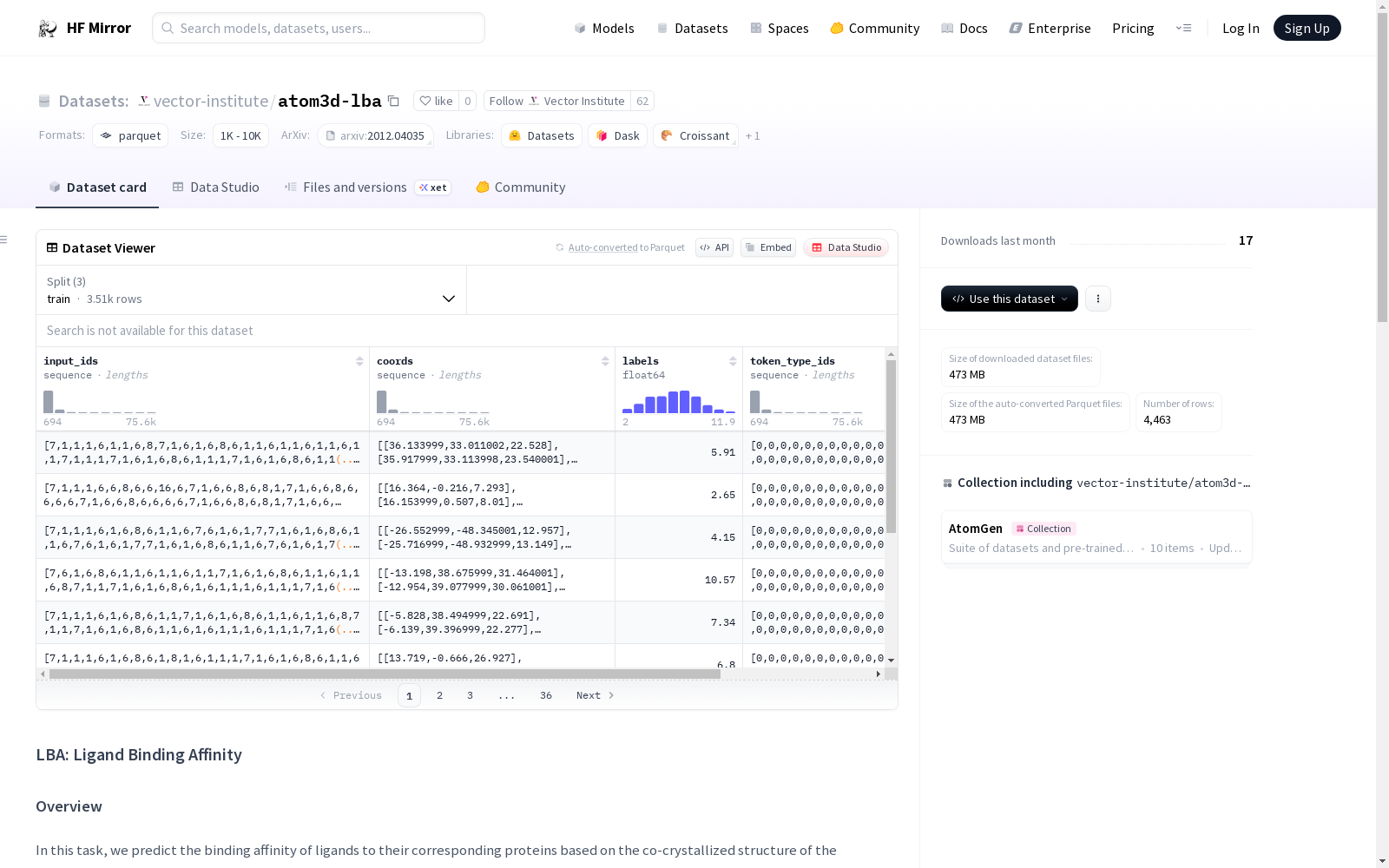
vector-institute/atom3d-lba
收藏LBA: Ligand Binding Affinity 数据集概述
概述
该数据集用于预测配体与相应蛋白质的结合亲和力,基于蛋白质-配体复合物的共结晶结构。预测的结合亲和力为pK值,定义为-log(Ki)或-log(Kd),取决于哪种测量值可用。
数据集来源于PDBBind数据库(Wang et al., 2004),该数据库是一个广泛使用的蛋白质-配体复合物数据库,包含从文献中提取的实验亲和力数据。使用2019年更新的“refined set”子集,该子集基于结构和亲和力数据的质量进行筛选。经过过滤无法被RDKit读取的配体后,最终数据集包含4,463个复合物。
数据集
- 分割方式:
- split-by-sequence-identity-30: 同一集合中没有序列相似度超过30%的蛋白质。
格式
每个数据条目包含以下键:
input_ids: 蛋白质、口袋和配体原子的原子序数集合。coords: 蛋白质、口袋和配体原子的3D坐标集合。label: 实验测量的结合亲和力,以pK表示。token_type_ids: 对应于input_ids/coords的掩码,指示哪些属于蛋白质、口袋或配体原子(0表示蛋白质,1表示口袋,2表示配体)。
引用信息
@article{townshend2020atom3d, title={Atom3d: Tasks on molecules in three dimensions}, author={Townshend, Raphael JL and V{"o}gele, Martin and Suriana, Patricia and Derry, Alexander and Powers, Alexander and Laloudakis, Yianni and Balachandar, Sidhika and Jing, Bowen and Anderson, Brandon and Eismann, Stephan and others}, journal={arXiv preprint arXiv:2012.04035}, year={2020} }
@article{wang2004pdbbind, title={The PDBbind database: Collection of binding affinities for protein- ligand complexes with known three-dimensional structures}, author={Wang, Renxiao and Fang, Xueliang and Lu, Yipin and Wang, Shaomeng}, journal={Journal of medicinal chemistry}, volume={47}, number={12}, pages={2977--2980}, year={2004}, publisher={ACS Publications} }
@article{liu2015pdb, title={PDB-wide collection of binding data: current status of the PDBbind database}, author={Liu, Zhihai and Li, Yan and Han, Li and Li, Jie and Liu, Jie and Zhao, Zhixiong and Nie, Wei and Liu, Yuchen and Wang, Renxiao}, journal={Bioinformatics}, volume={31}, number={3}, pages={405--412}, year={2015}, publisher={Oxford University Press} }