textdetox-multilingual-toxicity-dataset
收藏TextDetox Multilingual Toxicity Classification Dataset 概述
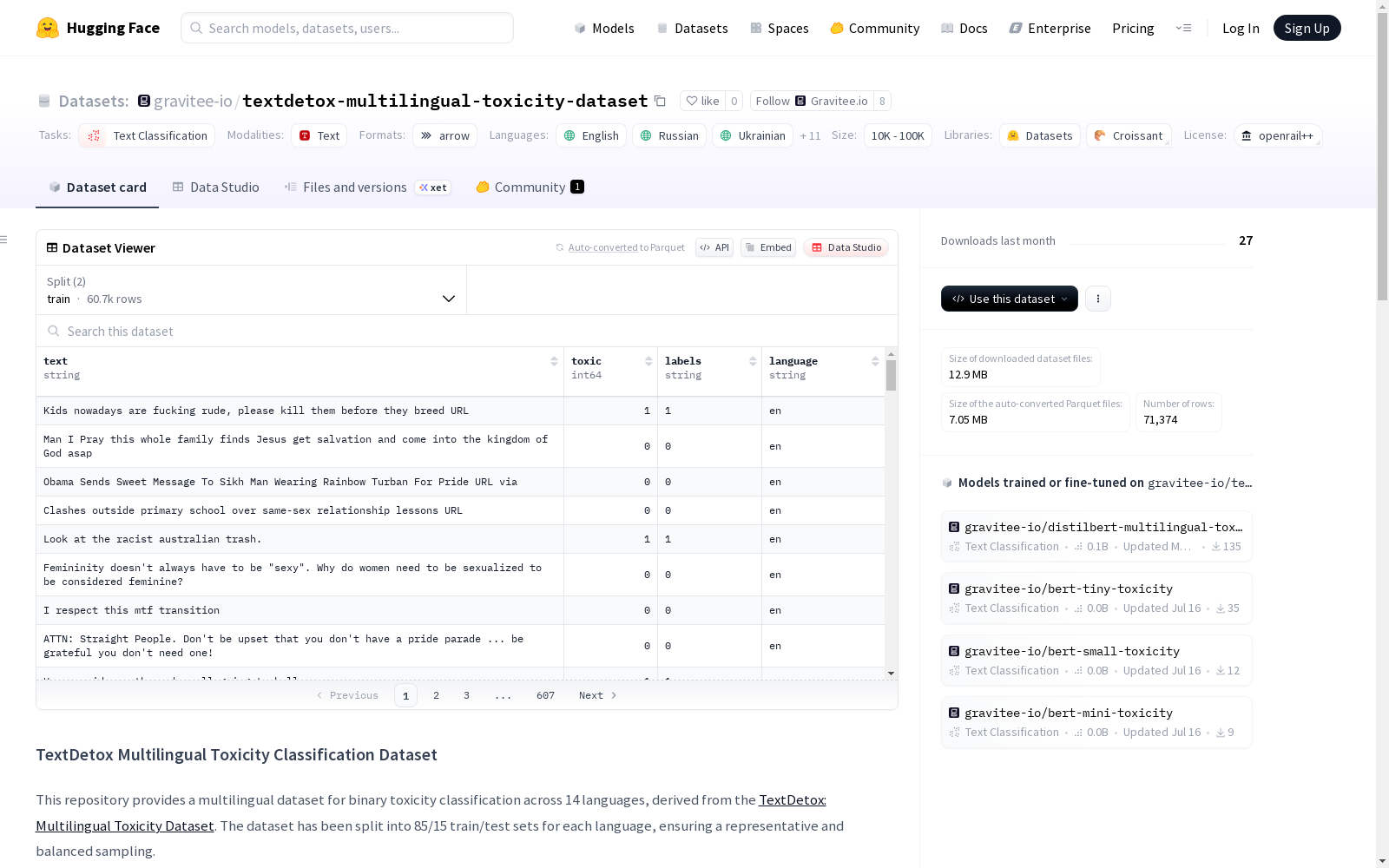
数据集基本信息
- 语言: 英语(en)、俄语(ru)、乌克兰语(uk)、德语(de)、西班牙语(es)、阿姆哈拉语(am)、中文(zh)、阿拉伯语(ar)、印地语(hi)、意大利语(it)、法语(fr)、希伯来语(he)、日语(ja)、鞑靼语(tt)
- 许可证: openrail++
- 规模: 10K<n<100K
- 任务类别: 文本分类
数据集结构
- 特征:
text: 用户生成的评论 (string)toxic: 毒性标签 (1表示有毒,0表示无毒) (int64)labels: 毒性标签的字符串形式 (string)language: 文本语言 (string)
- 数据划分:
- 训练集(train): 60,667条样本 (10,733,659字节)
- 测试集(test): 10,707条样本 (1,893,353字节)
- 划分比例: 85%训练 / 15%测试
数据来源
- 基于TextDetox: Multilingual Toxicity Dataset
- 原始数据收集、标注和多语言覆盖归功于原作者
引用信息
bibtex @inproceedings{dementieva2024overview, title={Overview of the Multilingual Text Detoxification Task at PAN 2024}, author={Dementieva, Daryna and Moskovskiy, Daniil and Babakov, Nikolay and Ayele, Abinew Ali and Rizwan, Naquee and Schneider, Frolian and Wang, Xintog and Yimam, Seid Muhie and Ustalov, Dmitry and Stakovskii, Elisei and Smirnova, Alisa and Elnagar, Ashraf and Mukherjee, Animesh and Panchenko, Alexander}, booktitle={Working Notes of CLEF 2024 - Conference and Labs of the Evaluation Forum}, year={2024}, organization={CEUR-WS.org} }
@inproceedings{dementieva-etal-2024-toxicity, title = "Toxicity Classification in {U}krainian", author = "Dementieva, Daryna and Khylenko, Valeriia and Babakov, Nikolay and Groh, Georg", booktitle = "Proceedings of the 8th Workshop on Online Abuse and Harms (WOAH 2024)", year = "2024", publisher = "Association for Computational Linguistics" }
@inproceedings{DBLP:conf/ecir/BevendorffCCDEFFKMMPPRRSSSTUWZ24, author = {Janek Bevendorff and Xavier Bonet Casals and Berta Chulvi and Daryna Dementieva and Ashaf Elnagar and Dayne Freitag and Maik Fr{"{o}}be and Damir Korencic and Maximilian Mayerl and Animesh Mukherjee and Alexander Panchenko and Martin Potthast and Francisco Rangel and Paolo Rosso and Alisa Smirnova and Efstathios Stamatatos and Benno Stein and Mariona Taul{{e}} and Dmitry Ustalov and Matti Wiegmann and Eva Zangerle}, title = {Overview of {PAN} 2024: Multi-author Writing Style Analysis, Multilingual Text Detoxification, Oppositional Thinking Analysis, and Generative {AI} Authorship Verification - Extended Abstract}, booktitle = {Advances in Information Retrieval - 46th European Conference on Information Retrieval, {ECIR} 2024}, year = {2024}, publisher = {Springer} }