有没有相关的论文或文献参考?
这个数据集是基于什么背景创建的?
数据集的作者是谁?
能帮我联系到这个数据集的作者吗?
这个数据集如何下载?
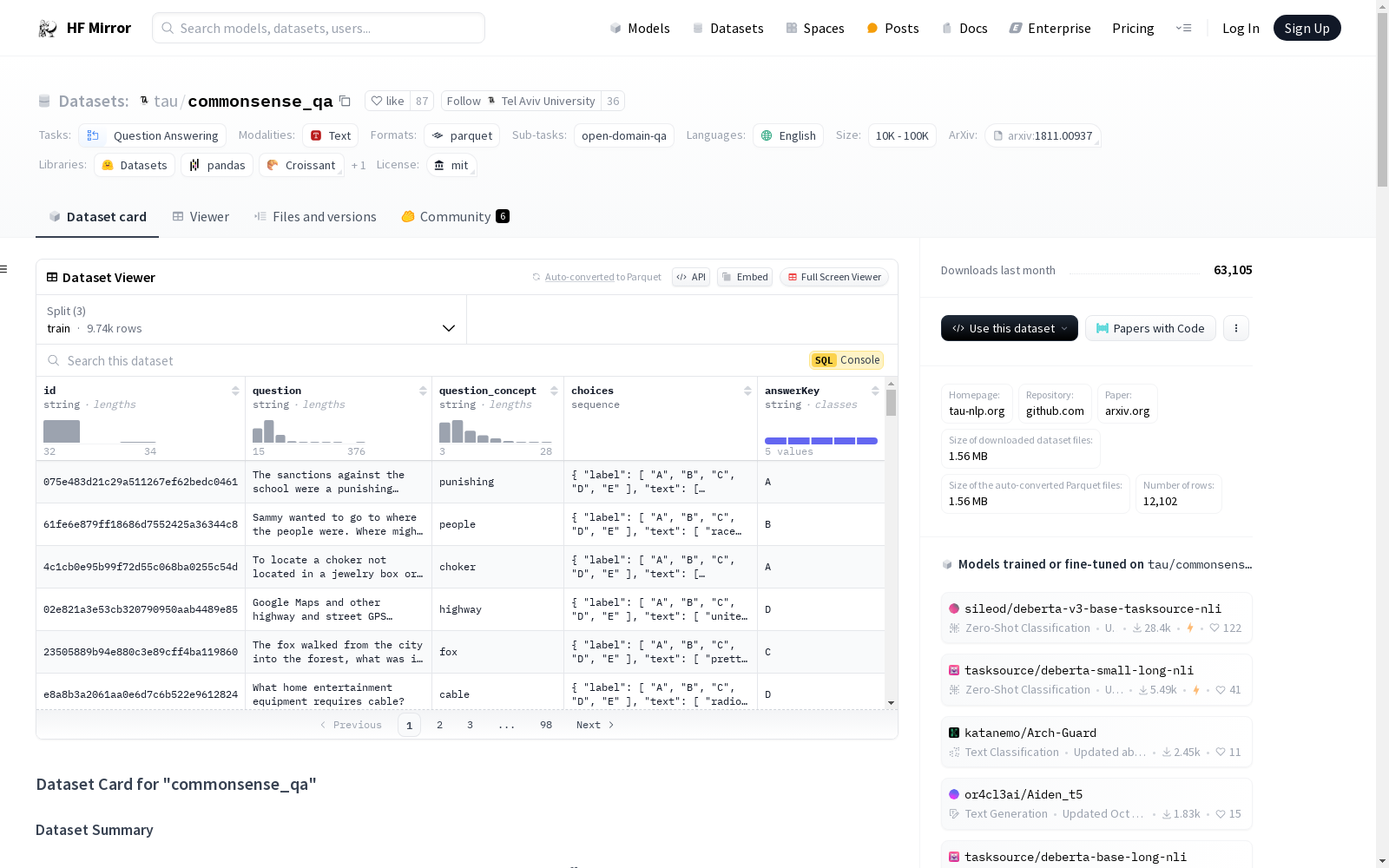
en)id: 字符串类型,唯一ID。question: 字符串类型,问题描述。question_concept: 字符串类型,与问题相关的概念。choices: 字典类型,包含选项标签和文本。
label: 字符串类型,选项标签。text: 字符串类型,选项文本。answerKey: 字符串类型,正确答案。train: 9741个样本,2207794字节。validation: 1221个样本,273848字节。test: 1140个样本,257842字节。许可证: MIT,详细信息见此链接。
引用信息:
@inproceedings{talmor-etal-2019-commonsenseqa, title = "{C}ommonsense{QA}: A Question Answering Challenge Targeting Commonsense Knowledge", author = "Talmor, Alon and Herzig, Jonathan and Lourie, Nicholas and Berant, Jonathan", booktitle = "Proceedings of the 2019 Conference of the North {A}merican Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers)", month = jun, year = "2019", address = "Minneapolis, Minnesota", publisher = "Association for Computational Linguistics", url = "https://aclanthology.org/N19-1421", doi = "10.18653/v1/N19-1421", pages = "4149--4158", archivePrefix = "arXiv", eprint = "1811.00937", primaryClass = "cs", }
LIDC-IDRI
LIDC-IDRI 数据集包含来自四位经验丰富的胸部放射科医师的病变注释。 LIDC-IDRI 包含来自 1010 名肺部患者的 1018 份低剂量肺部 CT。
OpenDataLab 收录
Figshare
Figshare是一个在线数据共享平台,允许研究人员上传和共享各种类型的研究成果,包括数据集、论文、图像、视频等。它旨在促进科学研究的开放性和可重复性。
figshare.com 收录
Breast Cancer Dataset
该项目专注于清理和转换一个乳腺癌数据集,该数据集最初由卢布尔雅那大学医学中心肿瘤研究所获得。目标是通过应用各种数据转换技术(如分类、编码和二值化)来创建一个可以由数据科学团队用于未来分析的精炼数据集。
github 收录
MedDialog
MedDialog数据集(中文)包含了医生和患者之间的对话(中文)。它有110万个对话和400万个话语。数据还在不断增长,会有更多的对话加入。原始对话来自好大夫网。
github 收录
RadDet
RadDet是一个包含11种雷达类别的数据集,包括6种新的低概率干扰(LPI)多相码(P1, P2, P3, P4, Px, Zadoff-Chu)和一种新的宽带调频连续波(FMCW)。数据集覆盖500 MHz频段,包含40,000个雷达帧,分为训练集、验证集和测试集。数据集在两种不同的雷达环境中提供:稀疏数据集(RadDet-1T)和密集数据集(RadDet-9T)。
github 收录