openbmb/factnet_relations
收藏Hugging Face2026-05-07 更新2026-03-21 收录
下载链接:
https://hf-mirror.com/datasets/openbmb/factnet_relations
下载链接
链接失效反馈官方服务:
资源简介:
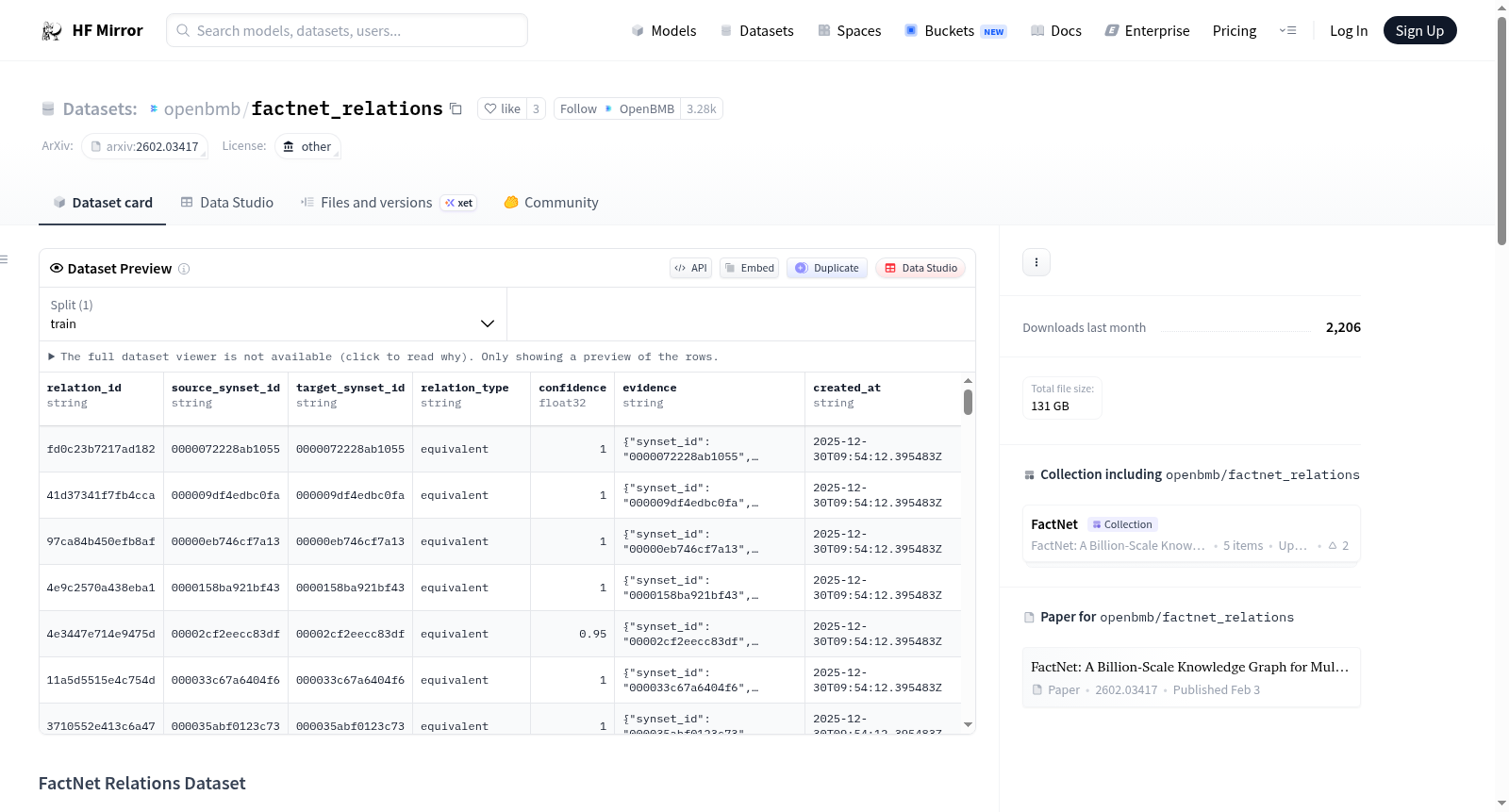
FactNet关系数据集包含FactSynset之间丰富的语义关系,支持高级推理和跨语言事实检索。这些关系捕捉了事实之间的上下位关系、因果关系、时间关系、地理关系以及其他语义连接。数据集格式为parquet文件,包含关系ID、源FactSynset ID、目标FactSynset ID、关系类型、置信度、支持该关系的事实陈述ID、检测方法以及元数据等关键字段。关系类型多样,包括等价关系、上下位关系、因果关系、地理关系、部分关系、成员关系、时间序列、影响关系等。数据集可用于多跳推理、因果和时间推断、地理和空间推理、语义相似性计算以及层次知识导航等高级应用。数据集基于Wikidata和Wikipedia,采用CC BY-SA许可。
The FactNet Relations Dataset contains rich semantic relationships between FactSynsets, enabling advanced reasoning and cross-lingual fact retrieval. These relations capture hypernymy, causality, temporality, geographic relationships, and other semantic connections between facts. The dataset is in parquet format with key fields including relation_id, source_synset_id, target_synset_id, relation_type, confidence, evidence_statement_ids, detection_method, and metadata. Relation types are diverse, covering equivalent, hypernym, causal, geographic, part-whole, membership, temporal sequence, influence, and others. The dataset supports advanced applications like multi-hop reasoning, causal and temporal inference, geographic and spatial reasoning, semantic similarity computation, and hierarchical knowledge navigation. It is derived from Wikidata and Wikipedia and available under the CC BY-SA license.
提供机构:
openbmb
搜集汇总
数据集介绍
构建方式
FactNet Relations数据集基于Wikidata与Wikipedia的海量事实性知识构建,通过挖掘FactSynset之间丰富的语义关联而形成。数据集以parquet文件格式存储,每条关系记录包含唯一标识符、源与目标FactSynset编号、关系类型、置信度分数、支撑该关系的事实陈述标识符、检测方法以及附加的元数据信息。这些关系的识别依赖于多种自动检测手段,从而确保跨语言事实间语义连接的全面覆盖与高质量标注。
使用方法
FactNet Relations数据集适用于多种高级知识推理场景,包括跨事实的多跳推理、因果与时间推断、地理空间推理以及语义相似度计算。用户可依据relation_type字段筛选特定类别的关系,结合source_synset_id与target_synset_id进行图结构化的知识导航。同时,置信度分数(confidence)可作为筛选高可靠关系的重要依据,支撑层次化知识体系的构建与检索增强生成(RAG)系统的开发。
背景与挑战
背景概述
FactNet Relations数据集由清华大学孙茂松教授团队与慕尼黑大学Alexander Fraser教授等多位研究者联合构建,于2026年正式发布,旨在构建一个支持多语言事实推理的大规模知识图谱。该数据集聚焦于事实性知识之间丰富的语义关联,包括上下位、因果、时序、空间及影响关系等,突破了传统知识图谱仅关注实体关系的局限,为多跳因果推理、时空推理及跨语言事实检索等高级认知任务提供了基础支撑。基于Wikidata和Wikipedia的权威语料,FactNet Relations以FactSynset为节点,通过细粒度的关系类型标注,推动了人工智能在事实理解与逻辑推理领域的研究边界。
当前挑战
该数据集所应对的核心挑战在于:现有知识图谱大多以实体为中心,难以表达事实之间的复杂语义关系,如因果链条与跨语言等价关系,限制了机器对深层逻辑的把握。构建过程中面临多重困难:首先,从海量多语言文本中自动检测高置信度关系类型需融合多模态证据,技术复杂度高。其次,关系类别的多样性导致标注协议难以统一,部分细粒度关系(如“influenced_by”)存在主观歧义。此外,跨语言事实的对齐与一致性验证需耗费大量人力与计算资源,如何兼顾规模与质量成为关键瓶颈。
常用场景
经典使用场景
FactNet Relations数据集的核心应用在于构建大规模、多语言的知识推理图谱。其经典的用法是利用跨语言事实同义词集(FactSynsets)之间丰富的语义关系,如上下位、因果、时序和地理包含等,实现多跳推理与事实检索。研究人员常以此数据集为基石,训练模型在异构知识源间进行逻辑链的自动构建与验证,从而提升事实性知识问答、常识推理等任务的准确性与鲁棒性。
解决学术问题
该数据集致力于解决知识图谱中语义关系稀疏性与跨语言对齐困境。传统知识库往往缺乏细粒度的逻辑关系标注,且局限于单一语言,而FactNet Relations通过定义数十种关系类型(如因果、时序、组成等),并融合多语言证据,使得模型能够捕捉事实间的深层关联。这不仅缓解了事实认知中的碎片化问题,还为评估多跳推理能力提供了标准化基准,推动了知识增强型自然语言处理的学术进展。
实际应用
在工业界,FactNet Relations可赋能智能问答系统、搜索引擎和对话机器人。例如,当用户询问“气候变化如何影响农业收成”时,系统能借助因果与时序关系链,从多语言事实中抽取证据并生成解释性回答。此外,该数据集支持地理推理应用,如自动识别“某城市位于哪个国家”的层级逻辑,为地理信息系统与推荐系统提供知识驱动的高效解决方案。
数据集最近研究
最新研究方向
当前,大规模多语言知识图谱的构建与推理成为人工智能领域的前沿热点,FactNet Relations数据集应运而生,专注于捕捉事实间丰富的语义关系,如层级、因果、时间及空间关联等。该数据集不仅为跨语言事实检索和多跳推理提供了坚实基础,还显著增强了模型在复杂场景下的因果推断与空间理解能力。其研究与以维基数据为代表的知识图谱深度融合,推动了层次化知识导航与语义相似度计算的进展,对于构建更可信、可解释的智能系统具有深远影响与重要学术价值。
以上内容由遇见数据集搜集并总结生成


