wdc/products-2017
收藏Hugging Face2022-10-23 更新2024-03-04 收录
下载链接:
https://hf-mirror.com/datasets/wdc/products-2017
下载链接
链接失效反馈官方服务:
资源简介:
许多电商网站已经开始使用schema.org词汇表在其HTML页面中标记产品数据。Web Data Commons项目定期从Common Crawl(一个大型公共网页抓取项目)中提取此类数据。Web Data Commons大规模产品匹配的训练和测试集包含来自不同电商网站的产品对,每个产品对都有一个标签表示是否匹配。为了支持基于机器学习的匹配方法的评估,数据被分为训练集、验证集和测试集。我们提供了四种不同规模的训练和验证集,涵盖四个产品类别。测试集的标签是手动检查的,而训练集的标签是通过共享的Web产品标识符使用弱监督生成的。数据来源于WDC产品数据语料库2.0版本,该语料库包含来自79,000个网站的2600万个产品报价。
Many e-commerce websites have begun to use the schema.org vocabulary to mark up product data in their HTML pages. The Web Data Commons project regularly extracts such data from Common Crawl, a large public web crawling project. The training and test sets for large-scale product matching from Web Data Commons consist of product pairs from different e-commerce websites, with each pair labeled with an indicator of whether the two products are matching. To support the evaluation of machine learning-based matching methods, the dataset is split into training, validation, and test sets. We provide four training and validation sets of varying scales, covering four product categories. The labels for the test set are manually verified, while the labels for the training sets are generated via weak supervision using shared web product identifiers. The data is sourced from the WDC Product Data Corpus Version 2.0, which contains 26 million product offers from 79,000 websites.
提供机构:
wdc
原始信息汇总
数据集概述
数据集名称
- 名称: products-2017
语言
- 语言: 英语 (en-US)
许可证
- 许可证: 未知
多语言性
- 多语言性: 单语种
大小分类
- 大小分类: 1K<n<10K, 10K<n<100K
数据来源
- 数据来源: 原始数据
任务类别
- 任务类别: 文本分类, 数据集成
任务ID
- 任务ID: 实体匹配, 身份解析, 产品匹配
论文代码ID
- 论文代码ID: wdc-products
数据集描述
数据集总结
- 数据集总结: 包含从多个电商网站提取的产品数据,以schema.org词汇标记。数据集提供不同大小的训练和验证集,用于支持机器学习方法的产品匹配评估。
支持的任务和排行榜
- 支持的任务: 实体匹配, 产品匹配
数据集结构
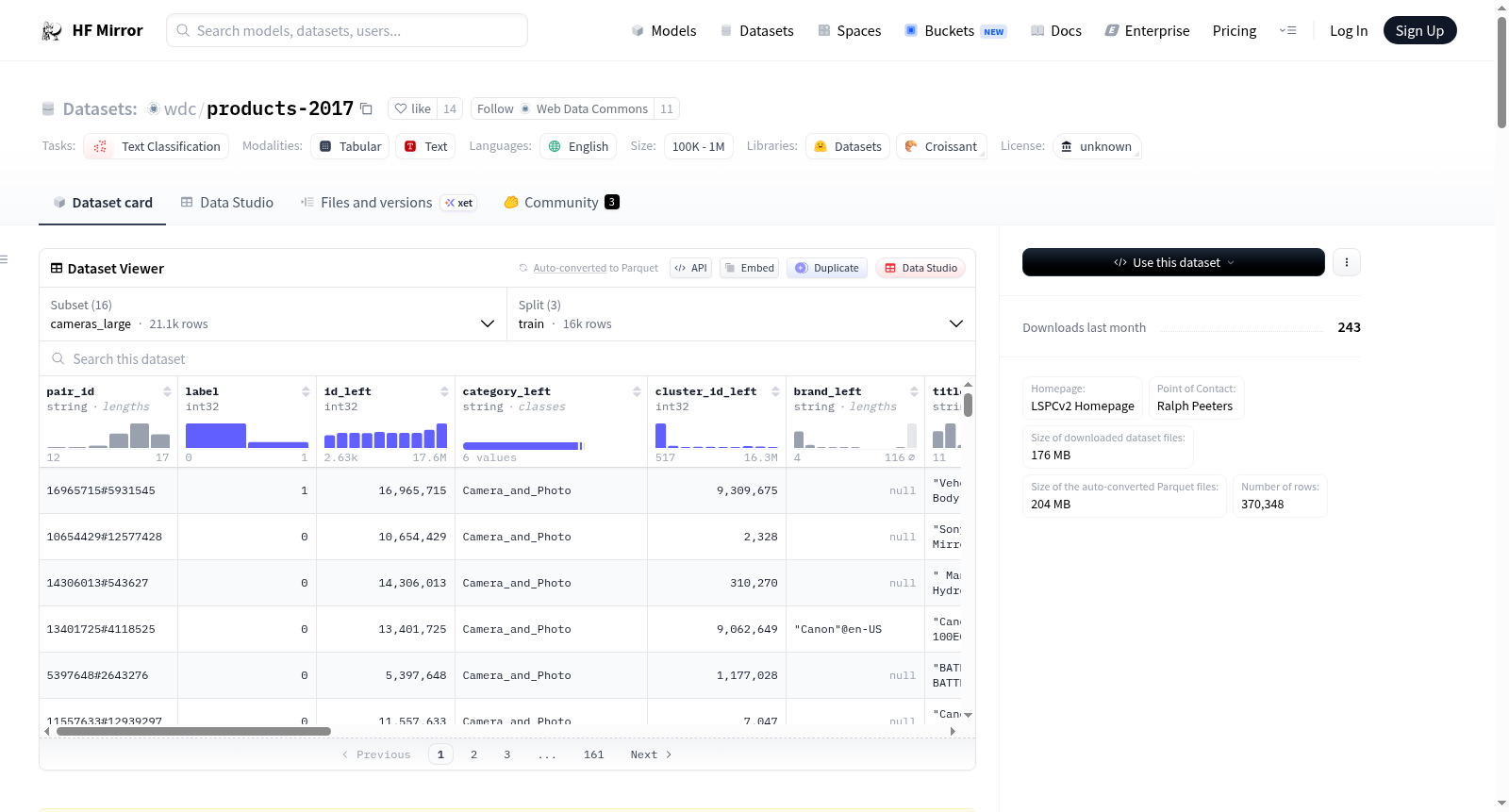
数据实例
- 数据实例: 数据以产品对的形式组织,每个实例包含一对产品及其匹配/非匹配标签。
数据字段
- 数据字段:
- pair_id: 产品对唯一标识符
- label: 匹配/非匹配标签
- id: 产品唯一ID
- category: 产品类别
- cluster_id: 产品集群ID
- brand: 品牌
- title: 产品标题
- description: 产品描述
- price: 产品价格
- specTableContent: 产品规格表内容
数据分割
- 数据分割: 针对不同产品类别(计算机、相机、手表、鞋子)提供不同大小的训练和验证集。
数据集创建
注释
- 注释过程:
- 训练和验证集: 通过共享的schema.org产品ID进行远监督
- 测试集: 由单个专家注释者进行注释
注释者
- 注释者: Ralph Peeters
搜集汇总
数据集介绍
构建方式
在电子商务领域,产品匹配是数据集成中的核心挑战。该数据集源自Web Data Commons项目,通过从Common Crawl大规模网页爬取中提取schema.org标记的产品数据构建而成。其训练集与验证集采用弱监督方法,利用共享的产品标识符自动生成标签;而测试集则经过专家手动标注,确保了评估的可靠性。数据涵盖计算机、相机、手表和鞋类四大产品类别,每个类别均提供不同规模的数据划分,以适应多样化的机器学习模型训练需求。
使用方法
该数据集专为实体匹配和产品匹配任务设计,适用于机器学习模型的训练与评估。用户可根据需求选择不同产品类别和规模的数据划分,例如从小型到超大型训练集,以平衡计算资源与模型性能。数据以JSON格式提供,每对产品包含唯一的配对标识符和二元匹配标签,便于直接用于分类或相似度计算任务。研究人员可利用其丰富的属性字段,如产品描述和规格表内容,开发先进的匹配算法,并通过标准化的测试集进行性能比较,推动电子商务数据集成技术的发展。
背景与挑战
背景概述
在电子商务蓬勃发展的时代,海量异构产品数据的整合与匹配成为信息检索与数据融合领域的核心难题。为应对这一挑战,曼海姆大学Web数据共享项目于2019年推出了WDC/products-2017数据集,由Ralph Peeters、Anna Primpeli和Christian Bizer等研究人员主导构建。该数据集旨在为大规模产品匹配任务提供标准化评估基准,其数据源自对Common Crawl网络爬虫中schema.org结构化标记的自动化提取,涵盖了计算机、相机、手表和鞋类四大品类。通过提供不同规模的训练、验证与测试集,该数据集有效推动了实体解析与产品对齐算法的研究,为电子商务数据集成领域奠定了重要的实证基础。
当前挑战
该数据集致力于解决大规模产品匹配这一复杂任务,其核心挑战在于如何精准识别来自不同电商网站、描述方式各异的同一产品实体。具体而言,挑战体现在两方面:在领域问题层面,产品标题、描述和规格信息常存在文本异构、缩写多样、关键属性缺失或噪声干扰,要求模型具备深层次的语义理解与抗噪能力;在构建过程层面,训练集依赖基于共享产品标识符的远程监督自动标注,可能引入标签噪声,而测试集虽经专家手动校验,但规模有限,且单一标注者可能带来主观偏差,如何平衡标注质量与规模成为关键制约。
常用场景
经典使用场景
在电子商务领域,产品匹配是数据集成与实体解析的核心任务。wdc/products-2017数据集通过提供来自不同在线商店的产品对,为大规模产品匹配研究提供了标准化的评估基准。该数据集以二进制产品对形式呈现,涵盖计算机、相机、手表和鞋类等四个类别,每个类别均包含训练集、验证集和测试集,支持机器学习模型在不同数据规模下的性能验证。其经典使用场景在于训练和评估实体匹配算法,帮助研究者探索如何准确识别来自异构来源的同一产品实体,从而推动数据集成技术的发展。
解决学术问题
该数据集有效解决了大规模产品匹配中数据稀疏性、异构性以及标注成本高昂等学术难题。通过利用schema.org标记从公共网络爬取数据,并结合弱监督与专家标注,数据集提供了高质量的训练与测试样本。这使研究者能够深入探究实体解析中的特征表示、相似度计算和分类模型优化等问题,为跨源产品数据对齐提供了可靠的研究基础。其意义在于建立了可重复的实验标准,促进了机器学习在数据集成领域的理论进展与实际应用。
实际应用
在实际应用中,wdc/products-2017数据集为电子商务平台、价格比较网站以及供应链管理系统提供了关键技术支持。基于该数据集训练的匹配模型能够自动识别不同商家列表中的同一产品,从而实现价格监控、库存管理和产品推荐等功能。例如,在零售数据分析中,系统可借助此类模型整合多源产品信息,提升数据一致性,优化用户体验。此外,该数据集还可用于构建智能购物助手,帮助消费者快速比对产品规格与价格,推动商业智能的精细化发展。
数据集最近研究
最新研究方向
在电子商务数据集成领域,大规模产品匹配技术正经历着深刻的变革。随着schema.org标记在网页中的广泛应用,从海量网络爬取数据中精准识别同一产品实体成为研究焦点。当前前沿探索集中于利用弱监督学习与深度语义表征相结合的方法,以应对产品描述文本的异构性和噪声挑战。研究者们致力于开发跨领域自适应模型,提升计算机、相机、手表和鞋类等多品类下的匹配鲁棒性。该数据集通过提供人工校验的测试集与多规模训练集,为评估基于Transformer的预训练语言模型在实体解析任务中的泛化能力奠定了基准。相关进展不仅推动了知识图谱构建与供应链管理的智能化,也为跨平台价格监控和虚假产品检测等实际应用提供了关键技术支撑。
以上内容由遇见数据集搜集并总结生成


