ChatterjeeLab/PeptiVerse_data
收藏Hugging Face2026-05-05 更新2026-05-10 收录
下载链接:
https://hf-mirror.com/datasets/ChatterjeeLab/PeptiVerse_data
下载链接
链接失效反馈官方服务:
资源简介:
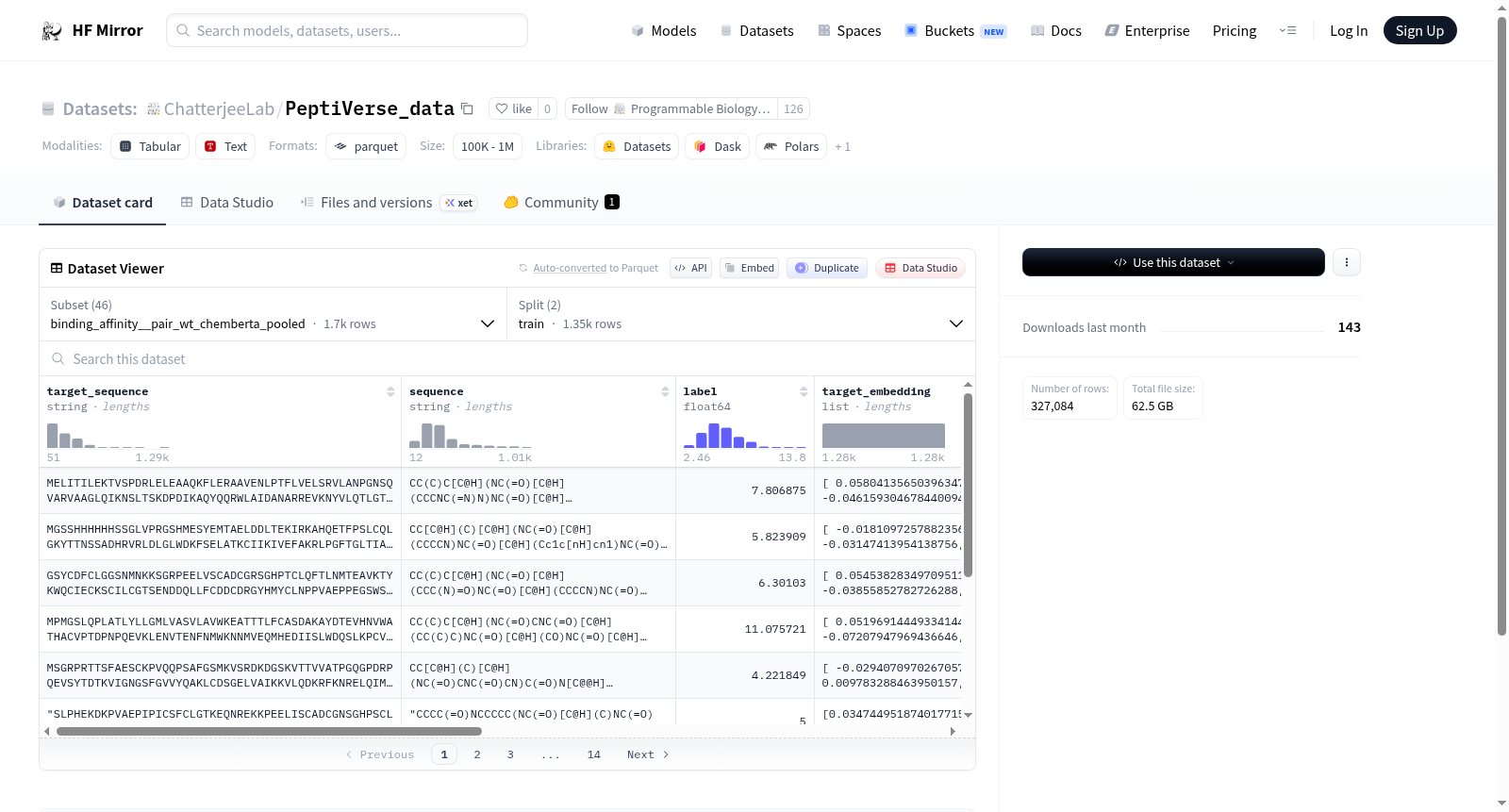
该数据集是一个多任务生物医学数据集,专注于肽和蛋白质相关性质预测。它包含多个子数据集,涵盖结合亲和力、半衰期、溶血性、非折叠性、渗透性(Caco2、PAMPA、渗透性穿透性)、溶解性和毒性等任务。每个子数据集提供序列数据(如目标序列、肽序列、SMILES字符串)和相应的标签(如连续值、分类标签),并集成了从不同预训练模型(包括ChemBERTa、PeptideCLM和WT模型)生成的嵌入特征。数据集分为训练集和验证集,部分配置提供池化(pooled)和未池化(unpooled)的嵌入表示,适用于机器学习模型训练和评估。
This dataset is a multi-task biomedical dataset focused on peptide and protein property prediction. It includes multiple sub-datasets covering tasks such as binding affinity, half-life, hemolysis, non-folding, permeability (Caco2, PAMPA, penetrance), solubility, and toxicity. Each sub-dataset provides sequence data (e.g., target sequences, peptide sequences, SMILES strings) and corresponding labels (e.g., continuous values, categorical labels), and incorporates embedding features generated from different pre-trained models (including ChemBERTa, PeptideCLM, and WT models). The dataset is split into training and validation sets, with some configurations offering both pooled and unpooled embedding representations, suitable for machine learning model training and evaluation.
提供机构:
ChatterjeeLab
搜集汇总
数据集介绍
构建方式
PeptiVerse_data数据集整合了来自多个公开资源的多肽序列及其理化与生物学活性信息,涵盖了结合亲和力、半衰期、溶血性、细胞渗透性、溶解度及毒性等关键指标。在构建过程中,数据集针对每个任务提供了多种特征表示方式,包括基于ChemBERTa、PeptideCLM和ProtBERT等预训练模型提取的序列嵌入,并同时提供池化与非池化两种粒度。该数据集以HuggingFace Datasets格式组织,包含多个子配置,每个配置对应一个特定的预测任务和编码方式,便于开展多任务学习与跨模型比较研究。
使用方法
研究人员可通过HuggingFace Datasets库便捷地加载该数据集,并根据具体任务选择对应的子配置。例如,加载结合亲和力预测的池化版本可使用`load_dataset('bindable/PeptiVerse_data', 'binding_affinity__pair_wt_chemberta_pooled')`。每个配置均预先划分好了训练集与验证集,可以直接用于模型训练与评估。对于需要原始序列及完整嵌入信息的任务,可选用unpooled版本,并利用包含的注意力掩码和长度信息进行动态批处理。该数据集的统一接口设计简化了数据加载流程,使研究者能够将精力集中于模型架构设计与性能优化上。
背景与挑战
背景概述
PeptiVerse_data是一个专注于多肽药物研发的多模态数据集,由研究团队在2023年构建并发布。该数据集涵盖了结合亲和力、半衰期、溶血性、细胞毒性、渗透性、溶解度和毒性等关键药理特性,旨在系统性地推动人工智能在多肽序列设计与活性预测中的应用。通过整合从公开数据库和文献中收集的海量序列-性质配对数据,该数据集为开发更精准的预测模型提供了标准化基准,显著促进了多肽药物发现领域的机器学习研究。
当前挑战
该数据集面临的核心挑战在于多肽药物属性预测的高度复杂性。不同任务如结合亲和力、溶解度和毒性之间存在显著的数据异质性,导致模型泛化困难。此外,实验验证的标注数据稀缺,特别是半衰期和渗透性等难以高通量测定的性质,使得模型训练易受小样本过拟合影响。构建过程中需整合多源异构数据并消除批次效应,同时确保序列表示的统一性和化学修饰的完整性,这给数据清洗与特征工程带来了严峻考验。
常用场景
经典使用场景
PeptiVerse_data数据集融合了多模态肽属性预测任务,涵盖结合亲和力、半衰期、溶血性、细胞渗透性、溶解度及毒性等关键生物物理化学指标。其经典使用场景聚焦于利用预训练语言模型(如ChemBERTa、PeptideCLM)生成的嵌入特征,构建回归或分类模型以精准预测肽段与靶标蛋白间的相互作用强度。通过提供池化与非池化两种特征格式,该数据集支持从全序列级表征到残基级别细粒度建模的灵活切换,为开发高效、鲁棒的肽属性预测框架奠定了坚实基础。
解决学术问题
该数据集系统性地解决了肽类药物研发中多属性同步预测的学术挑战。传统研究常受限于单一属性数据集规模不足且特征表示不统一,难以训练具备泛化能力的通用预测模型。PeptiVerse_data通过整合涵盖结合、稳定性、毒性等多维度的标注数据,并提供统一预处理后的嵌入特征,使得研究者能够探索跨属性任务的知识迁移策略。这为揭示肽序列-结构-功能之间的深层关联提供了关键数据支撑,推动了计算肽学从经验驱动向数据驱动的研究范式转变。
实际应用
在实际应用层面,PeptiVerse_data加速了肽类候选药物的虚拟筛选与优化流程。基于该数据集训练的预测模型可快速评估大量虚拟肽序列的成药性潜力,例如筛选出具有高靶标亲和力、低溶血毒性及优良透膜性的先导化合物。制药企业与生物技术公司可将其嵌入智能药物设计管线,有效降低湿实验验证成本,提升多肽疫苗、抗菌肽及靶向治疗药物的研发效率,尤其在罕见病或复杂疾病靶点的早期探索中展现巨大价值。
数据集最近研究
最新研究方向
PeptiVerse_data数据集聚焦于多肽药物的理化性质与生物活性预测,涵盖结合亲和力、半衰期、溶血性、渗透性及毒性等关键指标。当前前沿研究集中于利用预训练的化学语言模型(如ChemBERTa和PeptideCLM)生成的高维嵌入表示,结合序列与结构信息,构建针对多肽-靶标相互作用的精确预测框架。这一方向与人工智能驱动药物发现的浪潮紧密相连,尤其是在大语言模型用于生物序列分析的背景下,PeptiVerse_data为多肽候选分子的虚拟筛选、设计优化及安全性评估提供了标准化基准,显著推动了基于计算的多肽疗法研发效率与成功率。
以上内容由遇见数据集搜集并总结生成


