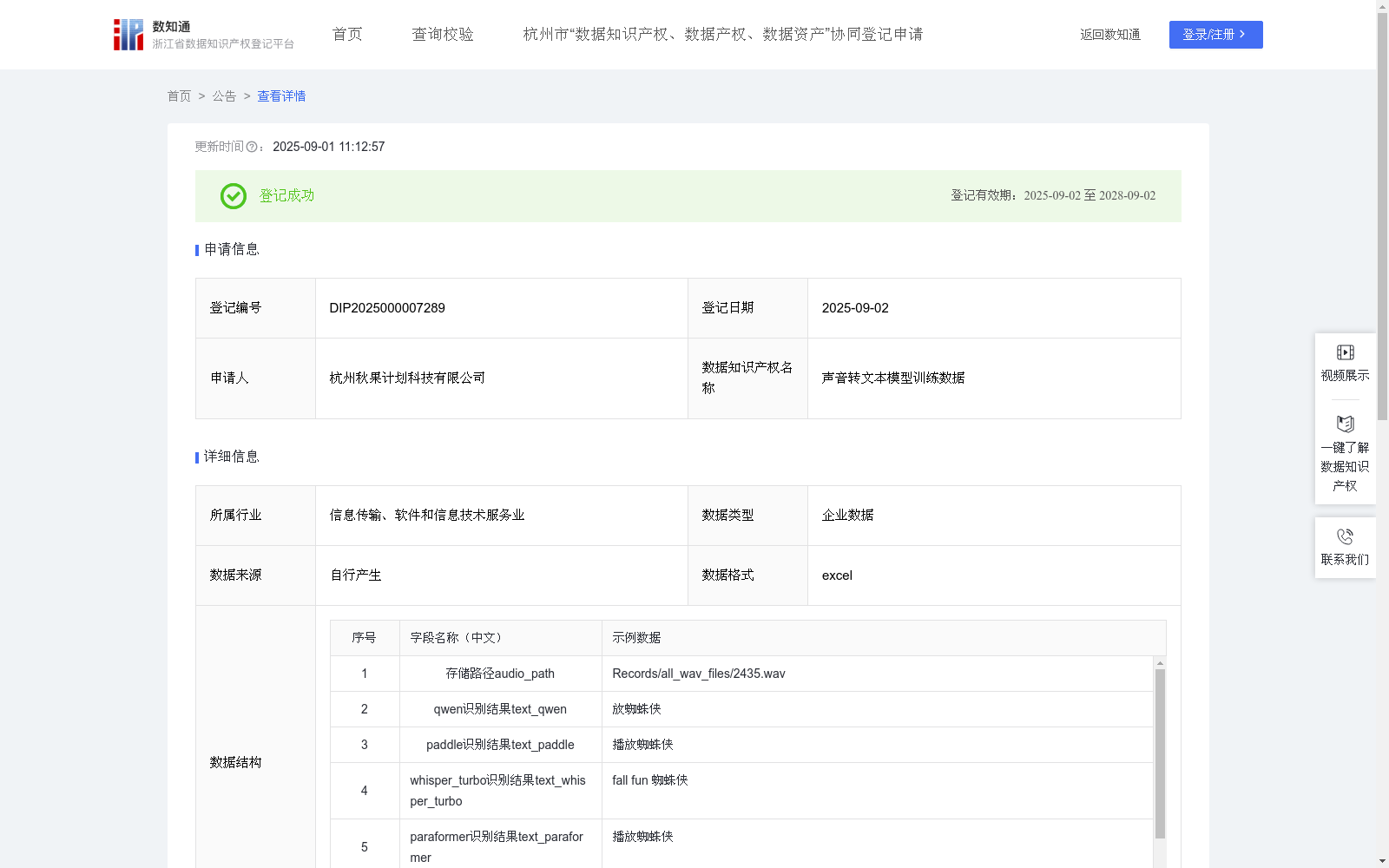
该训练数据为从声音自动获取的训练样本,用于声音转文本模型(下称ASR模型)的训练和优化。本训练数据通过多种开源ASR模型对原始音频数据进行识别处理后,进行联合投票优化,样本质量更高,有助于提高ASR模型的鲁棒性和泛化能力。训练好的ASR模型能应用到智能终端和智能家居等物联网设备中,将用户的声音转化为文本指令,方便人们的工作和生活。(1) 数据收集:
秋果计划自有产品Wigain智能眼镜的实时对话、测试中收集的音频数据格式为wav文件。
(2) 数据清洗处理:
从音频文件保存路径audio_path中获取音频数据;
使用qwen大模型的ASR模型得到一语音识别结果text_qwen;
使用paddle深度学习平台的ASR模型得到另一语音识别结果text_paddle;
使用whisper_turbo语音识别服务的ASR模型得到的再一语音识别结果text_whisper_turbo;
使用paraformer识别模型的的ASR模型得到又一语音识别结果text_paraformer;
对以上4个语音识别结果进行片段投票得到投票得到融合的投票结果text_vote,比较出不同之处diff_spans并在text_vote上进行高亮标识;
计算4个语音识别结果的一致率correct_char_ratio。
下面对diff_spans和correct_char_ratio涉及的规则进行解释说明,以样例数据为例,投票算法首先从4个结果出选出与其余3个重合度最高的一个,即“播放蜘蛛侠”,由这个结果与其他3个结果进行片段对比,片段“播放”、“蜘蛛侠”2个片段在其他结果中都能找到匹配的片段,则说明该结果的全部字符都能得到验证,因此一致率为1。再以其它数据为例,“Run bot.”、“ron bought”、“run but”、“run barth”投票得到“run bot.” (t.标红高亮),比较出不同之处diff_spans=[{"diff_span": [6, 8], "gt": null, "common_span_strs": null}],计算出一致率correct_char_ratio=0.75。过程为首先找到了“Run bot.”,再与其他3个结果对比,片段“Run bo”可由第3和第4个结果得到验证,片段“n bo”可由第二个结果得到验证,而片段“t.”无法验证,因此一致率为6/8=0.75。
(3) 模型训练
将清洗处理好的数据用于ASR模型的训练与优化。训练过程中,将一致率大于0.9的数据作为正向训练样本,将一致率小于0.96的舍去。
(4) 模型输出
将获取到的音频输入到训练好的ASR模型中,识别音频中的文本数据。
提供机构:
杭州秋果计划科技有限公司
创建时间:
2025-06-11
搜集汇总
数据集介绍
背景与挑战
背景概述
该数据集包含6192条音频转文本训练样本,每月更新,通过qwen、paddle、whisper_turbo和paraformer四种ASR模型识别后投票优化生成高质量文本,用于提升声音转文本模型的鲁棒性和泛化能力,主要应用于智能终端和物联网设备的指令识别。
以上内容由遇见数据集搜集并总结生成


