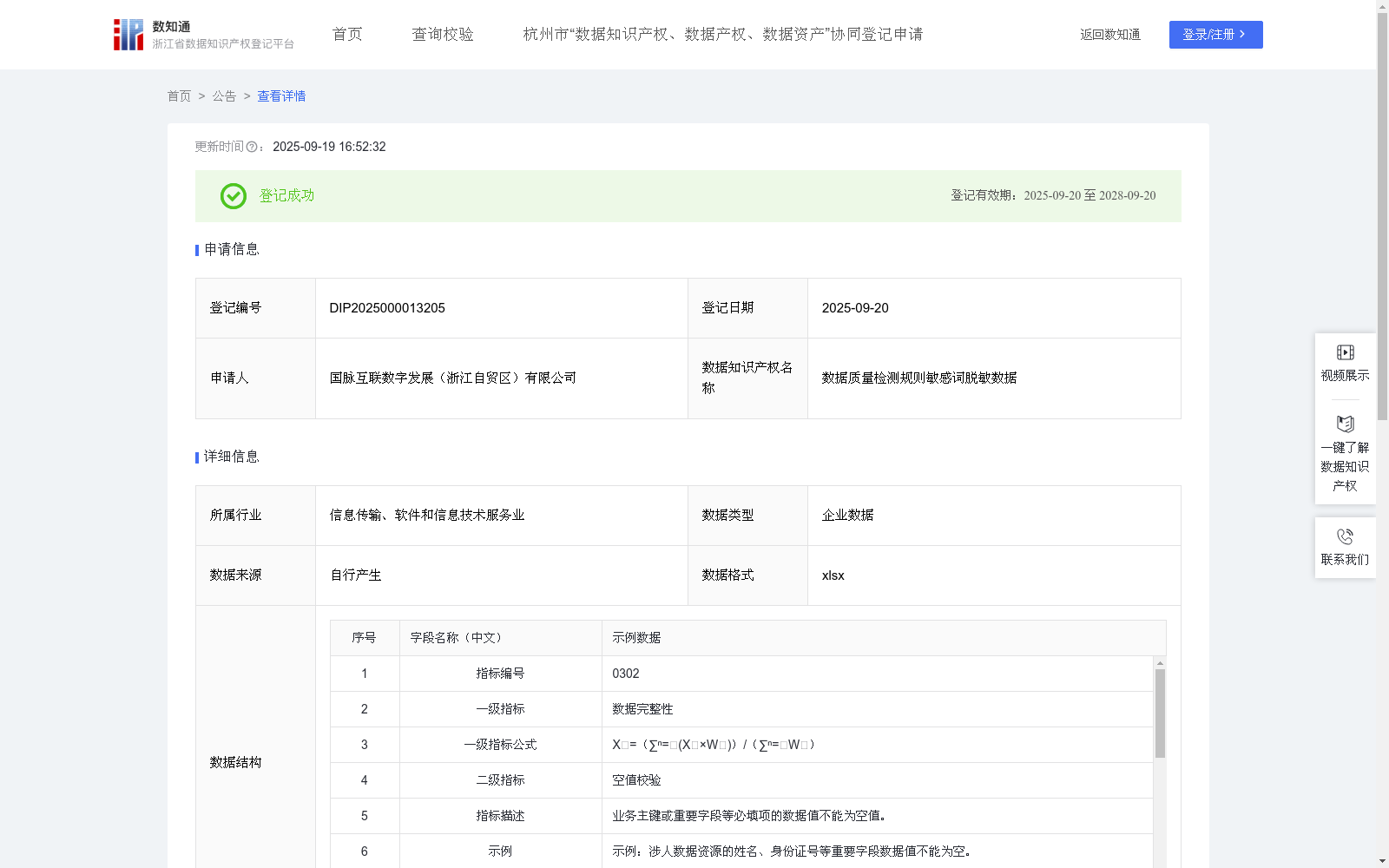
数据质量检测规则敏感词脱敏数据
收藏浙江省数据知识产权登记平台2025-09-19 更新2025-09-20 收录
下载链接:
https://www.zjip.org.cn/home/announce/trends/183276
下载链接
链接失效反馈官方服务:
资源简介:
一、适用条件与范围:在企业、政府机构、数据平台需要对组织本身的数据进行数据质检时,需要查看并参考数据质量检测规则,且必须严格保护原始数据主体。
二、适用对象:企业、政府机构、数据平台等有数据质量提升需求的数据提供方或数据使用方。
三、核心价值
1.规则安全共享
对数据质量检测规则中的敏感内容(评分标准、检测规则系统操作地址)进行脱敏,确保原始数据隐私合规,同时保留规则的逻辑有效性。有效解决了数据可用性与安全性之间的矛盾。
2.六大维度深度评估
完整性:检测空值率、必填字段缺失及关联数据链断裂
唯一性:识别主键/业务键重复、索引冲突
及时性:监控数据延迟、生命周期时效异常
准确性:验证数值偏差、逻辑矛盾(如出生日期>当前日期)
一致性:校验跨表关联一致性、指标口径冲突
有效性:校验值域合规、格式规范
四、解决核心痛点
1.安全协同障碍:打破因敏感规则无法共享导致的数据质量检测壁垒
2.治理效率提升:通过数据质量检测规则数据,可高效完成百万级数据六大维度的质量诊断。
五、外部复用价值
脱敏规则可集成至数据中台、交换平台或第三方审计系统,为生态伙伴提供标准化、可验证的质量评估服务体系。一、数据采集:
通过公司内部数据质控合规系统,采集包含指标编号、一级指标、二级指标、指标描述、示例、评分方式、评分标准、适用规则名称、检测方式、规则说明、检测规则系统操作地址、公式取值、计算公式、二级指标得分、敏感数据类型、脱敏后数据集等字段的原始数据质量检测规则数据集。
二、数据处理:
构建敏感词库:依据预设规则,建立敏感词库。
敏感词分类:根据原始数据字段特性,将敏感词库词语分类为评分标准类、规则说明类、检测规则系统操作地址类、公式取值类、计算公式类等敏感数据类型,明确每个词语所属类别。
三、核心算法规则:
(1)敏感数据识别:将原始数据集导入敏感数据识别模型。模型基于KNN算法,将数据内容与敏感词库进行检索比对。当识别到内容属于预设的敏感数据类型(评分标准、规则说明、检测规则系统操作地址、公式取值或计算公式)时,即标记为敏感数据。
(2)敏感数据脱敏:对标记的敏感数据实施脱敏处理:
检测规则系统操作地址类 (IP:Port):替换具体数字段为掩码 (如http://172.**.***.***:****/...)。
评分标准类、规则说明类、公式取值类、计算公式类:根据安全策略进行内容遮蔽或泛化处理(如遮蔽具体数值、阈值或逻辑细节),确保核心规则逻辑结构保留但敏感细节不可见。
脱敏结果记录在脱敏后数据集字段,同时标记对应的敏感数据类型。
(3)模型迭代:将新识别的敏感数据及其脱敏结果持续加入训练集,优化敏感数据识别模型的精度。
四、真实数据示例
例:原检测规则系统操作地址为http://172.16.102.117:5600/#/main/common/rule,包含了检测规则的具体系统操作地址,一旦泄露会造成公司资源流失,通过敏感数据识别模型对检测规则系统操作地址类信息进行标记并脱敏,脱敏后附件地址为http://172.**.***.***:****/#/main/common/rule
1. Applicable Conditions and Scope: When enterprises, government agencies, and data platforms need to conduct data quality inspection on their own organizational data, they must view and refer to data quality inspection rules, and strictly protect the privacy of original data subjects.
2. Applicable Objects: Data providers or data users with data quality improvement needs, such as enterprises, government agencies, and data platforms.
3. Core Values
3.1 Secure Sharing of Rules: Desensitize sensitive content in data quality inspection rules (including scoring standards and operating addresses of detection rule systems) to ensure compliance with original data privacy regulations while retaining the logical validity of the rules. This effectively resolves the contradiction between data availability and security.
3.2 In-Depth Assessment across Six Dimensions
- Completeness: Detect null value rates, missing required fields, and broken associated data chains
- Uniqueness: Identify duplicate primary keys/business keys and index conflicts
- Timeliness: Monitor data delays and abnormal lifecycle timeliness
- Accuracy: Verify numerical deviations and logical contradictions (e.g., birth date > current date)
- Consistency: Check cross-table association consistency and indicator caliber conflicts
- Validity: Check domain value compliance and format specifications
4. Core Pain Points Solved
4.1 Barriers to Secure Collaboration: Break through data quality inspection barriers caused by the inability to share sensitive rules
4.2 Improved Governance Efficiency: With data quality inspection rule data, efficient quality diagnosis of millions of records across the six dimensions can be completed.
5. External Reuse Value: The desensitized rules can be integrated into data middle platforms, exchange platforms, or third-party audit systems, providing standardized and verifiable quality assessment service systems for ecological partners.
6. Data Collection: Collect the original data quality inspection rule dataset containing fields such as indicator ID, first-level indicator, second-level indicator, indicator description, examples, scoring method, scoring standards, applicable rule name, detection method, rule description, operating address of detection rule system, formula value, calculation formula, second-level indicator score, sensitive data type, and desensitized dataset through the company's internal data quality control compliance system.
7. Data Processing:
7.1 Build Sensitive Word Bank: Establish a sensitive word bank according to preset rules.
7.2 Sensitive Word Classification: According to the characteristics of original data fields, classify words in the sensitive word bank into sensitive data types such as scoring standard type, rule description type, detection rule system operating address type, formula value type, and calculation formula type, and clarify the category of each word.
8. Core Algorithmic Rules
8.1 Sensitive Data Identification: Import the original dataset into the sensitive data identification model. Based on the K-Nearest Neighbors (KNN) algorithm, the model retrieves and compares the data content with the sensitive word bank. When the identified content belongs to the preset sensitive data types (scoring standards, rule descriptions, operating addresses of detection rule systems, formula values, or calculation formulas), it is marked as sensitive data.
8.2 Sensitive Data Desensitization: Perform desensitization processing on the marked sensitive data:
- Detection rule system operating address type (IP:Port): Replace specific numeric segments with masks (e.g., http://172.**.***.***:****/...).
- Scoring standard type, rule description type, formula value type, calculation formula type: Perform content masking or generalization processing according to security policies (e.g., mask specific values, thresholds or logical details) to ensure that the core rule logic structure is retained while sensitive details are invisible.
The desensitization results are recorded in the desensitized dataset field, and the corresponding sensitive data type is marked at the same time.
8.3 Model Iteration: Continuously add newly identified sensitive data and their desensitization results to the training set to optimize the accuracy of the sensitive data identification model.
9. Real Data Examples
Example: The original operating address of the detection rule system is http://172.16.102.117:5600/#/main/common/rule, which contains the specific operating address of the detection rule system. Once leaked, it will cause the loss of company resources. The sensitive data identification model marks and desensitizes the information of the detection rule system operating address type, and the desensitized attachment address is http://172.**.***.***:****/#/main/common/rule
提供机构:
国脉互联数字发展(浙江自贸区)有限公司
创建时间:
2025-07-31
搜集汇总
数据集介绍
背景与挑战
背景概述
该数据集包含626条数据质量检测规则,采用xlsx格式,每季度更新,专注于敏感词脱敏处理以确保数据隐私合规。它提供六大维度(如完整性、准确性)的质量评估,适用于企业和政府机构的数据质量提升,核心算法基于KNN进行敏感数据识别和脱敏,支持安全共享和高效治理。
以上内容由遇见数据集搜集并总结生成


