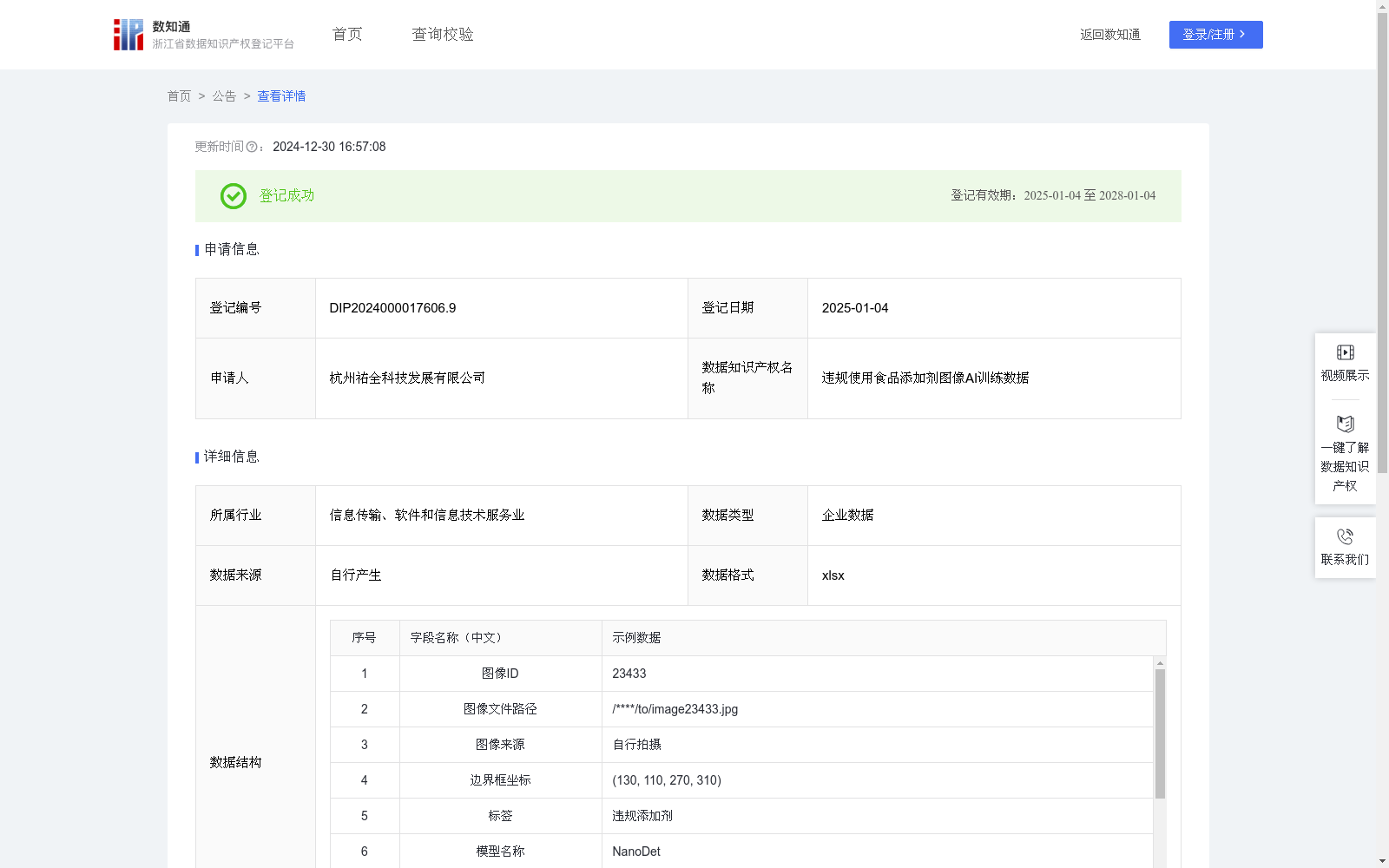
违规使用食品添加剂图像AI训练数据
收藏浙江省数据知识产权登记平台2024-12-30 更新2024-12-31 收录
下载链接:
https://www.zjip.org.cn/home/announce/trends/109422
下载链接
链接失效反馈官方服务:
资源简介:
本数据的价值在于其为构建精准、高效的违规使用食品添加剂识别AI模型提供了丰富且具针对性的信息基础。这些数据覆盖了食品加工过程中违规使用食品添加剂的关键特征,包括非法添加剂种类、超量使用、未按规定程序添加等,使AI模型能够深入学习并掌握这些因素对食品安全的影响。通过利用这些数据进行训练,AI模型能够更加准确地识别出食品加工中是否违反了食品添加剂使用规定,进而在实际应用中提供更加自动化和客观的食品添加剂使用监测。这一训练过程的核心价值在于提升AI模型的识别精确度和适应能力,确保其在面对现实食品加工和生产环境中的复杂多变情况时,能够做出更加符合食品安全管理需求的决策。1.数据采集:原始图像数据来源于自行拍摄或算法生成,确保数据来源多样化和合法性,并对原始图像的ID、文件路径进行记录。
2.数据预处理与标注:根据自身项目需求和模型要求,将违规使用食品添加剂图像数据分类成训练集和测试集,并对训练集进行标注,形成边界框坐标及对应的标签。
3.模型选择与初始化:选择NanoDet预训练模型,并初始化模型参数,设置合理的超参数,如学习率、批量大小、冗余度等,以优化模型的训练过程。
4.模型训练:使用TensorFlow深度学习框架加载和初始化模型,然后将准备好的训练集输入到模型中进行训练。在训练过程中,模型会不断调整权重,以最小化预测框与真实框之间的差值,从而提高检测的准确性,训练通常需要多个epoch(迭代次数)。
5.模型评估:在训练完成后,使用测试集对模型进行评估。计算模型在不同场景下的精度、召回率、F1分数等性能指标,确保模型的准确性和鲁棒性。
6.模型部署与实时性能评估:将最终训练、测试后得到的模型应用到具体的项目中。在实际应用中,评估模型的实时性能(即准确率),确保满足项目需求。
提供机构:
杭州祐全科技发展有限公司
创建时间:
2024-11-30
搜集汇总
数据集介绍
特点
该数据集为违规使用食品添加剂图像AI训练数据,包含620条结构化数据,用于训练和评估AI模型在食品添加剂违规识别中的性能。数据集覆盖了食品加工中违规使用添加剂的关键特征,旨在提升AI模型的识别精确度和适应能力。
以上内容由遇见数据集搜集并总结生成


