ruri-v3-dataset-reranker
收藏Hugging Face2025-04-15 更新2025-04-15 收录
下载链接:
https://huggingface.co/datasets/cl-nagoya/ruri-v3-dataset-reranker
下载链接
链接失效反馈官方服务:
资源简介:
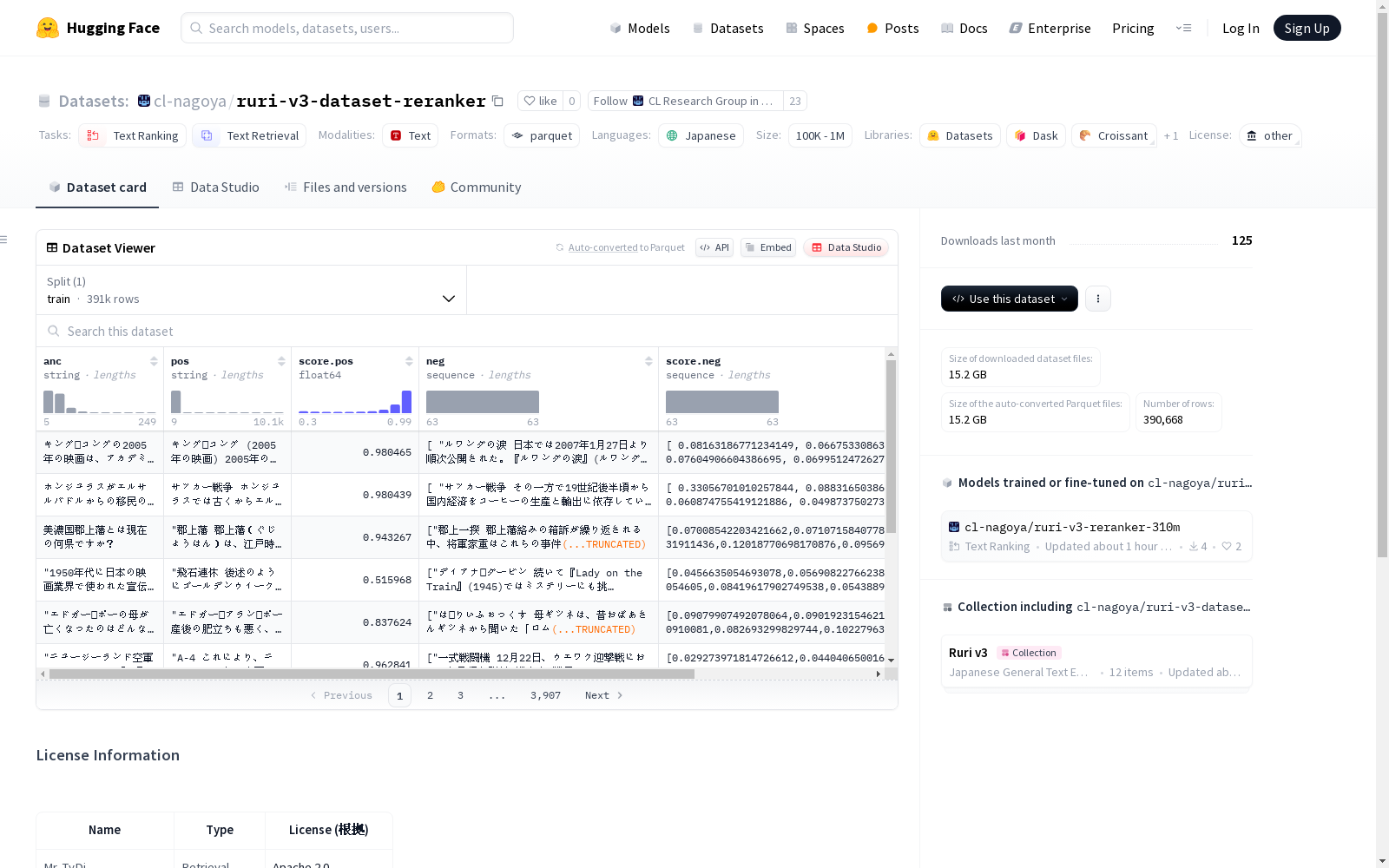
这是一个用于文本排名和文本检索任务的数据集,包含anc, pos, neg等字段,分为训练集,共有390848个样本。数据集使用的语言为日语。
创建时间:
2025-04-06
搜集汇总
数据集介绍
构建方式
在信息检索与文本排序领域,ruri-v3-dataset-reranker数据集通过整合多个权威开源数据集构建而成,包括Mr. TyDi、MIRACL、Auto Wiki QA Nemotron等,涵盖问答与检索任务。数据集采用严格的许可协议合规性审查,确保数据来源合法,每条样本包含锚文本(anc)、正例(pos)及其得分(score.pos)、负例列表(neg)及其得分序列(score.neg),以及数据来源标识(source),形成结构化三元组对比格式。
特点
该数据集以日语文本为核心,包含39万条训练样本,其显著特点在于采用多维度评分机制,正负例均附带精细化浮点分数,支持细粒度排序模型训练。数据覆盖问答、检索双场景,负例以序列形式呈现,模拟真实检索中的候选集分布。各字段采用字符串与数值混合编码,既保留原始文本语义信息,又提供可量化的排序依据,适用于跨语言迁移学习研究。
使用方法
使用者可通过HuggingFace平台直接加载数据集,默认配置包含单一训练分割。建议结合文本排序任务框架,利用anc-pos-neg三元组结构进行对比学习,或通过score.pos与score.neg序列实现列表级排序优化。数据来源字段可用于领域适应性训练,需注意遵守原始数据集的CC-BY-SA、Apache 2.0等许可协议,商业用途前应核查各子集的二次授权要求。
背景与挑战
背景概述
ruri-v3-dataset-reranker数据集是专注于日语文本排序与检索任务的专业语料库,由多个知名开源数据集整合构建而成。该数据集融合了Mr. TyDi、MIRACL等跨语言检索数据,以及Auto Wiki QA Nemotron、JSQuAD等日文问答数据,体现了多任务学习的学术思想。其核心研究问题聚焦于提升日语文本相关性排序模型的性能,特别是在处理复杂语义匹配和跨领域迁移场景下的表现。数据集的构建采用了锚文本-正例-负例的三元组结构,为深度学习模型提供了丰富的对比学习信号,对推动日语信息检索领域的发展具有重要意义。
当前挑战
该数据集面临的领域挑战主要来自日语特有的语言复杂性,包括汉字假名混写体系、丰富的敬语表达以及高度依赖上下文语义的特性,这些因素对文本相关性判断提出了更高要求。在构建过程中,技术挑战体现在多源数据整合方面:需要协调不同许可证(如Apache 2.0与CC-BY-SA)的数据使用规范,统一Mr. TyDi等英语导向数据集与日文本土数据的标注标准,以及处理问答数据与检索任务之间的格式转换问题。负采样策略的设计也需谨慎,以避免在跨领域数据中引入语义偏差。
常用场景
经典使用场景
在信息检索和自然语言处理领域,ruri-v3-dataset-reranker数据集以其独特的结构设计,为文本排序和重排任务提供了丰富的训练资源。该数据集通过包含锚文本、正例、负例及其相关评分,使得模型能够学习到更精细的文本相关性判断能力。特别是在多语言环境下,该数据集对日语文本的支持,为跨语言信息检索研究提供了重要数据基础。
实际应用
在实际应用中,ruri-v3-dataset-reranker数据集被广泛用于构建高效的搜索引擎和问答系统。例如,在电子商务平台中,利用该数据集训练的模型可以更准确地匹配用户查询与商品描述,提升用户体验。此外,该数据集还支持多语言检索,为全球化企业的多语言服务提供了技术保障。其高质量的数据标注使得模型在实际场景中表现出色。
衍生相关工作
基于ruri-v3-dataset-reranker数据集,研究者们开发了多种先进的文本排序和重排模型。例如,一些工作利用该数据集训练了跨语言检索模型,显著提升了多语言环境下的检索性能。此外,该数据集还被用于改进问答系统中的答案排序模块,使得系统能够更精准地返回相关答案。这些衍生工作进一步拓展了数据集的应用范围。
以上内容由遇见数据集搜集并总结生成


