reasoning_0_chat_eval_636d
收藏Hugging Face2025-04-19 更新2025-04-20 收录
下载链接:
https://huggingface.co/datasets/mlfoundations-dev/reasoning_0_chat_eval_636d
下载链接
链接失效反馈官方服务:
资源简介:
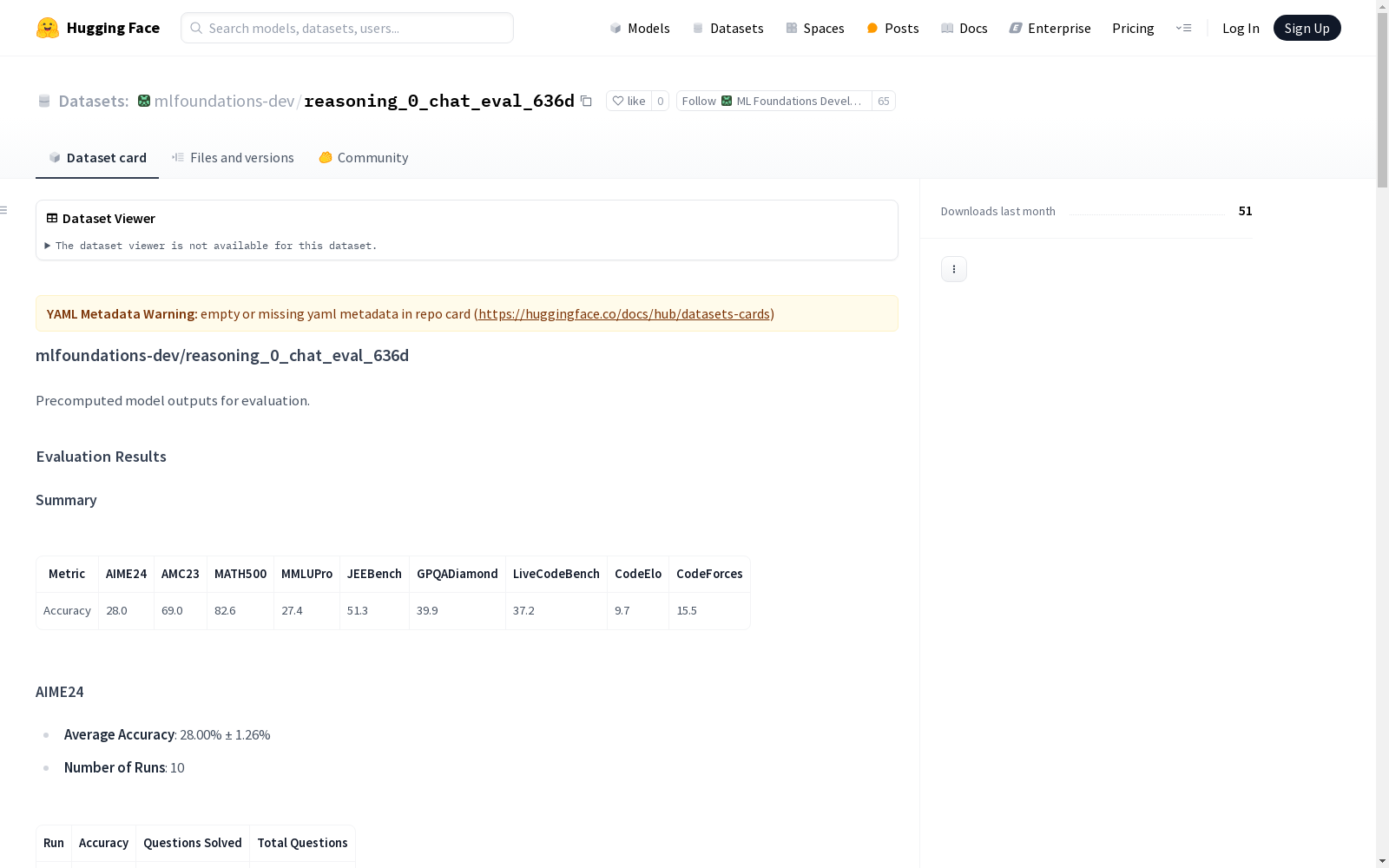
该数据集包含了不同竞赛和测试中的预计算模型输出结果,用于评估模型在数学和编程问题上的表现。数据集涵盖了多个评估指标,包括AIME24、AMC23、MATH500、MMLUPro、JEEBench、GPQADiamond、LiveCodeBench、CodeElo和CodeForces等,每个指标都有详细的准确率和问题解决情况。
创建时间:
2025-04-19
搜集汇总
数据集介绍
构建方式
在人工智能评估领域,reasoning_0_chat_eval_636d数据集通过系统化采集多维度测试结果构建而成。该数据集整合了AIME24、AMC23、MATH500等九项权威数学与编程竞赛的预计算模型输出,采用多次运行取均值的方式确保数据稳定性,其中MATH500更以单次大规模抽样(500题)形成基准参照。各子集通过标准化流程记录准确率、解题数量及题目总量,构成严谨的横向可比结构。
特点
该数据集展现出显著的学科跨度与评估深度,覆盖从中学数学竞赛到专业编程挑战的多元场景。其核心特征体现在差异化的精度分布:数学类测试(如MATH500达82.6%)显著优于编程类评估(CodeElo仅9.72%),揭示模型在不同认知任务中的能力边界。动态运行机制(如AIME24进行10次迭代)和误差区间标注,为研究者提供稳定性分析依据。
使用方法
研究者可通过对比子集性能差异开展模型诊断,例如分析数学推理与代码生成能力的相关性。典型应用场景包括:使用AMC23数据优化代数推理模块,参照LiveCodeBench结果调整代码生成策略。数据集支持两种验证模式——直接调用预计算结果进行基准测试,或基于原始答题记录进行细粒度错误分析。需注意不同子集的样本量差异(30-515题),建议结合置信区间进行统计推断。
背景与挑战
背景概述
reasoning_0_chat_eval_636d数据集由mlfoundations-dev团队构建,旨在评估模型在复杂推理任务中的表现。该数据集涵盖了多个领域的评估指标,包括数学竞赛(AIME24、AMC23、MATH500)、综合知识测试(MMLUPro)、工程入学考试(JEEBench)、编程能力评估(LiveCodeBench、CodeElo、CodeForces)以及通用问题解答(GPQADiamond)。数据集通过多轮运行和统计方法确保评估结果的可靠性,为研究者在模型推理能力评估方面提供了重要参考。
当前挑战
该数据集面临的挑战主要体现在两个方面:领域问题的复杂性和数据构建的严谨性。在领域问题方面,数据集涵盖了从数学竞赛到编程评估等多个高难度领域,模型需具备跨领域推理和深层逻辑分析能力,这对现有模型提出了极高要求。在数据构建方面,确保评估指标的全面性和统计结果的可靠性是核心挑战,需通过多轮运行和严格的数据筛选来降低随机误差,同时保持各领域评估标准的一致性。
常用场景
经典使用场景
在人工智能领域,reasoning_0_chat_eval_636d数据集被广泛用于评估模型在复杂推理任务中的表现。该数据集涵盖了数学竞赛、编程挑战和综合知识测试等多个领域,为研究者提供了一个全面的基准测试平台。通过在不同任务上的表现,模型的能力得到了多维度的验证,特别是在解决高难度数学问题和编程挑战方面。
解决学术问题
该数据集解决了模型在复杂推理任务中表现评估的标准化问题。通过提供多样化的任务和精确的评估指标,研究者能够更准确地衡量模型在数学、编程和综合知识等方面的能力。这不仅推动了模型优化技术的发展,还为人工智能在教育和科研领域的应用提供了可靠的数据支持。
衍生相关工作
围绕该数据集,研究者们开展了一系列经典工作,包括开发新的推理算法、优化模型架构以及设计更高效的评估方法。这些工作不仅提升了模型在复杂任务中的表现,还推动了人工智能在教育和科研领域的应用。例如,一些研究利用该数据集验证了新型推理模型在数学竞赛中的优越性,为后续研究提供了重要参考。
以上内容由遇见数据集搜集并总结生成


