take_the_banana_and_insert_into_the_bottle
收藏Hugging Face2025-09-09 更新2025-09-10 收录
下载链接:
https://huggingface.co/datasets/weleen/take_the_banana_and_insert_into_the_bottle
下载链接
链接失效反馈官方服务:
资源简介:
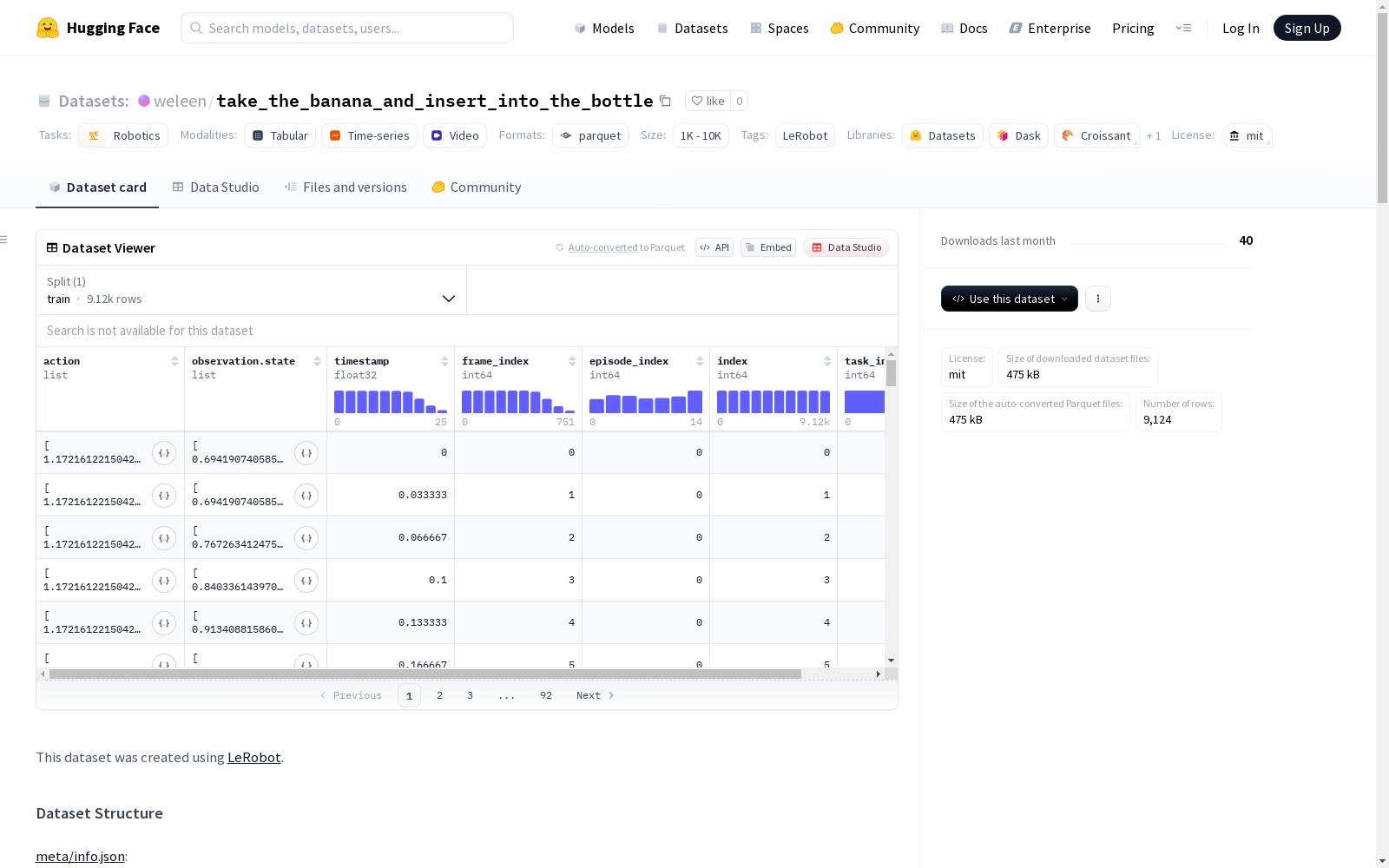
这是一个使用LeRobot创建的数据集,包含15个剧集,共9124帧,1个任务,30个视频。数据集分为训练集。数据集特征包括动作的位置信息、观察状态、 gripper的图像和静态图像等。所有视频的编码为av1,格式为yuv420p,没有音频,帧率为30。
创建时间:
2025-08-31
原始信息汇总
数据集概述
基本信息
- 许可证: MIT
- 任务类别: 机器人学
- 标签: LeRobot
数据集结构
- 配置名称: default
- 数据文件: data//.parquet
数据集详情
- 代码库版本: v2.1
- 机器人类型: so101_follower
- 总情节数: 15
- 总帧数: 9124
- 总任务数: 1
- 总视频数: 30
- 总块数: 1
- 块大小: 1000
- 帧率: 30 fps
- 分割: 训练集 (0:15)
数据路径
- 数据路径: data/chunk-{episode_chunk:03d}/episode_{episode_index:06d}.parquet
- 视频路径: videos/chunk-{episode_chunk:03d}/{video_key}/episode_{episode_index:06d}.mp4
特征
- action: float32, 形状 [6], 名称: shoulder_pan.pos, shoulder_lift.pos, elbow_flex.pos, wrist_flex.pos, wrist_roll.pos, gripper.pos
- observation.state: float32, 形状 [6], 名称: shoulder_pan.pos, shoulder_lift.pos, elbow_flex.pos, wrist_flex.pos, wrist_roll.pos, gripper.pos
- observation.images.gripper: video, 形状 [480, 640, 3], 名称: height, width, channels, 信息: 视频高度480, 视频宽度640, 视频编解码器av1, 视频像素格式yuv420p, 视频非深度图, 视频帧率30, 视频通道数3, 无音频
- observation.images.static: video, 形状 [480, 640, 3], 名称: height, width, channels, 信息: 视频高度480, 视频宽度640, 视频编解码器av1, 视频像素格式yuv420p, 视频非深度图, 视频帧率30, 视频通道数3, 无音频
- timestamp: float32, 形状 [1], 名称: 无
- frame_index: int64, 形状 [1], 名称: 无
- episode_index: int64, 形状 [1], 名称: 无
- index: int64, 形状 [1], 名称: 无
- task_index: int64, 形状 [1], 名称: 无
搜集汇总
数据集介绍
构建方式
在机器人操作任务数据采集领域,该数据集依托LeRobot框架构建,采用SO101型机器人执行单一任务场景下的连续动作序列。数据采集过程涵盖15个完整情节,生成9124帧多模态记录,以30fps的采样率同步保存关节状态、夹爪图像及静态视角视频,所有数据以标准化Parquet格式分块存储,确保时序一致性与高效存取。
特点
该数据集的核心特征体现在其多维度的传感器融合架构,包含六维关节角度动作向量、等维度状态观测值,以及双视角视觉数据——480×640分辨率的夹爪摄像头与静态环境视频流。所有数据均附带精确的时间戳与帧索引,支持端到端的模仿学习与强化学习研究,其结构化元数据体系为机器人技能泛化提供了丰富的时空上下文信息。
使用方法
研究者可通过HuggingFace数据加载工具直接访问该数据集,按情节索引解析Parquet文件获取动作-观测对。视觉数据以AV1编码视频流形式存储,需配合帧提取工具使用;状态与动作数据可直接用于策略网络训练。数据集默认划分为训练集,支持跨模态对齐、行为克隆及离线强化学习等典型机器人学习范式。
背景与挑战
背景概述
机器人操作任务数据集take_the_banana_and_insert_into_the_bottle由LeRobot研究团队基于MIT许可证构建,专注于机械臂精细操作领域。该数据集通过SO101型跟随机器人采集了15个完整操作序列,共计9124帧多模态数据,包含关节状态、夹爪视觉及静态环境观测信息。其核心研究在于解决机器人对非结构化环境中物体的精准抓取与放置问题,为模仿学习与强化学习算法提供了真实世界的训练基准,推动了具身智能在复杂操作任务中的发展。
当前挑战
该数据集致力于解决机器人精细操作中视觉-动作协同映射的挑战,特别是动态环境下物体的精准抓取与容器内放置的位姿控制问题。构建过程中需克服多模态数据同步采集的技术难点,包括机械臂关节状态与双视角视觉传感器的高频时序对齐,以及操作轨迹在连续动作空间中的噪声抑制。此外,真实物理场景中光照变化、物体形变等不确定因素增加了数据一致性与泛化能力保障的复杂度。
常用场景
经典使用场景
在机器人操作学习领域,该数据集通过记录机械臂执行香蕉插入瓶子的精细操作过程,为模仿学习算法提供了高质量的示范数据。其多模态特性结合了关节状态、视觉观测和时间戳信息,能够有效支持端到端策略网络的训练与验证,成为机器人技能习得研究的基准测试平台。
衍生相关工作
该数据集催生了多项机器人学习领域的创新研究,包括基于Transformer的动作预测模型、多视角视觉特征融合方法以及示范数据增强技术。这些工作显著提升了机器人操作技能的泛化能力,为后续大规模机器人操作数据集的构建建立了重要范式。
数据集最近研究
最新研究方向
在机器人操作任务领域,该数据集聚焦于具身智能的物理交互学习,其多模态特征结构为模仿学习与强化学习算法提供了重要支撑。当前研究热点集中于视觉-动作联合建模,通过抓取器视角与静态视角的双路视频流,探索跨模态表征在精细操作任务中的迁移机制。随着端到端决策范式的兴起,该数据集在行为克隆、视觉运动控制等方向展现出显著潜力,为机器人泛化能力与场景适应性研究提供了高质量基准。
以上内容由遇见数据集搜集并总结生成


