MTSAIR/MWS-Vision-Bench
收藏Hugging Face2026-05-01 更新2025-10-18 收录
下载链接:
https://hf-mirror.com/datasets/MTSAIR/MWS-Vision-Bench
下载链接
链接失效反馈官方服务:
资源简介:
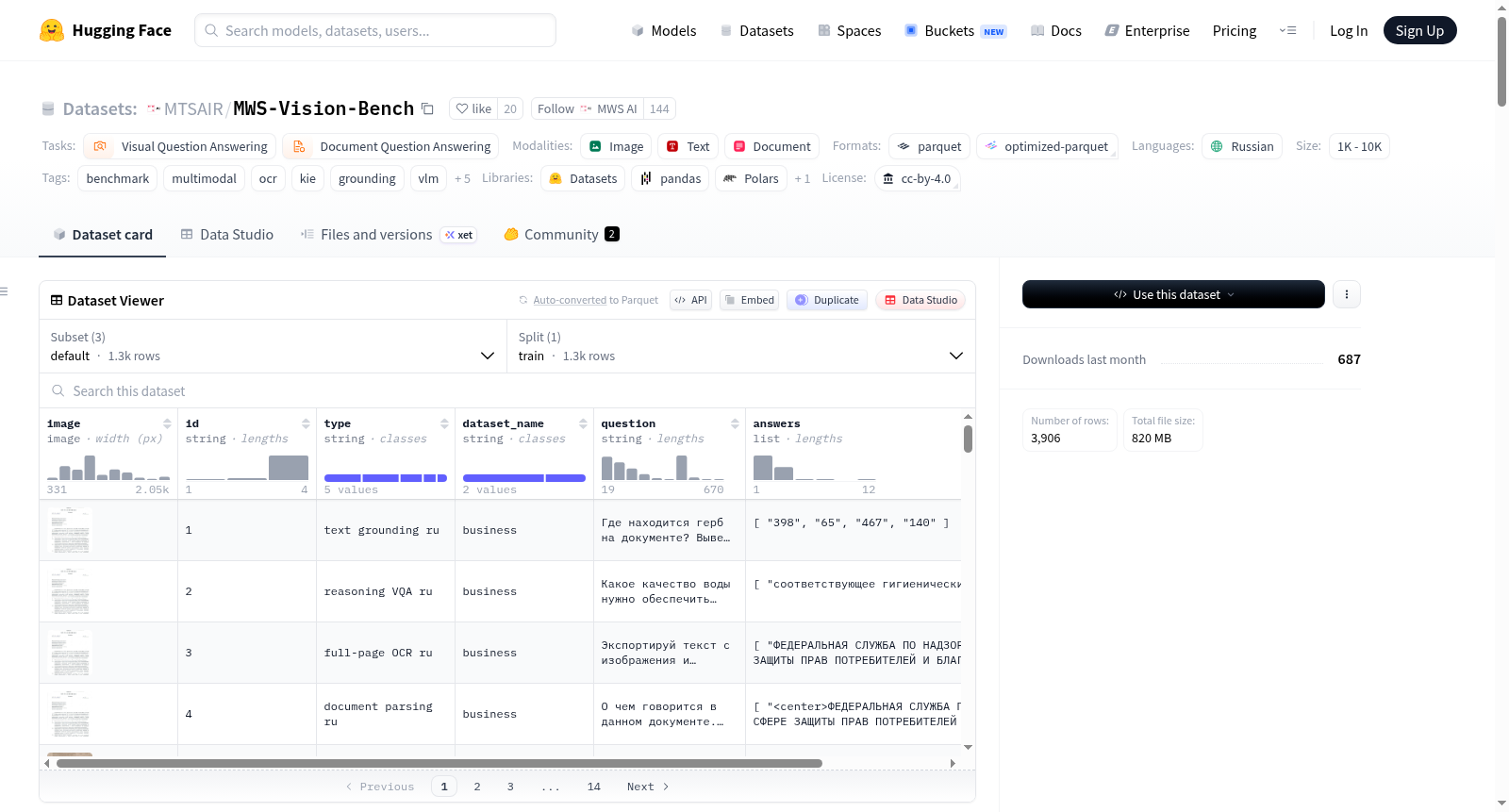
MWS Vision Bench是一个俄语商业OCR基准数据集,包含1302个样本和5种任务类型,用于评估和促进多模态大型语言模型在俄语环境下的发展和应用。
MWS Vision Bench is a Russian-language business-OCR benchmark containing 1302 samples and 5 task types, designed for evaluating and advancing multimodal large language models in a Russian context.
提供机构:
MTSAIR
搜集汇总
数据集介绍
构建方式
MWS-Vision-Bench是首个面向俄语商业场景的多模态OCR基准数据集,由MTS AI研究团队精心构建。该数据集包含1302个样本和400张独特图像,覆盖商业文档、手写笔记、技术图纸、收据等多种真实业务文档类型。其构建过程遵循严格的质量控制,由专家生成标注,涵盖文档解析、全页OCR、关键信息提取、推理型视觉问答和文本区域定位五大任务类别。数据集以JSONL格式存储元数据,每一条目包含图像路径、唯一标识符、任务类型、问题及多个有效答案,确保了评估的准确性和鲁棒性。
特点
该数据集的显著特色在于其多语言支持和任务多样性。数据集提供俄语、英语和中文三种语言配置,便于全球研究者进行跨语言评估。其任务设计覆盖了从基础OCR到高级视觉推理的全谱系,包括文档解析(243项)、全页OCR(144项)、关键信息提取(119项)、推理型VQA(400项)和文本定位(396项)。特别值得一提的是,数据集引入了专门的推理型VQA类别,并经过精心更新以提升评估可靠性,同时保持了基准测试结构的完整性。
使用方法
使用MWS-Vision-Bench进行评估十分便捷。研究者可通过Hugging Face的datasets库直接加载数据,支持通过配置参数选择语言版本:'load_dataset("MTSAIR/MWS-Vision-Bench")'加载俄语版,或指定'en'和'zh'参数获取英语和中文版本。数据集仅提供训练集分割,适合作为验证集进行公平的公开评估。使用者可遍历数据项,获取图像、任务类型、问题及标准答案列表,对多模态大语言模型进行全面评测。如需在私有测试集上评估模型性能,可通过电子邮件联系团队提交申请。
背景与挑战
背景概述
随着多模态大语言模型(MLLMs)的迅猛发展,其在文档理解与光学字符识别(OCR)领域的应用日益广泛,然而针对非英语、尤其是俄语商务场景的评估基准却长期缺位。为弥合这一鸿沟,MTS AI Research团队于2025年发布了MWS-Vision-Bench,这是首个专门面向俄语商务OCR的多模态基准数据集,共包含1302个样本与5种任务类型,涵盖文档解析、全页OCR、关键信息抽取、视觉推理与文本定位。该数据集源自俄罗斯真实商业场景,旨在系统评估MLLMs在处理俄语文档时的能力,为多模态模型在低资源语言与领域特异性任务上的表现提供标准化衡量尺度,对推动多模态OCR技术的实用化与地域化发展具有重要开创意义。
当前挑战
MWS-Vision-Bench所解决的领域挑战主要在于:现有OCR基准多集中于英语场景,缺乏对俄语商务文档中复杂版式、手写与印刷混合、以及专业术语的理解评估,导致多模态模型在此类真实商业情境下的泛化能力难以衡量。在构建过程中,团队面临着多重困难:首先是数据采集的瓶颈,需从真实商业文档(如票据、手写记录、技术图纸)中筛选并标注具有代表性的样本;其次是任务设计的复杂性,需针对俄语特有的语法形态与文档结构设计多类型任务以覆盖完整业务流;最后是多语言QA的标注一致性维护,确保俄语、英语和中文问句在语义与答案空间上的等价性,从而支持跨语言评估的可靠性。
常用场景
经典使用场景
MWS-Vision-Bench作为首个面向俄语商业场景的多模态OCR基准数据集,其经典使用场景聚焦于评估和推动视觉语言模型在真实商业文档理解中的能力。该数据集涵盖了文档解析、全页OCR、关键信息提取、视觉推理问答及文本定位五种核心任务,通过1302个精心标注的样本,为研究者提供了从图像到结构化信息抽取的全链路评测平台。图像内容既包含扫描合同、技术图纸等商业文书,也涵盖手写笔记等个人文档,使得该基准能够全面衡量模型在复杂版式、多语言混合文本以及非结构化场景下的鲁棒性表现。研究者常利用该数据集的标准设置(俄语提问)或英文、中文配置,在统一框架下横向对比不同多模态大模型在俄语商业OCR任务上的性能差异。
实际应用
在实际产业应用中,MWS-Vision-Bench所模拟的场景直接映射到大量俄语商业文档的自动化处理需求,包括但不限于发票信息抽取、合同条款比对、技术图纸解读以及手写表格转写等。金融机构可利用该基准选取合适的模型,实现从扫描贷款申请表、银行回单等文档中精准提取关键字段,大幅减少人工录入成本与差错率。物流与电商平台可借助视觉语言模型完成运单地址识别、货物清单核对等任务,提升供应链流转效率。此外,在俄语政府部门与大型企业中,该数据集支持的文档解析能力能够推动档案数字化进程,实现海量历史文件的智能化检索与分类。微软、谷歌等科技巨头已在模型中针对该基准进行优化,显示出其在商业级OCR解决方案选型中的实际指导价值。
衍生相关工作
MWS-Vision-Bench的推出催生了一系列围绕俄语多模态文档理解的衍生工作。该数据集本身作为验证集,已吸引众多研究者提交模型结果并形成公开排行榜,其中Claude-4.6-Opus、Gemini-2.5-pro等模型在总体得分上的竞争直接推动了多模态大模型对俄语版式感知能力的改进。基于此基准,研究者开始探索针对文本定位任务性能瓶颈的专项改进方法,例如设计混合视觉-语言注意力机制以增强模型对文档中微小文本区域的敏感度。此外,该数据集的多语言配置(俄文、英文、中文)促进了跨语言迁移学习研究,一些工作致力于利用英语或中文预训练模型在俄语商业文档任务上进行微调,并分析其零样本泛化能力。未来,该数据集有望成为俄语文档大语言模型(DocLLM)评估的标准参考,激发更多关于少样本学习、对抗样本鲁棒性及业务文本生成等方向的探索。
以上内容由遇见数据集搜集并总结生成


