双语判决语料库(BJC)
收藏arXiv2025-07-01 更新2025-07-04 收录
下载链接:
https://huggingface.co/datasets/xxuan-nlp/CFA_Judgement_Corpus_97-22
下载链接
链接失效反馈官方服务:
资源简介:
TransLaw是一个由香港城市大学开发的用于香港案例法翻译的多智能体框架。该框架包含三个专业智能体:翻译器、批注器和校对器,它们协同工作以生成高质量的翻译。为了评估TransLaw的性能,研究人员创建了双语判决语料库(BJC),这是首个用于法律翻译评估和全面LLM评估的基准数据集。该数据集包含13个开源和商业LLMs作为智能体,用于评估TransLaw在法律语义准确性、结构一致性和文体忠实度方面的表现。
TransLaw is a multi-agent framework developed by City University of Hong Kong for translating Hong Kong case law. This framework encompasses three specialized AI Agents: Translator, Annotator, and Proofreader, which collaborate to produce high-quality translations. To evaluate the performance of TransLaw, researchers constructed the Bilingual Judgment Corpus (BJC) — the first benchmark dataset for both legal translation evaluation and comprehensive large language model (LLM) assessment. This dataset incorporates 13 open-source and commercial LLMs acting as agents to assess TransLaw’s performance across three dimensions: legal semantic accuracy, structural consistency, and stylistic faithfulness.
提供机构:
香港城市大学
创建时间:
2025-07-01
原始信息汇总
数据集概述
基本信息
- 数据集名称: CFA_Judgement_Corpus_97-22
- 许可证: MIT
- 标签: legal
数据集描述
- 领域: 法律
搜集汇总
数据集介绍
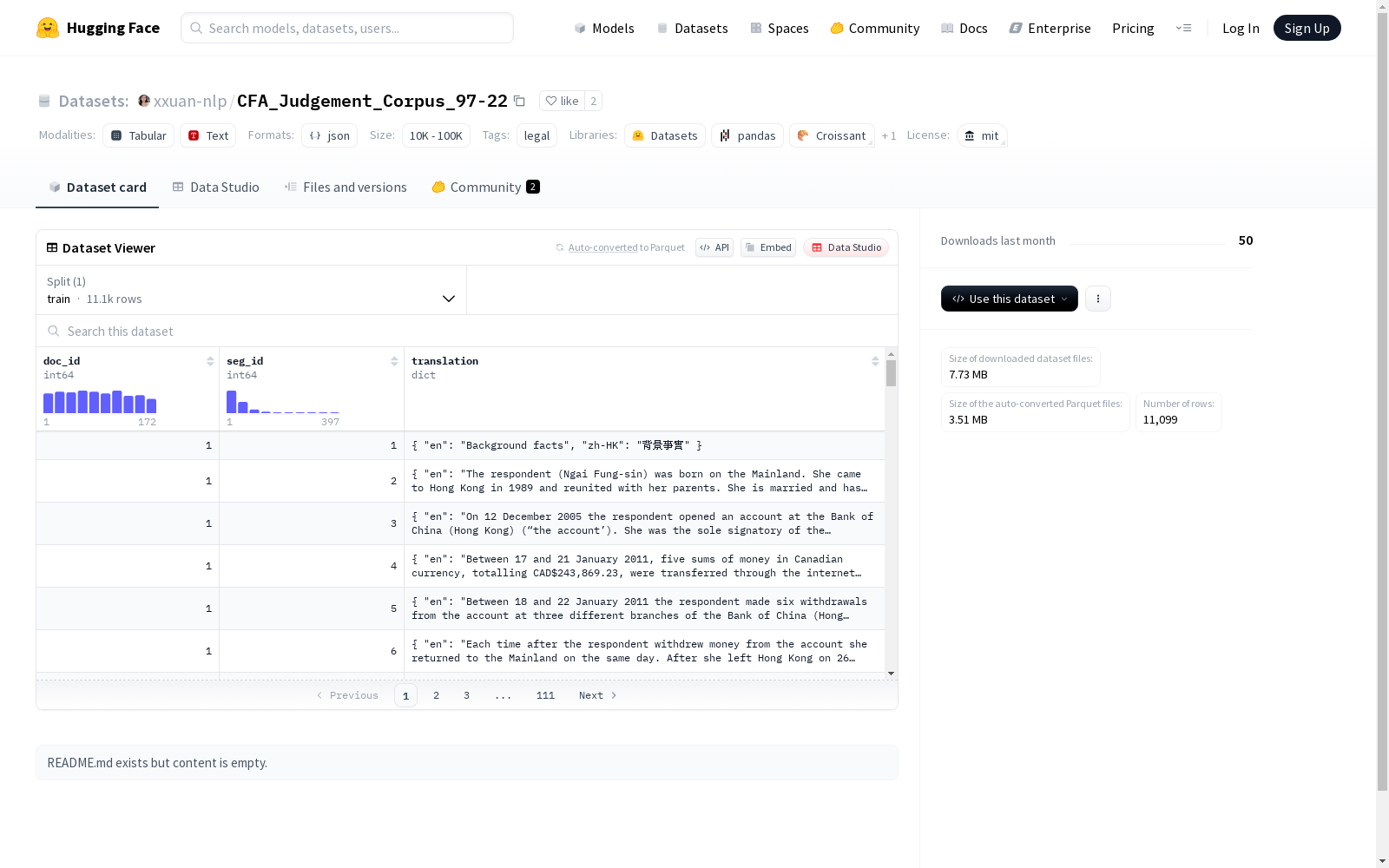
构建方式
双语判决语料库(BJC)的构建基于香港终审法院1997至2022年间的344份中英双语司法判决书,通过专业法律翻译团队进行人工对齐与校对。语料库采用段落级平行文本结构,确保源语言与目标语言在语义和逻辑上的严格对应。构建过程中特别注重法律术语的一致性,并开发了多级翻译错误标注标准(Proofread Codes)来指导质量评估。
特点
该语料库具有鲜明的领域特异性,涵盖香港普通法体系下的专业法律术语、复杂判决逻辑及特定文化语境表达。其独特价值体现在:1) 严格遵循香港双语法律体系的规范性要求;2) 包含28,819.61KB文本量,形成具有统计意义的法律语言资源;3) 采用<原文,参考译文,错误标注>三元组存储模式,支持细粒度翻译质量分析。语料同时保留判决书特有的修辞结构和论证脉络,为法律机器翻译研究提供真实场景下的基准数据。
使用方法
研究者可通过Hugging Face平台获取该语料库,支持两种主要应用模式:1) 作为评估基准,使用xCOMET-XL和wmt22-unite-da等指标量化机器翻译系统的法律语义准确性;2) 作为训练数据,用于微调法律领域专用语言模型。使用时应遵循香港法律文书的保密要求,建议配合TransLaw框架的多智能体协作机制,通过翻译-标注-校对三级流程提升模型输出质量。对于特定研究需求,可灵活选择术语数据库并配置不同规模的LLM代理组合。
背景与挑战
背景概述
双语判决语料库(BJC)由香港城市大学和UOW College Hong Kong的研究团队于2025年创建,旨在解决香港法律判决的翻译问题。该数据集是首个专注于香港法律判决双语翻译的基准数据集,包含344份香港终审法院的双语判决书(1997-2022年),共计28,819.61 KB。BJC的创建背景源于香港回归后法律双语化的需求,特别是在处理复杂法律术语、文化差异和严格语言结构方面的挑战。该数据集对推动法律机器翻译和大型语言模型在法律领域的应用具有重要意义。
当前挑战
BJC数据集面临的挑战主要包括两个方面:领域问题的挑战和构建过程的挑战。在领域问题方面,法律文本的翻译需要极高的准确性和专业性,尤其是在处理复杂法律术语、文化背景差异和法律逻辑结构时。构建过程中的挑战包括:1) 法律术语的标准化和一致性;2) 文化背景和法律逻辑的准确传达;3) 双语文本的对齐和质量控制;4) 数据隐私和版权问题。这些挑战使得法律文本的机器翻译成为一个极具难度的任务,需要多学科的合作和创新技术的应用。
常用场景
经典使用场景
在跨语言法律文本处理领域,双语判决语料库(BJC)作为首个专注于香港判例法的中英平行数据集,为法律机器翻译研究提供了标准化评估基准。其典型应用场景包括训练和评估大语言模型在复杂法律术语翻译、跨文化法律概念转换以及严谨法律文本结构保持等方面的能力,尤其适用于模拟香港双语司法体系中专业法律翻译工作室的工作流程。
衍生相关工作
基于BJC的基准特性,已衍生出多个重要研究方向:包括法律术语知识图谱构建(如LegalTermNet)、法律风格迁移模型(JurisTransfer)以及判决书结构解析算法(LawStruct)。特别值得注意的是,该数据集推动了法律领域多智能体系统的研究热潮,后续工作如JurisAgent和LexiCollaborate均借鉴了其分阶段协同翻译的框架设计。
数据集最近研究
最新研究方向
近年来,双语判决语料库(BJC)在法律机器翻译领域的研究取得了显著进展。特别是在香港法律判决的翻译中,研究者通过引入多智能体系统(如TransLaw框架),显著提升了翻译的准确性、风格适应性和结构连贯性。该框架通过Translator、Annotator和Proofreader三个智能体的协作,模拟了专业法律翻译工作室的工作流程,不仅大幅降低了翻译成本,还在法律语义准确性、结构连贯性和风格适应性方面超越了传统的商业大语言模型(如GPT-4o)。这一研究方向不仅推动了法律翻译技术的进步,还为跨语言法律沟通和多语言法律信息处理提供了新的解决方案。
相关研究论文
- 1TransLaw: Benchmarking Large Language Models in Multi-Agent Simulation of the Collaborative Translation香港城市大学 · 2025年
以上内容由遇见数据集搜集并总结生成


