ExpliCa
收藏arXiv2025-02-21 更新2025-02-25 收录
下载链接:
https://anonymous.4open.science/r/ExpliCa-6473/
下载链接
链接失效反馈官方服务:
资源简介:
ExpliCa数据集是由比萨大学研究团队创建的,用于评估大型语言模型在显式因果推理方面的能力。该数据集包含600对英文句子,通过特定的连接词表达句子之间的因果或时间关系。数据集中的句子对经过精心设计,以确保高质量和词频平衡,并通过众包方式获得英语母语者的接受度评分,为测试各种模型提供了一个坚实的基础。ExpliCa旨在解决因果推理中的问题,特别是在评估大型语言模型在理解和区分因果和时间关系方面的能力。
The ExpliCa dataset was created by a research team at the University of Pisa to assess the explicit causal reasoning capabilities of large language models (LLMs). It comprises 600 pairs of English sentences, with specific conjunctions used to express causal or temporal relationships between each pair of sentences. The sentence pairs in the dataset are meticulously designed to ensure high quality and balanced word frequency, and their acceptability scores from native English speakers were obtained via crowdsourcing, providing a solid foundation for testing various models. ExpliCa aims to address gaps in causal reasoning research, particularly for evaluating large language models' abilities to understand and distinguish between causal and temporal relationships.
提供机构:
比萨大学
创建时间:
2025-02-21
搜集汇总
数据集介绍
构建方式
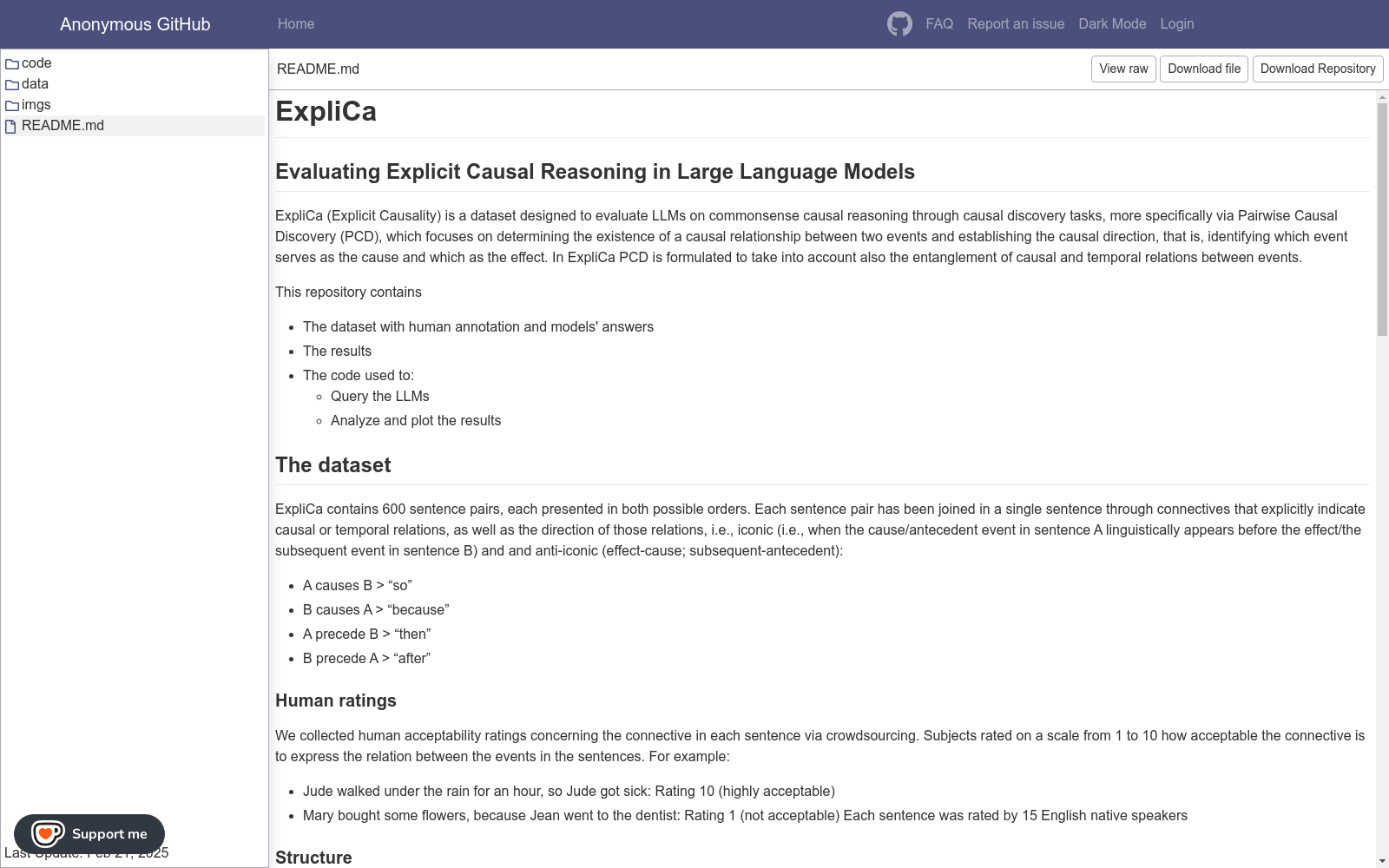
ExpliCa数据集的构建方式独特之处在于,它将因果关系和时间关系结合在一起,并以不同的语言顺序通过语言连接词明确表达。数据集包含了由人类评估员通过众包方式提供的可接受性评分,这些评估员是英语母语者。为了确保数据集的质量,研究人员通过人工检查和统计关联分析验证了数据集,并使用互信息和局部互信息来评估句子对之间的词汇关联偏差。此外,为了避免频率偏差,研究人员分析了三元组{1st sentence verb, connective, 2nd sentence verb}在enTenTen语料库中的共现频率。
使用方法
使用ExpliCa数据集时,研究人员可以对其进行提示和困惑度评估。提示评估包括三个任务:可接受性评分、完形填空和多选题。困惑度评估则是通过计算数据集中每个项目的困惑度来进行的。研究人员可以根据模型在提示评估和困惑度评估中的表现来评估模型的推理能力。此外,ExpliCa数据集还可以用于研究模型大小对推理能力的影响。
背景与挑战
背景概述
在自然语言处理领域,大型语言模型(LLMs)的推理和解释能力越来越受到关注。ExpliCa数据集的创建旨在评估LLMs在显式因果推理方面的能力。该数据集由意大利比萨大学的CoLing实验室、信息学系以及香港理工大学的中国及双语研究系的联合研究团队开发。ExpliCa数据集的独特之处在于它整合了因果和时序关系,并以不同的语言顺序通过语言连接词明确表达。此外,数据集还包含了众包人员提供的可接受性评分。研究团队对七种商业和开源LLMs进行了测试,发现即使是顶级模型也很难达到0.80的准确率。ExpliCa数据集的引入为LLMs在因果推理领域的评估提供了新的基准,对相关领域的研究产生了重要影响。
当前挑战
ExpliCa数据集面临的挑战包括:1) LLMs在区分因果和时序关系方面的能力不足,模型往往将时序关系与因果关系混淆;2) LLMs的表现受到事件的语言顺序的强烈影响;3) 使用提示生成的表现与基于困惑度的模型能力评估之间存在差异,提示方法低估了模型的实际语言知识;4) 模型规模对任务表现和因果推理能力的影响需要进一步研究。
常用场景
经典使用场景
ExpliCa数据集主要用于评估大型语言模型(LLMs)在显式因果推理方面的能力。该数据集通过提供明确表达因果和时序关系的句子对,并附带众包收集的人类可接受性评分,为研究LLMs在理解自然语言文本中的因果效应关系提供了新的视角。ExpliCa数据集的经典使用场景包括评估LLMs在不同情境下区分因果和时序关系的能力,以及研究LLMs的生成能力和内部知识之间的关系。通过对多个LLMs进行测试,ExpliCa揭示了即使是最先进的模型在显式因果推理任务上也存在局限性,为LLMs在需要解释性和推理准确性的领域中的应用提供了重要的参考。
解决学术问题
ExpliCa数据集解决了LLMs在显式因果推理方面的评估难题。传统的因果推理评估方法往往只关注因果关系的存在与否,而忽视了因果关系与时间先后关系之间的紧密联系。ExpliCa数据集通过引入明确表达因果和时序关系的连接词,以及众包收集的人类可接受性评分,为LLMs的因果推理能力评估提供了更全面和可靠的基准。ExpliCa数据集的出现,有助于推动LLMs在因果推理领域的进一步发展,并为LLMs在需要解释性和推理准确性的领域中的应用提供了重要的参考。
实际应用
ExpliCa数据集在实际应用中具有广泛的应用前景。例如,在医疗领域,ExpliCa可以用于评估LLMs在理解医疗文献中的因果关系的准确性,从而辅助医生进行诊断和治疗决策。在法律领域,ExpliCa可以用于评估LLMs在理解法律条文中的因果关系的准确性,从而辅助律师进行法律分析和案件处理。在新闻分析领域,ExpliCa可以用于评估LLMs在理解新闻事件中的因果关系的准确性,从而辅助新闻工作者进行新闻分析和报道。
数据集最近研究
最新研究方向
ExpliCa数据集的引入为大型语言模型(LLMs)在显式因果推理方面的评估提供了新的视角。该数据集的独特之处在于,它将因果关系和时序关系相结合,并以不同的语言顺序和显式的语言连接词表达。ExpliCa数据集通过众包方式获得了人类可接受性评分,为测试LLMs在显式因果推理方面的能力提供了丰富的数据基础。研究结果表明,即使是顶级的LLMs模型在ExpliCa数据集上也难以达到0.80的准确率,这表明LLMs在理解因果关系方面仍然存在挑战。此外,LLMs倾向于混淆时序关系和因果关系,并且其性能也受到事件的语言顺序的强烈影响。ExpliCa数据集的最新研究揭示了LLMs在显式因果推理方面的局限性,并为未来的研究提供了有价值的方向。
相关研究论文
- 1ExpliCa: Evaluating Explicit Causal Reasoning in Large Language Models比萨大学 · 2025年
以上内容由遇见数据集搜集并总结生成


