CreativeLang/moh_metaphor
收藏Hugging Face2023-06-27 更新2024-03-04 收录
下载链接:
https://hf-mirror.com/datasets/CreativeLang/moh_metaphor
下载链接
链接失效反馈官方服务:
资源简介:
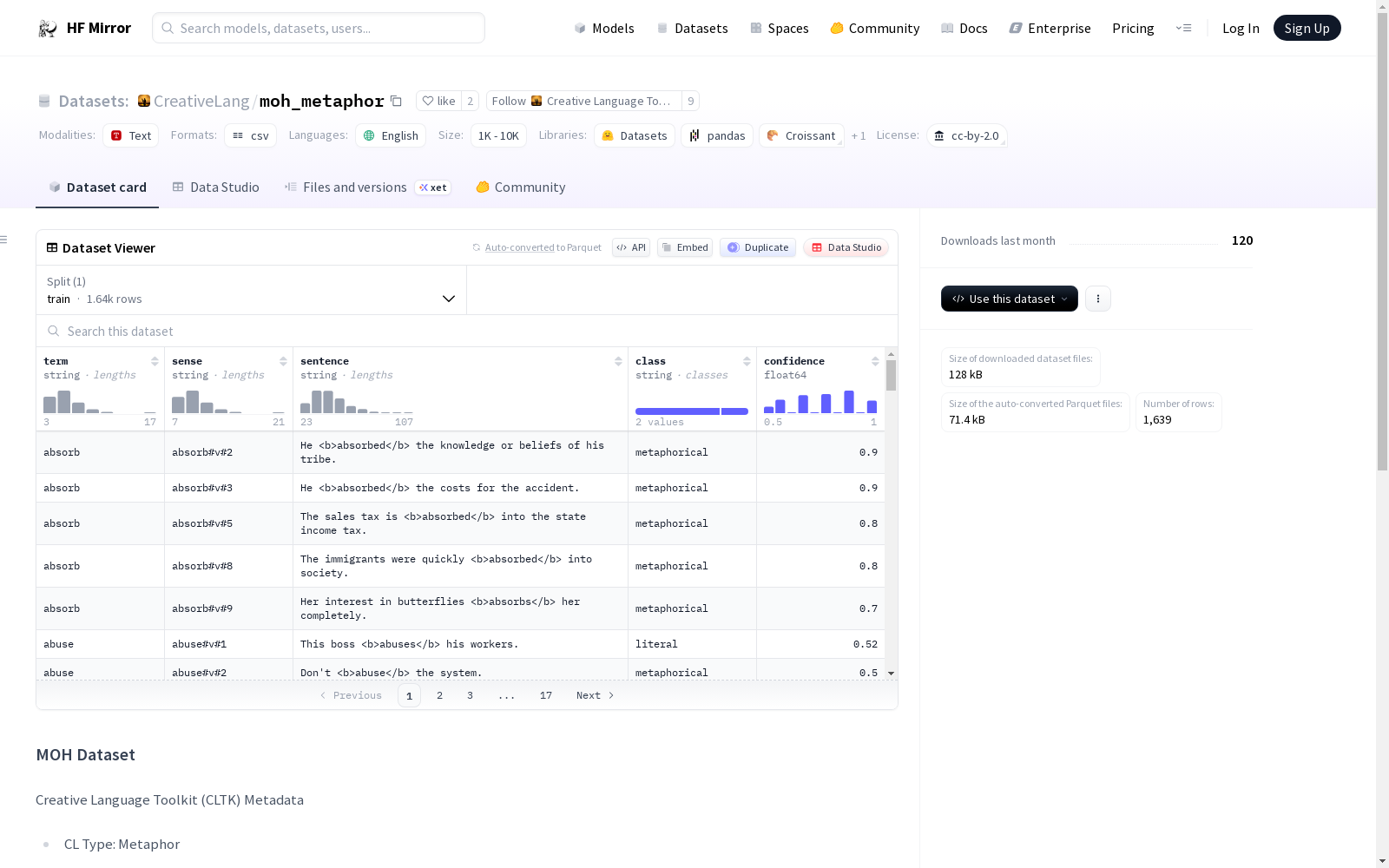
MOH数据集是一个用于隐喻处理的数据集,发布于2016年。该数据集包含1k到2k的数据量,主要用于隐喻的检测和解释。更多详细信息可以参考原始论文。
MOH数据集是一个用于隐喻处理的数据集,发布于2016年。该数据集包含1k到2k的数据量,主要用于隐喻的检测和解释。更多详细信息可以参考原始论文。
提供机构:
CreativeLang
原始信息汇总
MOH Dataset 概述
基本信息
- 许可证: cc-by-2.0
- 语言: 英语
- 数据集大小: 1K<n<10K
数据集详情
- 名称: MOH Dataset
- 用途: 隐喻处理
- 类型: 隐喻
- 任务类型: 检测, 解释
- 大小: 1k~2k
- 创建时间: 2016年
描述
MOH Dataset 是一个用于隐喻处理的专用数据集,该数据集在2016年的论文中发布。详细信息请参阅原始论文。
引用信息
若使用此数据集,请引用以下文献:
@inproceedings{Mohammad2016MetaphorAA, title={Metaphor as a Medium for Emotion: An Empirical Study}, author={Saif M. Mohammad and Ekaterina Shutova and Peter D. Turney}, booktitle={International Workshop on Semantic Evaluation}, year={2016} }
搜集汇总
数据集介绍
构建方式
在隐喻计算研究领域,数据集的构建往往依赖于严谨的标注框架。MOH数据集源自2016年发表的学术论文,其构建过程遵循了实证研究的规范。研究者通过系统性的方法收集了约一千至两千条英文语料,并针对隐喻的检测与解读任务进行了专门标注,旨在探究隐喻作为情感载体的功能,为后续的隐喻自动处理研究奠定了数据基础。
特点
该数据集的核心特点在于其专注于隐喻与情感表达的交叉研究。其规模虽属中小型,但语料经过精心筛选与标注,确保了在隐喻识别与情感分析任务上的针对性与代表性。作为较早公开的隐喻处理资源之一,它为计算语言学领域提供了宝贵的实证数据,支持对语言中复杂修辞现象的计算建模探索。
使用方法
在自然语言处理应用中,该数据集主要用于隐喻检测与情感分析的相关模型训练与评估。使用者可通过HuggingFace平台便捷加载数据,并依据其提供的隐喻及情感标签开展监督学习或作为基准测试集。建议结合原论文以深入理解标注体系,从而更有效地利用该数据集进行隐喻理解或情感计算方面的研究。
背景与挑战
背景概述
隐喻作为语言认知与情感表达的核心机制,在自然语言处理领域长期受到关注。2016年,由Saif M. Mohammad、Ekaterina Shutova和Peter D. Turney等学者构建的MOH数据集应运而生,旨在系统探究隐喻与情感之间的深层关联。该数据集聚焦于隐喻检测与解释任务,通过实证分析揭示了隐喻在传递复杂情绪状态中的媒介作用,为计算语言学与情感分析研究提供了关键数据支撑,推动了隐喻处理从理论探讨向可计算模型的发展。
当前挑战
隐喻处理面临的核心挑战在于其高度依赖语境与文化背景,使得自动检测与解释模型难以准确捕捉隐喻的隐含意义与情感色彩。在数据集构建过程中,研究者需克服隐喻标注的主观性难题,确保标注的一致性与可靠性;同时,隐喻表达的多样性与创造性要求数据覆盖广泛的语义范畴与情感维度,这对数据收集与标注的规模与质量提出了较高要求。
常用场景
经典使用场景
在自然语言处理领域,隐喻处理是理解语言深层语义的关键环节。MOH数据集作为隐喻处理的基准资源,其经典使用场景集中于隐喻检测与解释任务。研究者利用该数据集训练和评估机器学习模型,以自动识别文本中的隐喻表达,并解析其隐含的情感与概念映射。这一过程不仅提升了模型对非字面语言的理解能力,还为后续的语义分析奠定了坚实基础。
衍生相关工作
围绕MOH数据集,学术界衍生了一系列经典研究工作。例如,基于该数据集的隐喻检测模型被进一步优化,应用于跨语言隐喻分析和生成任务。相关研究还探索了隐喻与情感计算的结合,推动了如隐喻情感词典的构建。这些工作不仅深化了对隐喻机制的理论理解,还促进了自然语言处理技术在诗歌分析、广告文案等领域的实际应用。
数据集最近研究
最新研究方向
在自然语言处理领域,隐喻处理作为情感计算与认知语言学交叉的前沿课题,正日益受到关注。CreativeLang/moh_metaphor数据集作为2016年发布的经典资源,为隐喻检测与解释任务提供了关键支持。近年来,该数据集被广泛应用于深度学习模型的研究中,特别是在结合预训练语言模型(如BERT、GPT系列)进行隐喻情感分析方面,推动了隐喻与情绪关联机制的探索。热点事件包括国际语义评估研讨会(SemEval)等竞赛中隐喻相关任务的设立,促进了数据集的复用与模型创新。这些研究不仅深化了语言理解中隐喻的认知计算,还为情感人工智能、内容生成等应用提供了理论基础,具有重要的学术与实用价值。
以上内容由遇见数据集搜集并总结生成


