search-arena-v1-nuggets-with-urls-5k
收藏Hugging Face2025-05-23 更新2025-05-24 收录
下载链接:
https://huggingface.co/datasets/castorini/search-arena-v1-nuggets-with-urls-5k
下载链接
链接失效反馈官方服务:
资源简介:
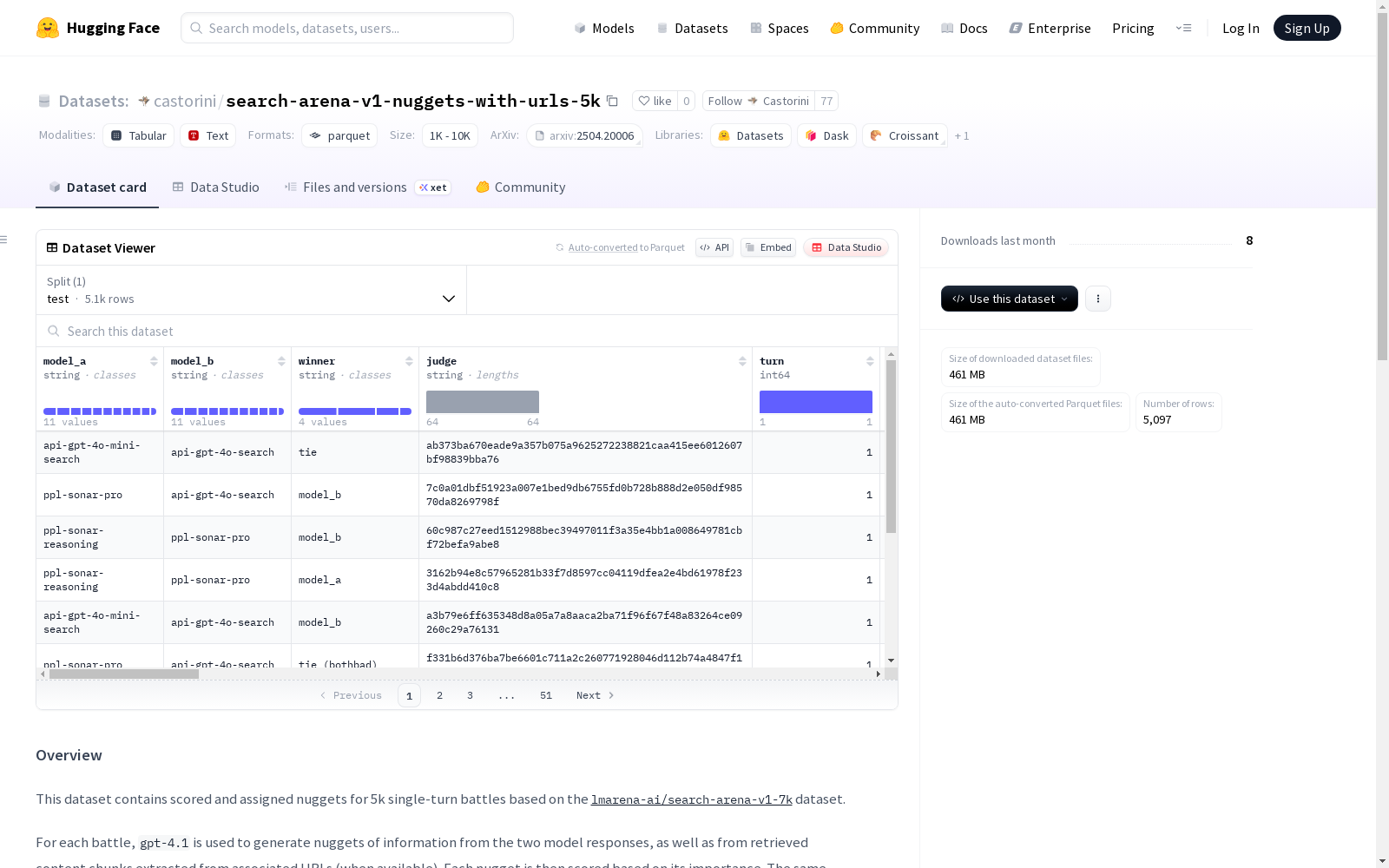
该数据集包含了基于lmarena-ai/search-arena-v1-7k数据集的5k个单轮战斗的信息块,这些信息块由gpt-4.1生成,包括两个模型响应和相关URL内容块。每个信息块根据其重要性进行评分,并分配给两个模型响应。数据集还包括了原始lmarena-ai/search-arena-v1-7k数据集的额外字段,用于生成信息块和评估。
提供机构:
Castorini创建时间:
2025-05-23
搜集汇总
数据集介绍
构建方式
在信息检索与自然语言处理交叉领域,search-arena-v1-nuggets-with-urls-5k数据集通过多阶段流程构建而成。该数据集基于lmarena-ai/search-arena-v1-7k的单轮对话数据,首先从4.7万个关联URL中提取文本内容,采用spaCy模型将文本分割为重叠的句子块。随后通过BAAI/bge-m3模型进行语义编码,利用Pyserini和FAISS实现稠密检索,最终结合GPT-4.1模型生成信息片段并完成重要性评分与分配。
特点
该数据集在对话系统评估领域展现出独特价值,其核心特征体现在多维度的结构化标注体系。每个数据点不仅包含原始对话内容与模型响应,还整合了从URL内容块提取的信息片段及其重要性评分。特别设计的片段分配机制与量化指标,包括严格关键分数和全局分数等四个维度的评估标准,为理解模型响应质量提供了细粒度分析框架。
使用方法
研究人员可借助该数据集开展对话系统性能的深入分析,通过解析片段分配结果与量化指标,揭示不同模型在信息覆盖度与关键内容捕捉能力的差异。数据集支持端到端的评估流程复现,用户可参照提供的GitHub仓库实现片段生成与分配的全流程,亦可基于丰富的元数据字段进行自定义分析,推动对话系统可解释性研究的发展。
背景与挑战
背景概述
在大型语言模型评估领域,2025年发布的search-arena-v1-nuggets-with-urls-5k数据集由Castorini研究团队构建,旨在解决对话系统响应质量的可解释性评估难题。该数据集基于Chatbot Arena对战平台,通过GPT-4.1模型自动生成信息单元并关联网络检索内容,创新性地将传统检索增强生成与细粒度评估相结合。其核心价值在于为LLM响应质量提供了基于信息覆盖度的量化指标,推动了对话系统评估从黑箱比较向可解释诊断的范式转变。
当前挑战
该数据集面临双重挑战:在领域问题层面,需解决多轮对话中信息完整性与准确性的平衡问题,以及跨领域知识单元的重要性量化难题;在构建过程中,面临47,000个网页内容的动态获取与语义对齐的技术瓶颈,同时需处理多语言文本分块与密集检索的工程复杂性。此外,信息单元自动标注过程中存在的模型偏好偏差,以及不同来源引用的可信度评估,均为数据集质量保障带来持续挑战。
常用场景
经典使用场景
在大型语言模型评估领域,该数据集通过构建双模型对战框架与信息块标注机制,为对话系统性能比较提供了标准化测试平台。其核心价值在于利用GPT-4生成的信息单元及其重要性评分,系统化分析不同模型在知识覆盖度、信息准确性和响应质量等方面的差异,成为学术界进行模型能力横向对比的重要基准。
解决学术问题
该数据集有效解决了传统评估方法中主观性强、维度单一的问题,通过量化指标如严格核心分数和全局分数,为模型性能评估提供了可复现的客观标准。其创新性地将信息块分配机制引入评估体系,不仅揭示了模型在关键信息捕捉能力的差异,更推动了可解释性人工智能研究的发展,为理解模型决策过程提供了新视角。
衍生相关工作
基于该数据集衍生的经典研究包括多模态信息融合评估框架、动态知识更新机制设计等方向。相关工作进一步扩展了信息块评估方法论,开发出适用于长文本对话的层次化评估体系,并催生了面向领域自适应评估的数据集变体,持续推动着对话系统评估范式的革新与演进。
以上内容由遇见数据集搜集并总结生成


