record
收藏Hugging Face2025-05-06 更新2025-05-07 收录
下载链接:
https://huggingface.co/datasets/rbelanec/record
下载链接
链接失效反馈官方服务:
资源简介:
这是一个包含答案、索引、输入和目标字符串的数据集,适用于文本处理任务。数据集分为训练集(138,854个示例,大小约185MB),验证集(15,176个示例,大小约20MB)和测试集(10,000个示例,大小约13MB)。总下载大小约为73MB,解压后大小约为218MB。
This is a dataset containing answers, indexes, inputs and target strings, suitable for text processing tasks. The dataset is divided into training set (138,854 examples, approximately 185 MB in size), validation set (15,176 examples, approximately 20 MB in size) and test set (10,000 examples, approximately 13 MB in size). The total download size is about 73 MB, and the unzipped size is approximately 218 MB.
创建时间:
2025-04-29
原始信息汇总
数据集概述
基本信息
- 数据集名称: rbelanec/record
- 下载大小: 73,732,174 字节
- 数据集大小: 218,256,432 字节
数据特征
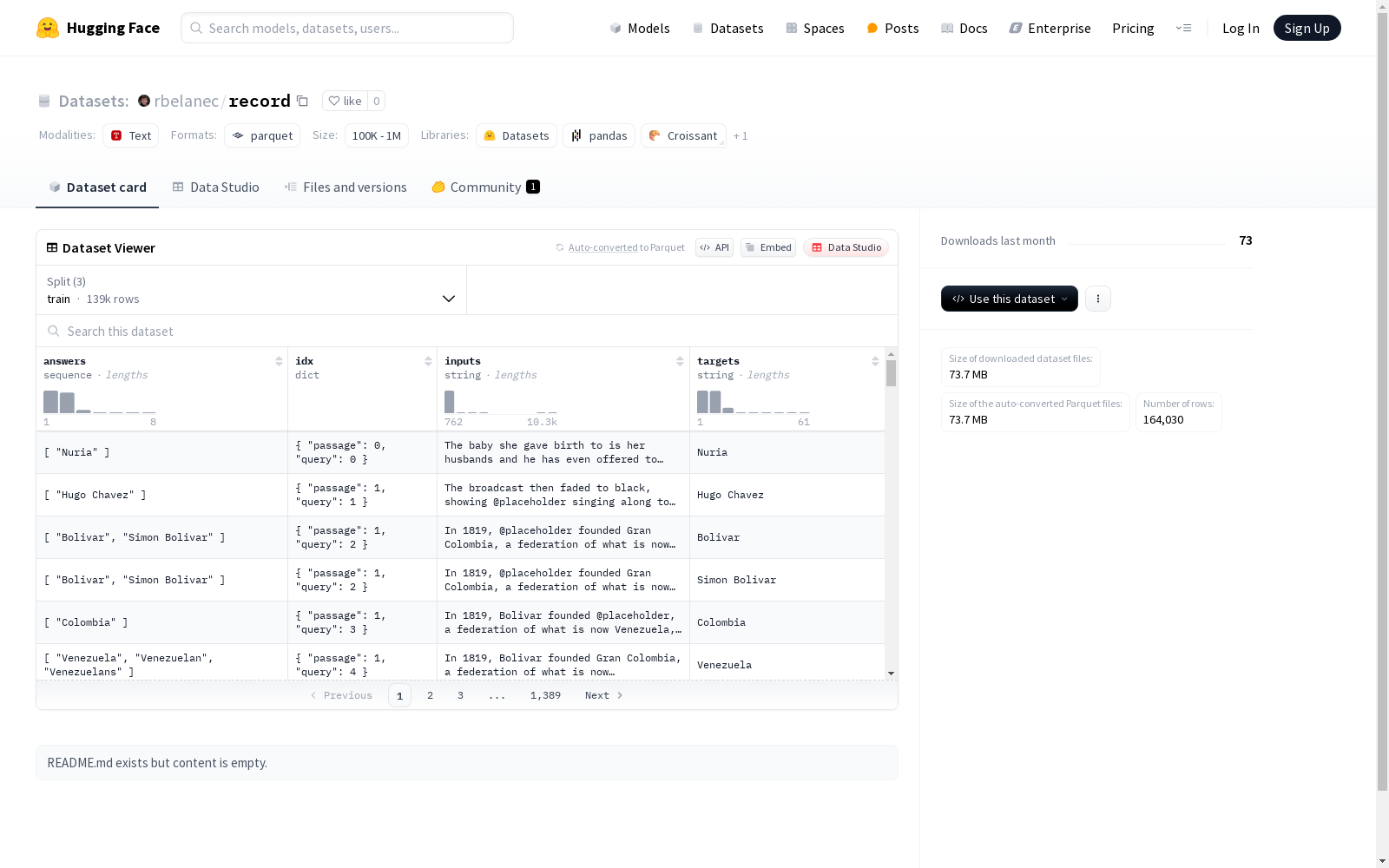
- answers: 字符串序列
- idx: 结构体
- passage: int32
- query: int32
- inputs: 字符串
- targets: 字符串
数据划分
- train
- 样本数量: 138,854
- 大小: 185,325,473 字节
- validation
- 样本数量: 15,176
- 大小: 20,017,454 字节
- test
- 样本数量: 10,000
- 大小: 12,913,505 字节
配置文件
- config_name: default
- train: data/train-*
- validation: data/validation-*
- test: data/test-*
搜集汇总
数据集介绍
构建方式
在自然语言处理领域,record数据集的构建体现了对问答系统研究的深度支持。该数据集通过结构化设计,将样本划分为训练集、验证集和测试集三部分,分别包含138,854、15,176和10,000个实例。每个样本包含输入文本、目标输出、答案序列以及由篇章索引和查询索引组成的复合标识符,这种多层次的标注体系为模型训练提供了丰富的监督信号。数据集的下载体积约为73.7MB,总存储空间占用达218MB,展现了良好的数据密度与规模平衡。
特点
record数据集最显著的特征在于其精细的标注架构。每个数据点不仅包含基础的输入输出对,还配置了多答案序列支持,这为开发稳健的问答系统创造了条件。索引系统采用双层结构设计,通过passage和query两个维度的坐标定位,实现了样本的精准溯源。数据划分遵循机器学习标准范式,训练集占比超过80%,验证集和测试集的设置则为模型调优和评估提供了可靠基准。特征字段的类型设计兼顾了存储效率与信息完整性,整型和字符串类型的合理搭配反映了专业的数据工程考量。
使用方法
使用record数据集时,研究者可依据标准机器学习流程开展工作。训练集适用于模型参数的初始学习,验证集用于超参数调优和早停判断,测试集则保留至最终评估阶段以保证结果公正性。数据加载可通过HuggingFace库的便捷接口实现,配置文件中预设的路径指向允许直接按分割加载对应数据。处理样本时需注意利用idx结构中的定位信息,这对分析模型在特定篇章或查询上的表现具有重要价值。多答案设计鼓励开发者探索超越单预测输出的评估指标,为构建容错性更强的问答系统提供可能。
背景与挑战
背景概述
RECORD数据集作为问答系统领域的重要基准工具,由华盛顿大学等机构的研究团队于2018年推出,旨在解决复杂阅读理解任务中的指代消解和实体关系推理问题。该数据集通过构建包含138,854个训练样本的大规模问答对,推动了机器对文本深层语义理解的研究。其创新性地采用篇章级答案标注体系,要求模型在长文本中定位分散的证据片段,显著提升了问答系统处理真实场景文本的能力,成为评估模型推理能力的关键基准之一。
当前挑战
RECORD数据集面临的核心挑战体现在语义推理和标注复杂性两个维度。在任务层面,模型需解决跨句指代消解和隐含关系推理难题,要求同时理解局部语境和全局篇章结构;在构建层面,标注者需要处理答案碎片化分布问题,确保多个证据片段都能支持同一答案的标注一致性。数据集中存在的答案多样性现象,即同一问题可能存在多个语义等价但表述不同的正确答案,进一步增加了模型评估的复杂度。
常用场景
经典使用场景
在自然语言处理领域,record数据集因其结构化的问题-答案对设计,成为阅读理解任务的重要基准。研究者通过分析文本段落(inputs)与对应问题(targets)的关联性,评估模型从给定文本中提取准确答案(answers)的能力。该数据集特别适合训练模型处理需要多步推理的复杂问答场景,例如需要结合多个句子信息才能得出正确答案的情况。
实际应用
该数据集的实际价值在智能客服和教育科技领域得到充分体现。企业利用其训练的系统能够准确理解用户提问的深层意图,在教育场景中则可用于开发自动批改系统,评估学生对课文的理解程度。医疗领域也借鉴其数据结构,构建能够从医学文献中快速检索关键信息的辅助诊断工具。
衍生相关工作
基于record数据集的特征设计,后续研究衍生出多种创新方法。BERT和RoBERTa等预训练模型在该数据集上进行了针对性优化,提出了更高效的段落检索策略。同时,该数据集启发了HotpotQA等需要多文档推理的新基准构建,推动了多跳问答研究方向的发展。部分工作还探索了将对话历史纳入输入特征的扩展应用。
以上内容由遇见数据集搜集并总结生成


