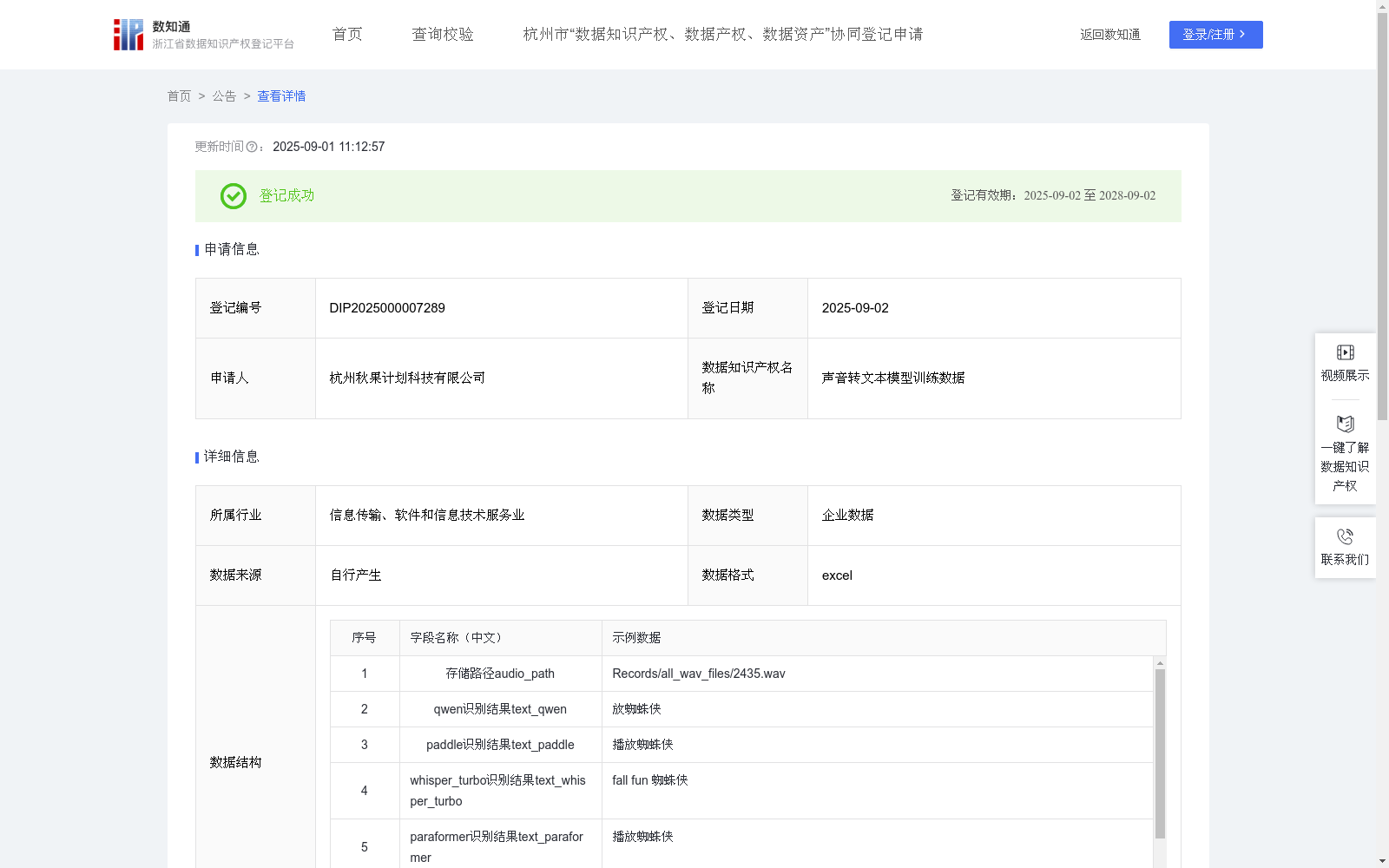
声音转文本模型训练数据
收藏浙江省数据知识产权登记平台2025-09-01 更新2025-09-06 收录
下载链接:
https://www.zjip.org.cn/home/announce/trends/173186
下载链接
链接失效反馈官方服务:
资源简介:
该训练数据为从声音自动获取的训练样本,用于声音转文本模型(下称ASR模型)的训练和优化。本训练数据通过多种开源ASR模型对原始音频数据进行识别处理后,进行联合投票优化,样本质量更高,有助于提高ASR模型的鲁棒性和泛化能力。训练好的ASR模型能应用到智能终端和智能家居等物联网设备中,将用户的声音转化为文本指令,方便人们的工作和生活。(1) 数据收集:
秋果计划自有产品Wigain智能眼镜的实时对话、测试中收集的音频数据格式为wav文件。
(2) 数据清洗处理:
从音频文件保存路径audio_path中获取音频数据;
使用qwen大模型的ASR模型得到一语音识别结果text_qwen;
使用paddle深度学习平台的ASR模型得到另一语音识别结果text_paddle;
使用whisper_turbo语音识别服务的ASR模型得到的再一语音识别结果text_whisper_turbo;
使用paraformer识别模型的的ASR模型得到又一语音识别结果text_paraformer;
对以上4个语音识别结果进行片段投票得到投票得到融合的投票结果text_vote,比较出不同之处diff_spans并在text_vote上进行高亮标识;
计算4个语音识别结果的一致率correct_char_ratio。
下面对diff_spans和correct_char_ratio涉及的规则进行解释说明,以样例数据为例,投票算法首先从4个结果出选出与其余3个重合度最高的一个,即“播放蜘蛛侠”,由这个结果与其他3个结果进行片段对比,片段“播放”、“蜘蛛侠”2个片段在其他结果中都能找到匹配的片段,则说明该结果的全部字符都能得到验证,因此一致率为1。再以其它数据为例,“Run bot.”、“ron bought”、“run but”、“run barth”投票得到“run bot.” (t.标红高亮),比较出不同之处diff_spans=[{"diff_span": [6, 8], "gt": null, "common_span_strs": null}],计算出一致率correct_char_ratio=0.75。过程为首先找到了“Run bot.”,再与其他3个结果对比,片段“Run bo”可由第3和第4个结果得到验证,片段“n bo”可由第二个结果得到验证,而片段“t.”无法验证,因此一致率为6/8=0.75。
(3) 模型训练
将清洗处理好的数据用于ASR模型的训练与优化。训练过程中,将一致率大于0.9的数据作为正向训练样本,将一致率小于0.96的舍去。
(4) 模型输出
将获取到的音频输入到训练好的ASR模型中,识别音频中的文本数据。
This training dataset comprises automatically collected audio samples for training and optimizing Automatic Speech Recognition (ASR) models. This training data undergoes joint voting optimization after processing raw audio with multiple open-source ASR models, yielding higher-quality samples that help improve the robustness and generalization capability of ASR models. Well-trained ASR models can be deployed on IoT devices such as smart terminals and smart home equipment to convert user voice into text commands, facilitating people's work and daily life.
(1) Data Collection:
Audio data collected from real-time conversations and tests of Qigou Project's self-developed Wigain smart glasses is stored in WAV format.
(2) Data Cleaning and Processing:
1. Retrieve audio data from the audio file storage path `audio_path`;
2. Obtain a speech recognition result `text_qwen` using the ASR model powered by Qwen Large Language Model (LLM);
3. Obtain another speech recognition result `text_paddle` using the ASR model based on the PaddlePaddle deep learning platform;
4. Obtain an additional speech recognition result `text_whisper_turbo` using the ASR model of the Whisper Turbo speech recognition service;
5. Obtain yet another speech recognition result `text_paraformer` using the ASR model of the Paraformer recognition framework;
6. Perform segment-level voting on the above four speech recognition results to generate the fused voting result `text_vote`, identify the differing spans `diff_spans`, and highlight these spans on `text_vote`;
7. Calculate the character consistency rate `correct_char_ratio` across the four speech recognition results.
The rules governing `diff_spans` and `correct_char_ratio` are explained below, using sample data as an example. The voting algorithm first selects the result with the highest overlap with the other three from the four outputs. Taking the sample "播放蜘蛛侠" (Play Spider-Man) as an instance, both segments "播放" (Play) and "蜘蛛侠" (Spider-Man) have matching counterparts in the other three results, meaning all characters of this reference result are verified, so the consistency rate is 1.
Take another sample as an example: the four input results are "Run bot.", "ron bought", "run but", and "run barth". The voting result is "run bot." (with the substring "t." marked in red). The identified differing spans are `diff_spans=[{"diff_span": [6, 8], "gt": null, "common_span_strs": null}]`, and the calculated consistency rate is `correct_char_ratio=0.75`. The detailed process is as follows: first, "Run bot." is selected as the reference. When compared with the other three results, the segment "Run bo" can be verified by the 3rd and 4th results, the segment "n bo" can be verified by the 2nd result, while the segment "t." cannot be verified. Thus, the consistency rate is 6/8=0.75.
(3) Model Training:
The cleaned and processed data is used for training and optimizing ASR models. During the training phase, samples with a consistency rate greater than 0.9 are employed as positive training samples, while samples with a consistency rate less than 0.96 are discarded.
(4) Model Inference:
Input the collected audio into the well-trained ASR model to recognize the text data contained in the audio.
提供机构:
杭州秋果计划科技有限公司
创建时间:
2025-06-11
搜集汇总
数据集介绍
背景与挑战
背景概述
该数据集包含6192条音频转文本训练样本,每月更新,通过qwen、paddle、whisper_turbo和paraformer四种ASR模型识别后投票优化生成高质量文本,用于提升声音转文本模型的鲁棒性和泛化能力,主要应用于智能终端和物联网设备的指令识别。
以上内容由遇见数据集搜集并总结生成


