TruthfulQAPro
收藏TruthfulQAPro 数据集概述
数据集基本信息
- 数据集名称: TruthfulQAPro
- 托管地址: https://huggingface.co/datasets/foadnamjoo/TruthfulQAPro
- 许可证: Apache License 2.0
- 语言: 英语
- 标签: truthfulqa, multiple-choice, evaluation, llm, benchmark
- 数据集展示名: TruthfulQAPro (feature-balanced subsets)
- 数据规模: 1K<n<10K
数据集来源与性质
- 基础数据: 源自 TruthfulQA 的多选行数据,示例与上游相同,仅子集成员资格不同。
- 核心内容: 从 TruthfulQA 衍生的特征平衡参考子集,包含固定大小的二选一切片(300–650 对)、带有验证指标的清单,以及用于精确复现的规范配对ID JSON文件(种子 42)。
- 审计配置文件: surface10 — 十个可解释的词汇/风格特征,采用分组交叉验证。
数据集结构与配置
数据集在 Hugging Face Hub 上定义了独立的配置,每个配置对应一个 CSV 文件模式。
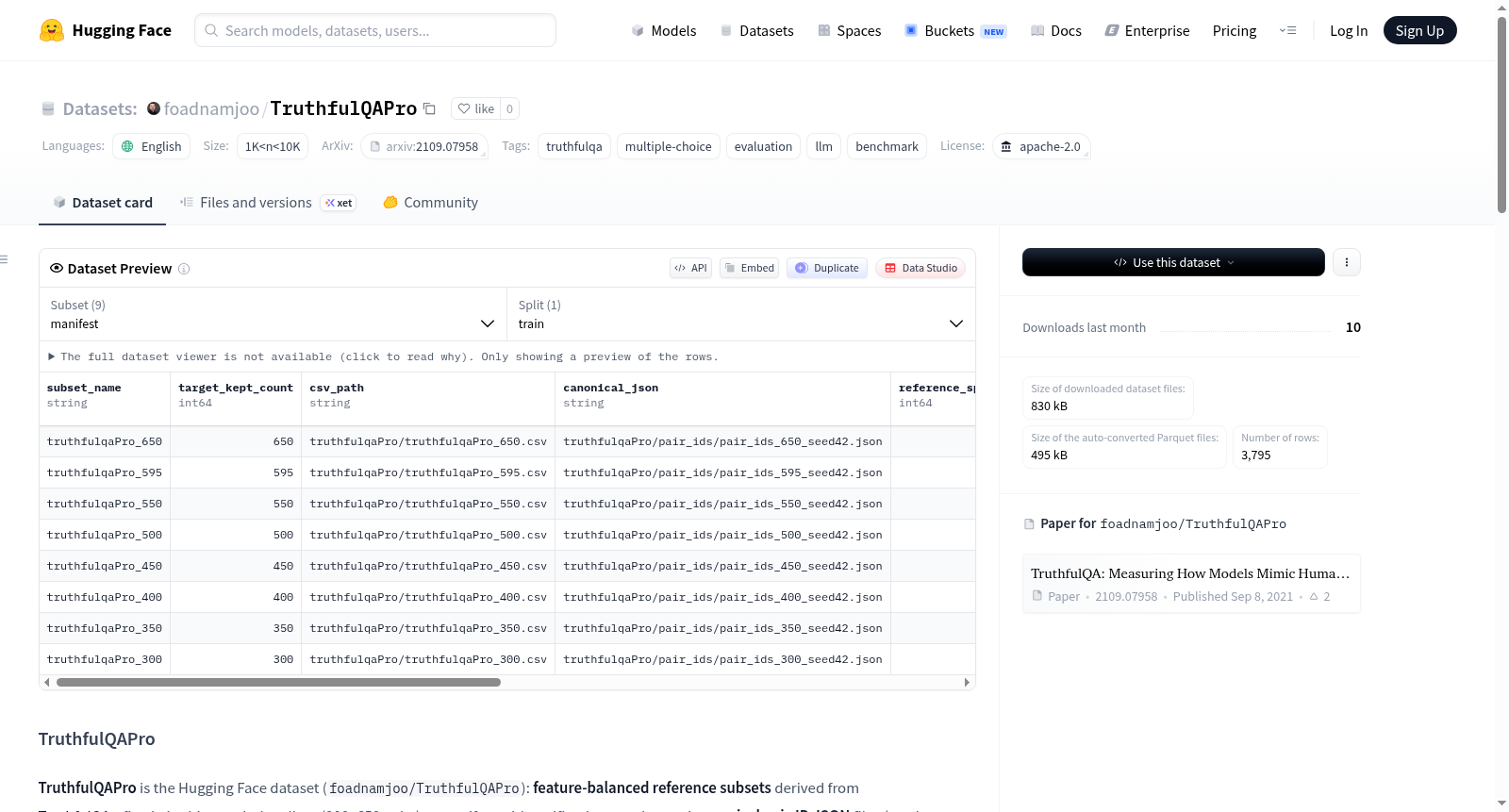
可用配置:
manifest: 对应文件subset_manifest.csv(默认配置)subset_300: 对应文件truthfulqaPro_300.csvsubset_350: 对应文件truthfulqaPro_350.csvsubset_400: 对应文件truthfulqaPro_400.csvsubset_450: 对应文件truthfulqaPro_450.csvsubset_500: 对应文件truthfulqaPro_500.csvsubset_550: 对应文件truthfulqaPro_550.csvsubset_595: 对应文件truthfulqaPro_595.csvsubset_650: 对应文件truthfulqaPro_650.csv
文件说明:
- CSV 文件:
truthfulqaPro_<K>.csv,其中 K ∈ {300, 350, 400, 450, 500, 550, 595, 650}。 - 清单文件:
subset_manifest.csv— 包含 K、路径以及来自锁定摘要的验证均值。 - 配对列表文件:
pair_ids/pair_ids_<K>_seed42.json— 种子 42 的规范配对 ID。
数据子集生成方法
子集通过以下步骤生成:
- 长度四分位数分层洗牌。
- 按否定/长度差距/ID 排序。
- 保留前 K 对(方法名为
feature_balanced_length_stratified_prefix)。
加载方式
使用 datasets 库加载,需指定配置名。
python
from datasets import load_dataset
manifest = load_dataset("foadnamjoo/TruthfulQAPro", "manifest")
ds = load_dataset("foadnamjoo/TruthfulQAPro", "subset_650")
pair_ids/ 目录下的 JSON 文件不属于上述配置,需通过 Hugging Face Hub 的文件浏览器或 huggingface_hub.hf_hub_download 单独下载。
许可证信息
- TruthfulQA(基础问答内容和多选结构)由原作者根据 Apache License 2.0 发布。
- 本版本中的子集选择、清单、配对ID JSON和文档由审计作者根据 MIT License 提供。CSV 文件的再分发仍需遵守 TruthfulQA 的 Apache-2.0 条款。
相关资源
- 代码与协议: https://github.com/foadnamjoo/truthfulqa-audit
- 论文: Judging by the Cover: Auditing Surface-Form Shortcuts in Binary-Choice Truth Benchmarks
- 原始 TruthfulQA 仓库: https://github.com/sylinrl/TruthfulQA
引用
原始 TruthfulQA 基准
bibtex @article{lin2022truthfulqa, title = {Truthful{QA}: Measuring How Models Mimic Human Falsehoods}, author = {Lin, Stephanie and Hilton, Jacob and Evans, Owain}, journal = {arXiv preprint arXiv:2109.07958}, year = {2022} }
本审计/子集工作
bibtex @misc{namjoo2026judging, title = {Judging by the Cover: Auditing Surface-Form Shortcuts in Binary-Choice Truth Benchmarks}, author = {Namjoo, Foad and Phillips, Jeff M.}, year = {2026}, url = {https://github.com/foadnamjoo/truthfulqa-audit}, note = {Manuscript in preparation.} }