有没有相关的论文或文献参考?
这个数据集是基于什么背景创建的?
数据集的作者是谁?
能帮我联系到这个数据集的作者吗?
这个数据集如何下载?
本数据集源自雅意训练语料,精选了约100B数据,数据大小约为500GB。通过开源预训练数据,旨在推动中文预训练大模型开源社区的发展,并与合作伙伴共同构建雅意大模型生态。
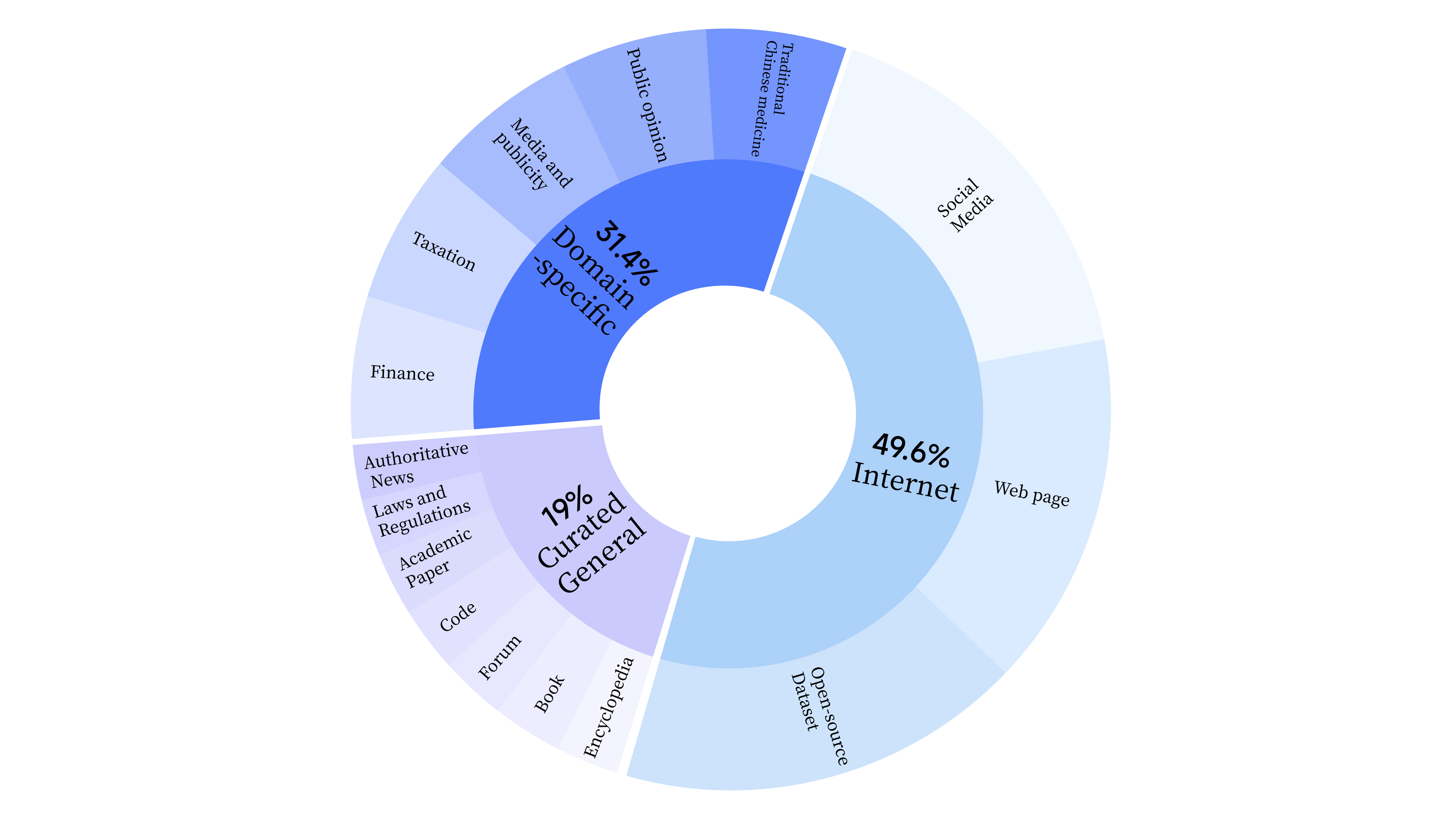
在预训练阶段,数据集不仅包含互联网数据,还添加了通用精选数据和领域数据,以增强模型的专业技能。通用精选数据涵盖报纸类数据、文献类数据、APP类数据、代码类数据、书籍类数据、百科类数据等。数据分布情况如下:
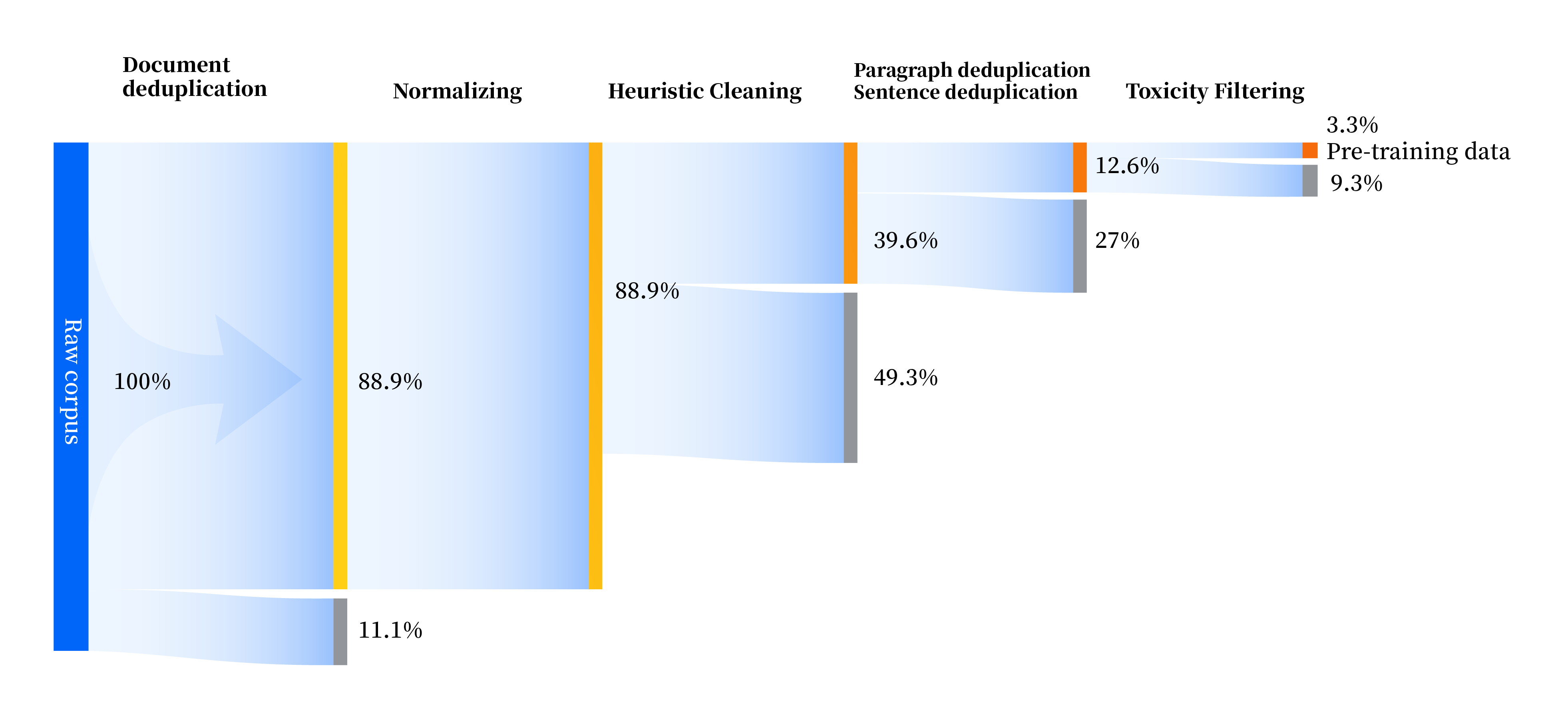
构建了一套全方位提升数据质量的数据处理流水线,包括标准化、启发式清洗、多级去重、毒性过滤四个模块。共收集了240TB原始数据,预处理后仅剩10.6TB高质量数据。数据处理流程如下:
本项目中的代码依照Apache-2.0协议开源。使用YAYI 2模型和数据需遵循雅意YAYI 2模型社区许可协议。若用于商业用途,需申请商用许可并遵循相关限制。
如使用本数据集,请引用以下论文:
@article{YAYI 2, author = {Yin Luo, Qingchao Kong, Nan Xu, et.al.}, title = {YAYI 2: Multilingual Open Source Large Language Models}, journal = {arXiv preprint arXiv:2312.14862}, url = {https://arxiv.org/abs/2312.14862}, year = {2023} }
CosyVoice 2
CosyVoice 2是由阿里巴巴集团开发的多语言语音合成数据集,旨在通过大规模多语言数据集训练,实现高质量的流式语音合成。数据集通过有限标量量化技术改进语音令牌的利用率,并结合预训练的大型语言模型作为骨干,支持流式和非流式合成。数据集的创建过程包括文本令牌化、监督语义语音令牌化、统一文本-语音语言模型和块感知流匹配模型等步骤。该数据集主要应用于语音合成领域,旨在解决高延迟和低自然度的问题,提供接近人类水平的语音合成质量。
arXiv 收录
Tropicos
Tropicos是一个全球植物名称数据库,包含超过130万种植物的名称、分类信息、分布数据、图像和参考文献。该数据库由密苏里植物园维护,旨在为植物学家、生态学家和相关领域的研究人员提供全面的植物信息。
www.tropicos.org 收录
MedDialog
MedDialog数据集(中文)包含了医生和患者之间的对话(中文)。它有110万个对话和400万个话语。数据还在不断增长,会有更多的对话加入。原始对话来自好大夫网。
github 收录
网易云音乐数据集
该数据集包含了网易云音乐平台上的歌手信息、歌曲信息和歌单信息,数据通过爬虫技术获取并整理成CSV格式,用于音乐数据挖掘和推荐系统构建。
github 收录
中国1km分辨率逐月NDVI数据集(2001-2023年)
中国1km分辨率逐月NDVI数据集(2001-2023年)根据MODIS MOD13A2数据进行月度最大值合成、镶嵌和裁剪后制作而成,包含多个TIF文件,每个TIF文件对应该月最大值NDVI数据,文件以时间命名。数据值域改为-0.2~1,不再需要除以一万,另外范围扩大到中国及周边地区,可以自行裁剪。数据分为两个文件夹,MVC文件夹中为MOD13A2 NDVI逐月最大值合成结果,mod1k_SGfilter为MVC中数据S-G滤波后的结果。
国家地球系统科学数据中心 收录