botp/firefly-train-1.1M
收藏Hugging Face2023-08-16 更新2024-03-04 收录
下载链接:
https://hf-mirror.com/datasets/botp/firefly-train-1.1M
下载链接
链接失效反馈官方服务:
资源简介:
本数据集应用于训练名为Firefly的中文对话式大语言模型,训练后得到的模型为firefly-1b4。数据集包含了23个常见的中文数据集,每个任务都有若干种人工书写的指令模板,确保了数据的高质量和丰富度,总数据量为115万。每条数据的格式包括任务类型、输入和目标输出。
This dataset is utilized for training the Chinese conversational large language model (LLM) named Firefly, and the resulting trained model is firefly-1b4. The dataset comprises 23 common Chinese datasets, each task with multiple manually written instruction templates to ensure high data quality and richness, with a total of 1.15 million data entries. Each data entry includes the task type, input and target output.
提供机构:
botp
原始信息汇总
数据集概述
应用项目
- 本数据集应用于项目:Firefly(流萤): 中文对话式大语言模型。
- 训练后得到的模型为firefly-1b4。
数据集描述
- 收集了23个常见的中文数据集。
- 每个任务由人工书写若干种指令模板,保证数据的高质量与丰富度。
- 数据量为115万。
数据分布
- 数据分布如下图所示:

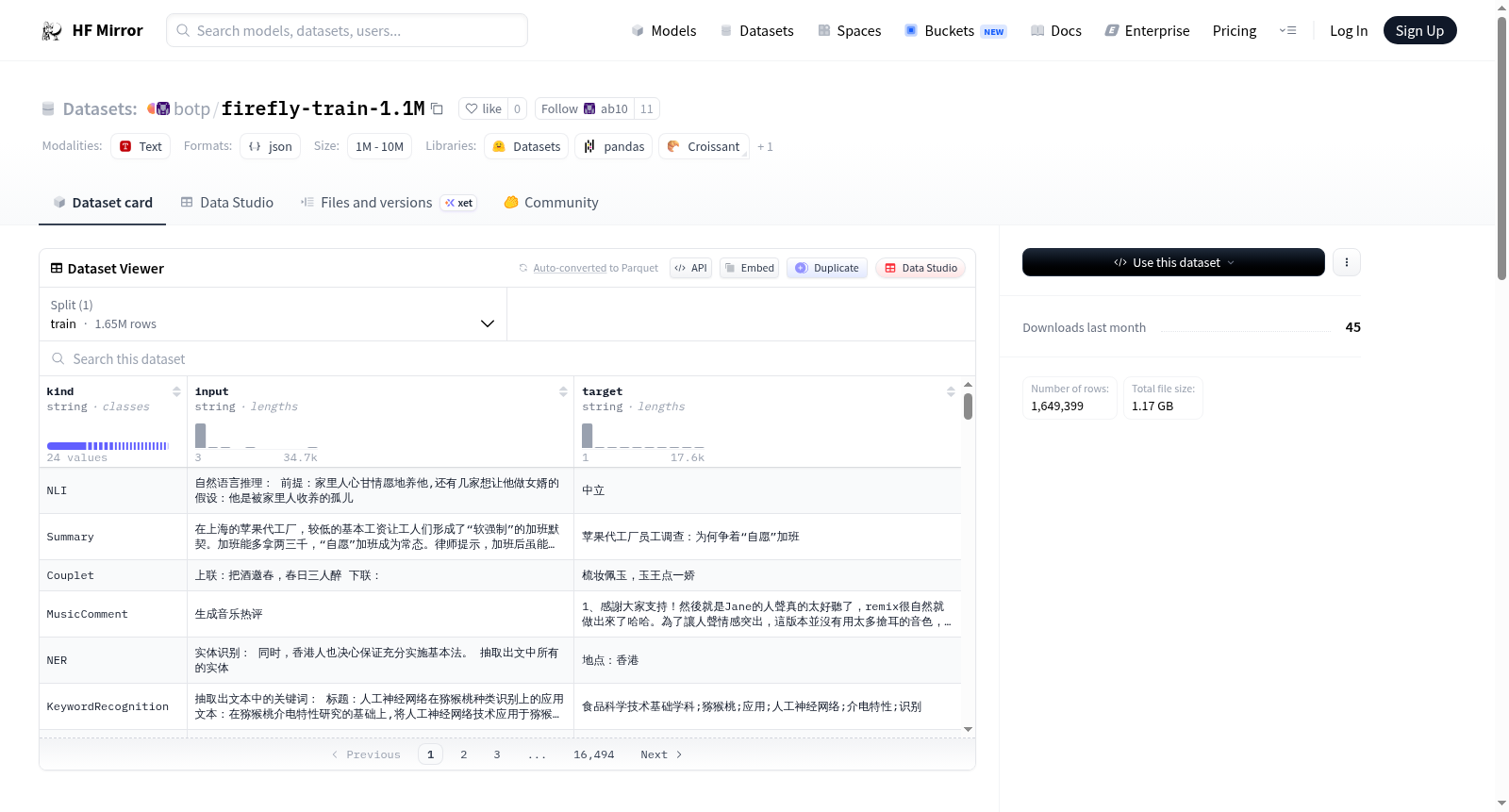
数据格式
- 每条数据的格式如下,包含任务类型、输入、目标输出: json { "kind": "ClassicalChinese", "input": "将下面句子翻译成现代文: 石中央又生一树,高百余尺,条干偃阴为五色,翠叶如盘,花径尺余,色深碧,蕊深红,异香成烟,著物霏霏。", "target": "大石的中央长着一棵树,一百多尺高,枝干是彩色的,树叶有盘子那样大,花的直径有一尺宽,花瓣深蓝色,花中飘出奇异的香气笼罩着周围,如烟似雾。" }
数据长度分布
- 训练数据集的token长度分布如下图所示,绝大部分数据的长度都小于600:

搜集汇总
数据集介绍
构建方式
在自然语言处理领域,高质量指令数据对模型性能至关重要。Firefly-train-1.1M数据集的构建基于23个常见中文数据集,通过人工精心设计多样化的指令模板,确保每条数据均包含任务类型、输入与目标输出,从而形成规模达115万条的高质量训练样本。这一过程强调人工介入,有效提升了数据的准确性与丰富度,为模型训练奠定了坚实基础。
使用方法
使用该数据集时,研究人员可将其直接应用于对话式大语言模型的训练,如Firefly项目所示范。通过解析JSON格式中的任务类型、输入与目标输出字段,模型能够学习到多样化的指令响应模式。在实际应用中,建议结合数据分布图进行样本筛选,以优化训练效果,并可通过HuggingFace平台便捷加载与集成,推动中文自然语言处理技术的发展。
背景与挑战
背景概述
在自然语言处理领域,构建高质量的中文指令数据集对于推动对话式大语言模型的发展至关重要。Firefly-train-1.1M数据集由YeungNLP团队于2023年创建,旨在支持Firefly项目训练中文对话模型。该数据集整合了23个常见中文任务,通过人工设计多样化的指令模板,确保了数据的丰富性与准确性,数据量达115万条,涵盖了古典汉语翻译、文本生成等多种任务类型。其核心研究问题在于如何通过结构化指令数据提升模型在中文语境下的理解和生成能力,对促进中文大语言模型的实用化与性能优化产生了显著影响。
当前挑战
Firefly-train-1.1M数据集面临的挑战主要集中于两个方面:在领域问题层面,中文自然语言处理任务具有高度的复杂性和多样性,如古典汉语与现代汉语的语义鸿沟、多任务指令的统一表示等,这要求数据集能够精准捕捉语言细微差别并支持跨任务泛化;在构建过程中,挑战包括从多个来源收集并清洗高质量数据,确保指令模板的人工设计既覆盖广泛任务又避免偏差,同时维持数据长度分布的均衡性以优化模型训练效率,这些因素共同增加了数据集的构建难度与技术要求。
常用场景
经典使用场景
在自然语言处理领域,高质量的中文指令数据集对于推动对话式大语言模型的发展至关重要。Firefly-train-1.1M数据集通过整合23个常见中文任务,并辅以人工精心设计的指令模板,为模型训练提供了丰富而规范的语料。该数据集最经典的使用场景在于支持中文对话式大语言模型的监督微调,帮助模型理解多样化任务指令并生成准确、连贯的响应,从而显著提升模型在开放域对话和多任务处理中的泛化能力。
解决学术问题
当前中文自然语言处理研究常面临高质量指令数据稀缺、任务多样性不足的挑战。Firefly-train-1.1M数据集通过涵盖古典文翻译、文本摘要、问答等多种任务类型,并确保数据经过人工校验,有效解决了指令跟随数据匮乏的问题。其意义在于为学术界提供了一个标准化、大规模的中文指令微调基准,促进了对话模型在理解复杂指令、跨任务迁移学习等方面的研究进展,对推动中文大语言模型的技术创新具有深远影响。
实际应用
在实际应用层面,基于Firefly-train-1.1M训练的模型可广泛应用于智能客服、教育辅助、内容创作等场景。例如,在客户服务中,模型能够依据用户指令提供精准的问答支持;在教育领域,它可协助完成古文翻译、文本润色等任务。该数据集通过覆盖日常与专业领域指令,使模型具备更强的实用性和适应性,为开发高效、可靠的中文自然语言处理应用提供了坚实的数据基础。
数据集最近研究
最新研究方向
在中文自然语言处理领域,Firefly-train-1.1M数据集凭借其高质量、多任务的指令模板设计,已成为推动对话式大语言模型发展的关键资源。当前研究聚焦于利用该数据集优化模型在复杂指令理解与跨任务泛化能力上的表现,探索少样本学习与领域自适应技术,以应对实际应用中的多样化需求。相关热点事件包括开源社区对中文大模型训练范式的广泛讨论,该数据集通过整合23个常见任务,促进了模型在古典文学翻译、知识问答等场景的精准生成,对提升中文AI系统的实用性与可及性具有显著意义。
以上内容由遇见数据集搜集并总结生成


